java根据URL获取网页编码
由于很多原因,我们要获取网页的编码(多半是写批量抓取的脚本吧...嘻嘻嘻)
注意:
如果你的目的是获取不乱码的网页内容(而不是根据网址发送post请求获取返回值),切记切记,移步这里
java根据URL获取HTML内容
先说思路:
有三种方法:
1,根据responseHeaders获取Content-Type里的charset,如下图
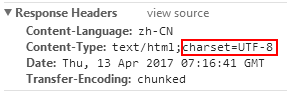
这种方法最好,最推荐,然而,很多网站都没有,要么是像百度这样:
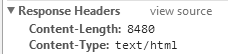
有Content-Type,然而没有指定charset
要么是像博客园这样:

???Content-Type都不给我么...???

所以虽然这种方法最准确.但是...并不是每个网站都有的...
2.根据html标签里的meta取
这里还以百度为例:

怎么取标签,我就不说了,如果不会就留言,如有需要我再写博客(然而也没什么人看我博客,更没什么人会留言...悲伤...我就默认你们都会取了)
虽然中文乱码,但是英文是不乱的,哪怕你不知道编码,随便用个GBK,UTF-8都能取...
但是,这种方法不准...不保证一定能取到正确的
并且..由于这种方法你还得拿到HTML内容...所以,还得判断一下是不是GZIP方式压缩了...贼麻烦...所以我就放弃了
3.通过第三方库,去猜格式
这种方法,原则上讲是存在一定的猜错几率的...
原理是同时进行多种编码的尝试(gb2312啊,utf-8啊,windows-XXXX啊),哪个先返回正确的格式就认定是哪个...虽然根据我的尝试很准,然而理论上还是会不贴切的,没有第一种准.
文件下载:http://files.cnblogs.com/files/blog5277/cpdetector_1.0.10_binary.zip
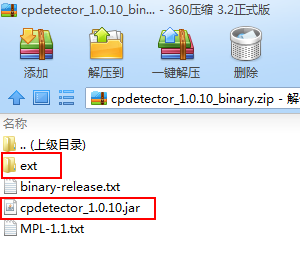
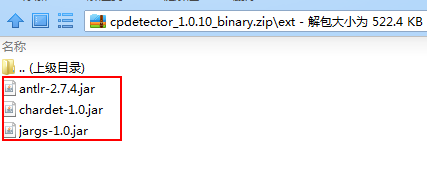
切记切记,总共是4个jar包...别的教程里并没有告诉我,害得我分别去找这三个编码jar包,好气...最后才发现原来就在这个压缩包里...吃了眼瞎的亏了
这四个jar包放进你项目里就行
最后,经过慎重的考虑与取舍,我决定先用第一种方法取(毕竟最准确),放弃第二种方法(贼麻烦...),第一种取不到了,再用第三种猜,如下
public static String getUrlCharset(String url){
try {
String urlNameString = url;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map<String, List<String>> map = connection.getHeaderFields();
// 遍历所有的响应头字段
System.out.println("Content-Type" + "--->" + map.get("Content-Type"));
List<String> list=map.get("Content-Type");
if (list.size()>0){
String contentType=list.toString().toUpperCase();
if (contentType.contains("UTF-8")){
return "UTF-8";
}
if(contentType.contains("GB2312")){
return "GB2312";
}
if (contentType.contains("GBK")){
return "GBK";
}
}
//如果相应头里面没有编码格式,用下面这种
CodepageDetectorProxy codepageDetectorProxy = CodepageDetectorProxy.getInstance();
codepageDetectorProxy.add(JChardetFacade.getInstance());
codepageDetectorProxy.add(ASCIIDetector.getInstance());
codepageDetectorProxy.add(UnicodeDetector.getInstance());
codepageDetectorProxy.add(new ParsingDetector(false));
codepageDetectorProxy.add(new ByteOrderMarkDetector());
Charset charset = codepageDetectorProxy.detectCodepage(new URL(url));
return charset.name();
}catch (Exception e){}
return null;
}
如果返回值是null,那很不幸,我也不知道哪里出异常了,自己debug解决吧,嘻嘻.一般是没事.最多就是网络不好timeout了
就这样
java根据URL获取网页编码的更多相关文章
- java根据URL获取HTML内容
之前我写脚本,是想获取HTML内容的. 但是呢...一方面编码困扰着我,于是我写了这个: java根据URL获取网页编码 然后呢,每个网站是不是GZIP还得判断,贼麻烦... 但是没办法啊,麻烦也得写 ...
- Java 网络爬虫获取网页源代码原理及实现
Java 网络爬虫获取网页源代码原理及实现 1.网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL ...
- Java从URL获取PDF内容
Java直接URL获取PDF内容 题外话 网上很多Java通过pdf转 HTML,转文本的,可是通过URL直接获取PDF内容,缺没有,浪费时间,本人最近工作中刚好用到,花了时间整理下,分享出来,防止浪 ...
- java根据url获取json对象
package test; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; ...
- 【真相揭秘】requests获取网页编码乱码本质
有没有被网页编码抓狂,怎么转都是乱码. 通过查看requests源代码,才发现是库本身历史原因造成的. 作者是严格http协议标准写这个库的,<HTTP权威指南>里第16章国际化里提到,如 ...
- java爬虫HttpURLConnect获取网页源码
public abstract class HttpsURLConnection extends HttpURLConnection HttpsURLConnection 扩展 HttpURLConn ...
- asp.net 利用HttpWebRequest自动获取网页编码并获取网页源代码
/// <summary> /// 获取源代码 /// </summary> /// <param name="url"></param& ...
- python获取网页编码问题(encoding和apparent_encoding)
在requests获取网页的编码格式时,有两种方式,而结果也不同,通常用apparent_encoding更合适 注:推荐一个大佬写的关于获取网页编码格式以及requests中text()和conte ...
- LAMP环境下,通过网页url获取gb2312编码中文命名的下载资源方法
最近有个功能, 要求获取中文命名的.zip压缩文件,我准备直接采用网页url填写压缩文件地址的方式获取下载资源, 但问题是 我们的linux系统和php编程环境都是采用的zh_GB2312编码, 而浏 ...
随机推荐
- Vuejs vm对象详解
Vuejs vm对象详解 vue数据是怎么驱动视图的?一堆数据放在那里是不会有任何作用的,它必须通过我们的View Model(视图模型)才能操控视图. 图中的model其实就是数据,一般我们写成js ...
- js获取浏览器信息
function message() { txt = "<p>浏览器代码名: " + navigator.appCodeName + "</p>& ...
- 将表单序列化为JSON对象
将表单序列化为JSON对象的工具方法: $(function() { //工具方法,可以将指定的表单中的输入项目序列化为JSON数据 $.fn.serializeJson = function() { ...
- pat 团体赛练习题集 L2-008. 最长对称子串
对给定的字符串,本题要求你输出最长对称子串的长度.例如,给定"Is PAT&TAP symmetric?",最长对称子串为"s PAT&TAP s&quo ...
- Git 常用命令列表
1 常用 $ git remote add origin git@github.com:yeszao/dofiler.git # 配置远程git版本库 $ git pull origin master ...
- Python建立多线程任务并获取每个线程返回值
1.进程和线程 (1)进程是一个执行中的程序.每个进程都拥有自己的地址空间.内存.数据栈以及其他用于跟踪执行的辅助数据.进程也可以派生新的进程来执行其他任务,不过每个新进程都拥有自己的内存和数据栈,所 ...
- Python3 自定义请求头消息headers
Python3 自定义请求头消息headers 使用python爬虫爬取数据的时候,经常会遇到一些网站的反爬虫措施,一般就是针对于headers中的User-Agent,如果没有对headers进行设 ...
- win7改装 CentOS7,装完后开机,没有引导
本来系统是win7,安装centos是用U盘启动安装方式安装成功后,发现win7的系统引导不见了.之前用的是centos6.4安装后依然保留win7引导的,到centos7就不行了 解决方法1.使用r ...
- win7 powershell配色方案
首先我是参考微软的word的, look~ Windows PowerShell 配置文件 要配置powershell很简单, 就几步 1.显示 Windows PowerShell 配置文件的路径 ...
- nagios监控oracle 表空间
oracle表空间满的危害以及处理方式见我的博客链接https://www.cnblogs.com/-abm/p/9764803.html 除此之外我们还需要对表空间实时监控,这样就可以及时了解表空间 ...