吴裕雄--天生自然python学习笔记:网页解析
抓取万水书苑网页中所有<a>标签中的超链接井显示。
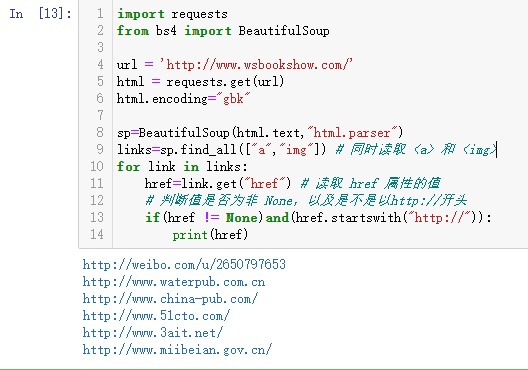
import requests
from bs4 import BeautifulSoup url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="gbk" sp=BeautifulSoup(html.text,"html.parser")
links=sp.find_all(["a","img"]) # 同时读取 <a> 和 <img>
for link in links:
href=link.get("href") # 读取 href 属性的值
# 判断值是否为非 None,以及是不是以http://开头
if(href != None)and(href.startswith("http://")):
print(href)
吴裕雄--天生自然python学习笔记:网页解析的更多相关文章
- 吴裕雄--天生自然python学习笔记:python爬虫与网页分析
我们所抓取的网页源代码一般都是 HTML 格式的文件,只要研究明白 HTML 中 的标签( Tag )结构,就很容易进行解析并取得所需数据 . HTML 网页结构 HTML 网 页是由许多标签( Ta ...
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
- 吴裕雄--天生自然python学习笔记:Python3 网络编程
Python 提供了两个级别访问的网络服务.: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法. 高级别的网络 ...
- 吴裕雄--天生自然python学习笔记:python用 Bokeh 模块绘制我国 GDP 数据统计图
现在我们把我国 1990 年到 2017 年的 GDP 数据抓取出 来,井用 Bokeh 绘 出散点统计图 . 由网页爬取所需数据,并用 Bokeh 绘制散点图 . import requests # ...
- 吴裕雄--天生自然python学习笔记:爬取我国 1990 年到 2017年 GDP 数据并绘图显示
绘制图形所需的数据源通常是不固定的,比如,有时我们会需要从网页抓取, 也可能需从文件或数据库中获取. 利用抓取网页数据技术,把我国 1990 年到 2016 年的 GDP 数据抓取出来 ,再利用 Ma ...
- 吴裕雄--天生自然python学习笔记:Python3 XML 解析
什么是 XML? XML 指可扩展标记语言(eXtensible Markup Language),标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言. XML 被设计用来传输和存 ...
- 吴裕雄--天生自然python学习笔记:Beautiful Soup 4.2.0模块
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
- 吴裕雄--天生自然python学习笔记:python实现自动网页测试
Python 可实现的网页测试的功能十分强大,甚至能通 过编程来实现让绝大多数的测试过程自动化. 这对很多开 发者来说,绝对是不可多得的神器. hash lib 纽件可以判别文件是否有过更改,只需要用 ...
- 吴裕雄--天生自然python学习笔记:pandas模块强大的数据处理套件
用 Python 进行数据分析处理,其中最炫酷的就属 Pa ndas 套件了 . 比如,如果我 们通过 Requests 及 Beautifulsoup 来抓取网页中的表格数据 , 需要进行较复 杂的 ...
随机推荐
- 腾讯一shell试题.
腾讯一shell试题. 假设qq.tel文件内容: 12334:13510014336 12345:12334555666 12334:12343453453 12099:13598989899 12 ...
- 洛谷P4071-[SDOI2016]排列计数 题解
SDOI2016-排列计数 发现很多题解都没有讲清楚这道题为什么要用逆元.递推公式怎么来的. 我,风雨兼程三十载,只为写出一篇好题解. 还是我来造福大家一下吧. 题目大意: 一个长度为 n 且 1~n ...
- str_replace用法
语法 str_replace(find,replace,string,count) 参数 描述 find 必需.规定要查找的值. replace 必需.规定替换 find 中的值的值. string ...
- ubuntu18.04国内软件源
ubuntu默认的软件源是国外的,下载软件很慢,需要更新为国内的源以提升速度,现在可以通过ubunt software来设置了,不过还是习惯了命令行修改的方式. 更新方法 123 sudo vi /e ...
- unity学习 5.x依赖打包和解包
unity5已经封装好了接口,所以依赖打包并没有那么神秘和复杂了. 打包: 1.定义好资源的assetBundleName 2.BuildPipeline.BuildAssetBundles,指定资源 ...
- Python—使用列表构造栈数据结构
class Stack(object): """ 使用列表实现栈 """ def __init__(self): self.stack = ...
- MySQL--MySQL分区
参考:http://bbs.51cto.com/thread-1080714-1.html MySQL 从5.1 版本开始支持分区的功能.分区是指根据一定的规则,数据库把一个表分解成多个更小的.更容易 ...
- ios 监控键盘状态
增加键盘显示和隐藏事件监听 NotificationCenter.default.addObserver(self, selector: #selector(keyboardWillShow(noti ...
- C盘满了解决办法之查看文件夹占用的统计界面
TreeSize Free软件,可以实时查看文件夹使用情况: 百度搜索: 下载安装完以后的显示界面如下:
- 两个tomcat使用同一个jvm可能会出错
如果两个tomcat中的项目的某些类具有完全相同的包路径和类名的话,jvm可能会“弄混”这两个类,所以一般要求包名“必须”唯一. 当然,如果两个类中的代码和import的类完全一样,弄混了也就弄混了, ...