HDFS文件系统基操--Java实现
Java实现对HDFS文件系统的基本操作
1.准备好jar包

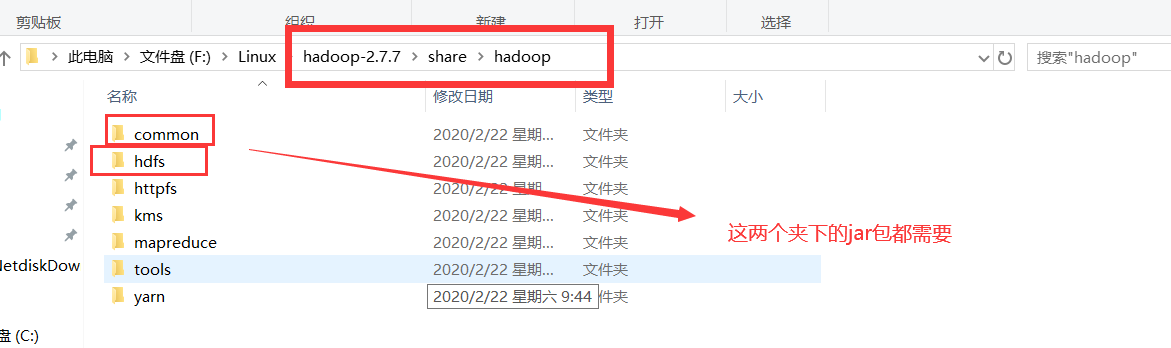
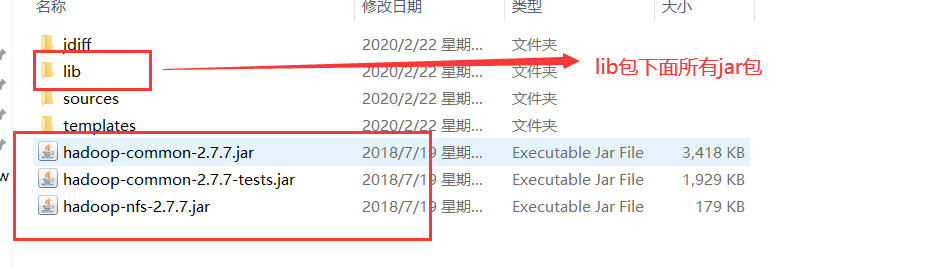
2.创建一个类
1. 测试连接
@Test //测试是否连接成功
public void test() {
//添加配置 ==> core-site.xml
Configuration conf = new Configuration();
//配置默认地址端口
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
//加载配置
FileSystem fs = FileSystem.get(conf);
//获取目标状态 注意:要用绝对路径,且路径都要用Path包起来
FileStatus fst = fs.getFileStatus(new Path("/hello"));
System.out.println(fst.isDirectory()); //是否是文件夹
System.out.println(fst.isFile()); // 是否是文件
System.out.println(fst.getLen()); // 获取长度
System.out.println(fst.getPath()); // 获取路径
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
2. 在文件系统下创建文件夹
@Test //hdfs文件系统中创建文件夹
public void mkdirsFile() {
//添加配置 ==> core-site.xml
Configuration conf = new Configuration();
//配置默认地址端口
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
//加载配置
FileSystem fs = FileSystem.get(conf);
//创建文件夹 注意:要用绝对路径,且路径都要用Path包起来
boolean mkdirs = fs.mkdirs(new Path("/other/test/jdk"));
System.out.print(mkdirs);
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试时,发现出错了,用户Administator在hadoop上执行写操作时被权限系统拒绝,百度(https://blog.csdn.net/xiaoshunzi111/article/details/52062640)发现,解决有三个办法:
1、在hdfs的配置文件中,将dfs.permissions修改为False
2、执行这样的操作 hadoop fs -chmod 777 /user/hadoop
3、在系统的环境变量里面添加HADOOP_USER_NAME=root(HDFS上的有权限的用户,具体看自己的情况),插入代码实现 System.setProperty("HADOOP_USER_NAME", "root");
前两个不太安全,我选用第三个,重启就可以。
3.递归查看文件夹
@Test //hdfs文件系统中遍历文件夹
public void ls() {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
FileStatus[] fls = fs.listStatus(new Path("/"));
for(FileStatus fst:fls) {
judge(fs,fst);
}
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public void judge(FileSystem fs,FileStatus fst) {
String name = fst.getPath().toString().split("hdfs://192.168.1.105:9000/")[1];
if(fst.isDirectory()) {
System.out.println("d: "+name);
try {
FileStatus[] fls = fs.listStatus(new Path("/"+name));
for(FileStatus fst2:fls) {
judge(fs,fst2);
}
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}else {
System.out.println("f: "+name);
}
}

4.上传
@Test //上传文件到hdfs文件系统 通过io流
public void rz() {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
//输出流
FSDataOutputStream create = fs.create(new Path("/other/hadoop-2.7.7.tar.gz"));
//输入流
FileInputStream fis = new FileInputStream(new File("F:\\Linux\\hadoop-2.7.7.tar.gz"));
int len = 0;
//定义一个byte类型的数组,数组的大小表示每次从文件中读取出来的数据量
byte[] b = new byte[1024];
//循环读取数据,如果fis.read没有读到就数据返回-1
while((len = fis.read(b))!=-1) {
//输入到输出
create.write(b, 0, len);
}
fis.close();
create.close();
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test //上传文件到hdfs文件系统 通过核心类FileSystem提供的方法
public void rz1() {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
//前为需要上传的文件地址,后为hdfs存放地址
fs.copyFromLocalFile(new Path("F:\\Linux\\hadoop-2.7.7.tar.gz"), new Path("/other/hadoop-2.7.7.tar.gz"));
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
5.下载
@Test //下载到本地 通过io流
public void sz() {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
FSDataInputStream create = fs.open(new Path("/other/hadoop-2.7.7.tar.gz"));
FileOutputStream fis = new FileOutputStream(new File("F:\\hadoop-2.7.7.tar.gz"));
int len = 0;
byte[] b = new byte[1024];
while((len = create.read(b))!=-1) {
fis.write(b, 0, len);
}
fis.close();
create.close();
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test //下载到本地 通过核心类FileSystem提供的方法
public void sz1() {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
//前为hdfs中的文件,后为存放地址
fs.copyToLocalFile(new Path("/other/hadoop-2.7.7.tar.gz"),new Path("F:\\hadoop-2.7.7.tar.gz"));
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
6.重命名
@Test //重命名
public void rename() {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
//前为原名,后为修改名
boolean rename = fs.rename(new Path("hello"), new Path("hello01"));
System.out.println(rename);
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}HDFS文件系统基操--Java实现的更多相关文章
- hadoop学习(三)HDFS常用命令以及java操作HDFS
一.HDFS的常用命令 1.查看根目录下的信息:./hadoop dfs -ls 2.查看根目录下的in目录中的内容:./hadoop dfs -ls in或者./hadoop dfs -ls ./i ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- HDFS的java接口——简化HDFS文件系统操作
今天闲来无事,于是把HDFS的基本操作用java写出简化程序出来给大家一些小小帮助! package com.quanttech; import org.apache.hadoop.conf.Conf ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- HDFS文件系统基本文件命令、编程读写HDFS
基本文件命令: 格式为:hadoop fs -cmd <args> cmd的命名通常与unix对应的命令名相同.例如,文件列表命令: hadoop fs -ls 1.添加目录和文件 HDF ...
- HDFS文件系统的JAVA-API操作(一)
使用java.net.URL访问HDFS文件系统 HDFS的API使用说明: 1.如果要访问HDFS,HDFS客户端必须有一份HDFS的配置文件 也就是hdfs-site.xml,从而读取Nameno ...
- hdfs shell命令及java客户端编写
一. hdfs shell命令 可以通过hadoop fs 查看所有的shell命令及其用法. 传文件到hdfs: hadoop fs -put /home/koushengrui/Downloads ...
随机推荐
- 牛客-富豪凯匹配串(bitset)
题目传送门 sol1:用bitset来维护,其实感觉挺暴力的,不怎么会用bitset,借着这道题学习一下. bitset暴力维护 #include "bits/stdc++.h" ...
- redHat更新yum源
1. 网易镜像仓库查找相关rpm 包并下载 :http://mirrors.163.com/centos/6/os/x86_64/Packages/ wget http://mirrors.163.c ...
- 吴裕雄--天生自然 HADOOP大数据分布式处理:添加主机和服务器的域名映射
- ABB机器人故障处理指南
ABB工业机器人常见故障处理 1. 开机示教器显示如下 1) 如果机器人开机,示教器一直显示connecting to the robot controller,如上图(robotware版本是白 ...
- ZOJ-1167-Trees on the Level
题解: 我的解法是用一个类似字典树结构的结构体来表示节点.看到另一种解法是用数组来映射二叉树的,开到14000就过了,但是我觉得是数据水了,因为题中说最多 256个节点,如果256个节点连成链型,除根 ...
- Docker的部署安装(CentOS)
环境准备 操作系统需求 为兼容企业级应用,学习选用Centos7做为部署安装Docker的系统平台 # 通过以下命令可查看系统版本和内核版本等信息 cat /etc/redhat-release #- ...
- [LC] 17. Letter Combinations of a Phone Number
Given a string containing digits from 2-9 inclusive, return all possible letter combinations that th ...
- 吴裕雄--天生自然 R语言开发学习:功效分析(续一)
#----------------------------------------# # R in Action (2nd ed): Chapter 10 # # Power analysis # # ...
- ES7中的async和await
ES7中的async和await 在上一章中,使用Promise将原本的回调方式转换为链式操作,这就将一个个异步执行的操作串在一条同步线上了.下一次的操作必须等待当前操作的结束. 使用Promise的 ...
- 转:zabbix 更改maps图标
更改Zabbix map图标 Zabbix的maps用来图形化显示监控设备的拓扑图,并且以不同的标记显示故障事件,通过该图表很直观的显示设备的整体情况.系统默认的图标比较简陋,如图十一所示.通过更改系 ...