python爬取某站新闻,并分析最近新闻关键词
在爬取某站时并做简单分析时,遇到如下问题和大家分享,避免犯错:
一丶网站的path为 /info/1013/13930.htm ,其中13930为不同新闻的 ID 值,但是这个数虽然为升序,但是没有任何规律的升序。
解决办法:
使用 range 顺序爬取,错误的网站在页面会报如图错误:
这时我们首先去判断返回页面是否包含 str 'Sorry, Page Not Found',如果包含则跳过,不包含则爬取页面关键信息

二、在爬取过程中发现有其它页面,该内容已经被撤销,这时我正常去判断页面,并跳过,发现无法跳过
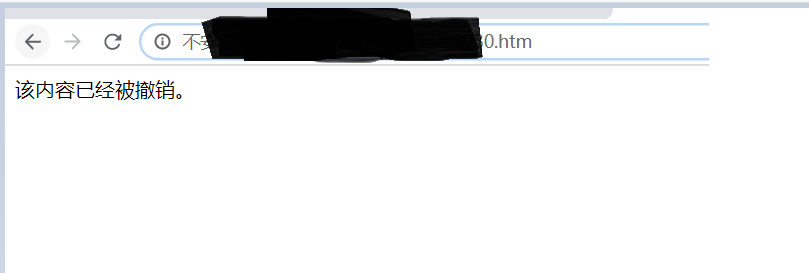

解决办法:
查看页面编码为:UTF-8
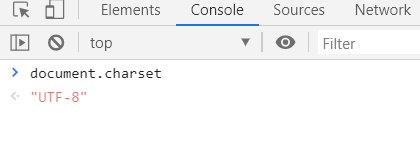
在用 if 判断页面是否存在 str 时,首先将页面内容进行UTF-8编码即可解决:
response.encoding = 'utf-8'
三、在爬取网站时,遇到了没有 text 的主页面,新闻全部为图片
解决办法:这时查看图片页面和新闻页面的不同
图片页面关键标签:

新闻页面关键标签:

发现div标签下的 ID 不同,这时我们就跳过 id = 'vsb_content' 即可,在跳过时,判断页面内容应当先判断 id = 'vsb_content_4' ,因为 vsb_content_4 包含了 vsb_content
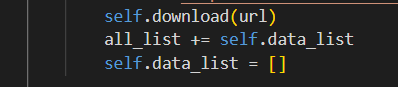
四、在爬取新闻后,将新闻写入csv文件时出现BUG,文件内容有重复
解决办法:
在写入文件的列表写入后将列表清空,因为在循环执行跳过不存在页面时会有空隙,这时的data_list里面是有内容的
五、在写入csv文件后,新闻文本乱码
解决办法:使用utf-8-sig编码
为什么不用utf-8?
原因如下:
1、”utf-8“ 是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,
因此它不需要BOM,所以当用"utf-8"编码方式读取带有BOM的文件时,它会把BOM当做是文件内容来处理, 也就会发生类似上边的错误.
2、“uft-8-sig"中sig全拼为 signature 也就是"带有签名的utf-8”,
因此"utf-8-sig"读取带有BOM的"utf-8文件时"会把BOM单独处理,与文本内容隔离开,也是我们期望的结果.
最终代码:
#!/user/bin/env python
# -*- coding:utf-8 -*-
# Author: Mr.riy import re
import requests
import csv
import time
import jieba
import jieba.analyse
from requests.exceptions import RequestException
from bs4 import BeautifulSoup class Downloader:
def __init__(self):
self.data_list = [] def download(self, url, num_retries=3):
'判断页面'
print('Downloading:', url)
global response
response = requests.get(url)
response.encoding='utf-8'
try:
if 'Sorry, Page Not Found' in response.text:
print(url, '页面不存在')
elif '该内容已经被撤销' in response.text:
print(url, '页面不存在')
elif response.status_code == 200:
print('下载成功,开始执行......')
# print(response.text)
# print(response.encoding)
page = response.content
self.find_all(page)
time.sleep(1)
else:
if num_retries > 0 and 500 <= response.status_code <= 600:
html = self.download(url, num_retries-1)
except RequestException as e:
print(e) def find_all(self, page):
'爬取内容'
soup_title = BeautifulSoup(page, 'lxml')
sp_title_items = soup_title.find('h2', attrs={'align': 'center'})
title = sp_title_items.text
print(title) sp_time_items = soup_title.find('div', attrs={'style': 'line-height:400%;color:#444444;font-size:14px'})
times = sp_time_items.text
# print(times)
time = re.findall(r'\d{4}年\d{2}月\d{2}日 \d{2}:\d{2}', times)
# print(time)
author = re.findall(r'作者:(.*)', times)
# print(author)
global response
if 'vsb_content_4' in response.text:
sp_words_items = soup_title.find('div', attrs={'id': 'vsb_content_4'})
elif 'vsb_content_501' in response.text:
sp_words_items = soup_title.find('div', attrs={'id': 'vsb_content_501'})
else:
sp_words_items = soup_title.find('div', attrs={'id': 'vsb_content'}) words = sp_words_items.text
# print(words)
row = []
row.append(time)
row.append(author)
row.append(words)
self.data_list.append(row) def write_csv(self, filename, all_list):
'写入csv文件'
with open(filename, 'w', encoding="utf-8-sig", newline='') as f:
writer = csv.writer(f)
fields = ('时间', '作者', '内容')
writer.writerow(fields)
for row in all_list:
writer.writerow(row) def fetch_data(self):
'设置爬取页面'
all_list = []
for page in range(13795, 14000, 1): #设置爬取的页面范围
url = f'http://www.xxxxxx.cn/info/1013/{page}.htm'
self.download(url)
all_list += self.data_list
self.data_list = [] self.write_csv('data.csv', all_list) class analyze:
def get_all_text(self, filename):
'取出所有评价的句子'
comment_list = []
with open(filename, encoding="utf-8-sig") as f:
rows = csv.reader(f)
for row in rows:
one_comment = row[-1]
comment_list.append(one_comment) return ''.join(comment_list[1:]) def cut_text(self, all_text):
'找到评价中重要关键词'
jieba.analyse.set_stop_words('stop_words.txt')
text_tags = jieba.analyse.extract_tags(all_text, topK=30)
return text_tags def main():
temp = Downloader()
temp.fetch_data()
b = analyze()
all_text = b.get_all_text('data.csv')
text_tags = b.cut_text(all_text)
print(text_tags) if __name__ == "__main__":
main()
运行截图:最近新闻出现最多的关键字为:防疫,疫情,工作

python爬取某站新闻,并分析最近新闻关键词的更多相关文章
- python爬取B站视频弹幕分析并制作词云
1.分析网页 视频地址: www.bilibili.com/video/BV19E… 本身博主同时也是一名up主,虽然已经断更好久了,但是不妨碍我爬取弹幕信息来分析呀. 这次我选取的是自己 唯一的爆款 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- 用python爬取B站在线用户人数
最近在自学Python爬虫,所以想练一下手,用python来爬取B站在线人数,应该可以拿来小小分析一下 设计思路 首先查看网页源代码,找到相应的html,然后利用各种工具(BeautifulSoup或 ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- python爬取b站排行榜
爬取b站排行榜并存到mysql中 目的 b站是我平时看得最多的一个网站,最近接到了一个爬虫的课设.首先要选择一个网站,并对其进行爬取,最后将该网站的数据存储并使其可视化. 网站的结构 目标网站:bil ...
- Python爬取b站任意up主所有视频弹幕
爬取b站弹幕并不困难.要得到up主所有视频弹幕,我们首先进入up主视频页面,即https://space.bilibili.com/id号/video这个页面.按F12打开开发者菜单,刷新一下,在ne ...
随机推荐
- 录音文件lame转换MP3相关配置
文件下载整个功能完成了,那么对应的文件上传也跑不了.So~ Look here~ 业务需求是录制音频然后上传到七牛并且Android可以读. 与安卓沟通了一下统一了mp3格式,大小质量都不错.由于AV ...
- 【转载】ArcGIS中的WKID
原出处:http://www.cnblogs.com/liweis/p/5951032.html 提到坐标系统,大家多少能明白一些,但在运用时,有些朋友搞得不是非常清楚,以后专门来总结.在实地生产项目 ...
- 由uploadfive看servlet
一.uploadfive的使用 上传工具是程序设计中最常用的功能,其中,uploadfive插件使用比较多,此处该插件进行文件的上传操作.该插件是基于HTML5的,因此PC端和移动端都可以使用. 使用 ...
- 安卓权威编程指南 挑战练习:实现高效RecyclerView刷新
Adapter的notifyDataSetChanged方法会通知RecyclerView刷新全部的可见列表项. 在CriminalIntent应用里,这个方法不够高效,我们知道,返回CrimeLis ...
- 阿里云https免费证书配置-包教会
阿里云https免费证书配置-包教会-有需要请联系小编! 小编个人站点:https://www.itdog.site/ 小编微信号:wvqusrtg
- Windows Server 2012搭建SQL Server Always On踩坑全记录
Windows Server 2012搭建SQL Server Always On踩坑全记录 环境信息: Windows Server 2012 R2 Sql Server 2012 整个搭建集群的过 ...
- js获取当前日期是一年中的第几天
js获取当前日期为一年中的第几天 const currentYear = new Date().getFullYear().toString(); // 今天减今年的第一天(xxxx年01月01日) ...
- python数据分析工具 | pandas
pandas是python下强大的数据分析和探索工具,是的python在处理数据时非常快速.简单.它是构建在numpy之上的,包含丰富的数据处理函数,支持时间序列分析功能,支持灵活处理缺失数据. pa ...
- springboot1.5.9整合websocket实现实时显示的小demo
最近由于项目需要实时显示数据库更新的数据变化情况,一开始想过在前端使用ajax异步轮询方法实现,但后面考虑到性能和流量等要求,就放弃该方法而选择使用websocket(毕竟现在springboot整合 ...
- 关于nw的简单应用
最近使用到了桌面开发应用nw.js.进行简单的介绍一下,基本用法 nwjs实际上是基于node js的,支持node js的所有api 中文官网https://nwjs.org.cn/ 第一步.在官网 ...