用python爬取B站在线用户人数
最近在自学Python爬虫,所以想练一下手,用python来爬取B站在线人数,应该可以拿来小小分析一下
设计思路
首先查看网页源代码,找到相应的html,然后利用各种工具(BeautifulSoup或者直接正则表达式)得到数据, 然后把数据和当且时间保存到本地,并且设置一定的时间间隔,反复得到数据, 不过后面我发现B站在线人数是通过js动态生成的,后面会提到
实现过程
观察HTML网页
打开B站,查看网页源代码

我们发现
<div class="online">
<a href="//www.bilibili.com/video/online.html" target="_blank" title="在线观看:4285260">
在线人数:3277944
</a>
<a href="//www.bilibili.com/newlist.html" target="_blank">
最新投稿:32678
</a>
</div>在线人数是存储在类名为online的div中的a标签,当得到a标签的内容,然后把数字分割出来就可以
提取信息
提取代码片段如下:
url = "https://www.bilibili.com/"
html = get_page_source(url)
#得到网页的string
soup = BeautifulSoup(html, 'html.parser')
viewInfo = soup.find_all('div', attrs={'class': 'online'})[0]
#找到相应div
numberStr = viewInfo.a.string
#提取标签a的内容
number = str(numberStr.split(':')[1])
#把得到的字符串按照":"来分割所以数字就分到标为1的位置 提取出来就可以然后发现 我们每次得到的number都为0,这显然是有问题的。
问题的关键在于B站在线人数的数据是动态生成的,这是一个动态的网页,这个数字是通过js代码填进去的,所以我们每次得到的是没经过js处理的HTML,所以需要另外的解决方法
解决问题
这里我们在network里查找关键词online可以找到相应的的api
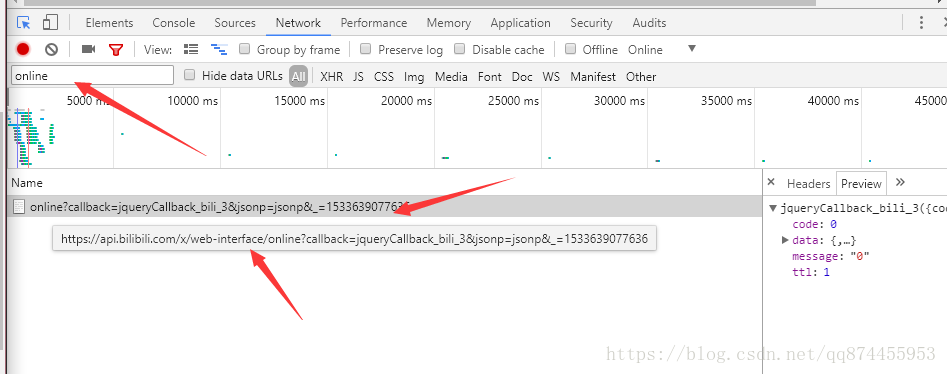
https://api.bilibili.com/x/web-interface/online?callback=jqueryCallback_bili_3&jsonp=jsonp&_=1533639077636
但是打开网址是找不到的, 主要因为我的url是有问题的 把后面的参数去掉就可以访问
得到最后的api网址
https://api.bilibili.com/x/web-interface/online
所以后面我们只需要用python解析json, 得到web_online的值就可以了
代码片段如下
url = "https://api.bilibili.com/x/web-interface/online"
html = get_page_source(url)
#获得url的
json_data = json.loads(html)
#解析json
number = (json_data['data']['web_online'])
#得到值把结果写到txt 以做研究
把当前时间 和 在线人数写到一起,以做研究
with open(fpath, 'a', encoding='utf-8') as f:
nowTime = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M'))
f.write(nowTime + " " + str(number) + '\n')全部代码
import requests
import re
import time
import datetime
from bs4 import BeautifulSoup
import traceback
import json
def get_page_source(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "failed"
def getViewInfo(url, fpath):
html = get_page_source(url)
try:
# soup = BeautifulSoup(html, 'html.parser')
# viewInfo = soup.find_all('div', attrs={'class': 'online'})[0]
# viewInfo = soup.find_all('div', attrs={'class':'ebox'})[0]
# title = viewInfo.p.string
# print(title)
# numberStr = viewInfo.a.string
# number = numberStr.split(':')[1]
#print(number)
#使用python来解析json
json_data = json.loads(html)
number = (json_data['data']['web_online'])
#保存文件
with open(fpath, 'a', encoding='utf-8') as f:
nowTime = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M'))
f.write(nowTime + " " + str(number) + '\n')
except:
traceback.print_exc()
def main():
count = 0
while 1:
url = "https://api.bilibili.com/x/web-interface/online"
#文件路径
output_path = "G://bilibiliInfo.txt"
getViewInfo(url, output_path)
#打印进度
count = count + 1
print(count)
#延时一分钟
time.sleep(60)
if __name__=="__main__":
main()
小结
最终可以把此程序 放到服务器上(毕竟电脑也不能总是开着的)
当然在服务器 实现定时运行可以通过crontab 来实现,然后把代码的循环改一下,就能实时监控了!
关于如何在服务器定时运行python可以看这篇博客,还是减少了很多错误的
https://blog.csdn.net/qq874455953/article/details/81586508
这是每隔30分钟的结果部分显示, 仅供参考
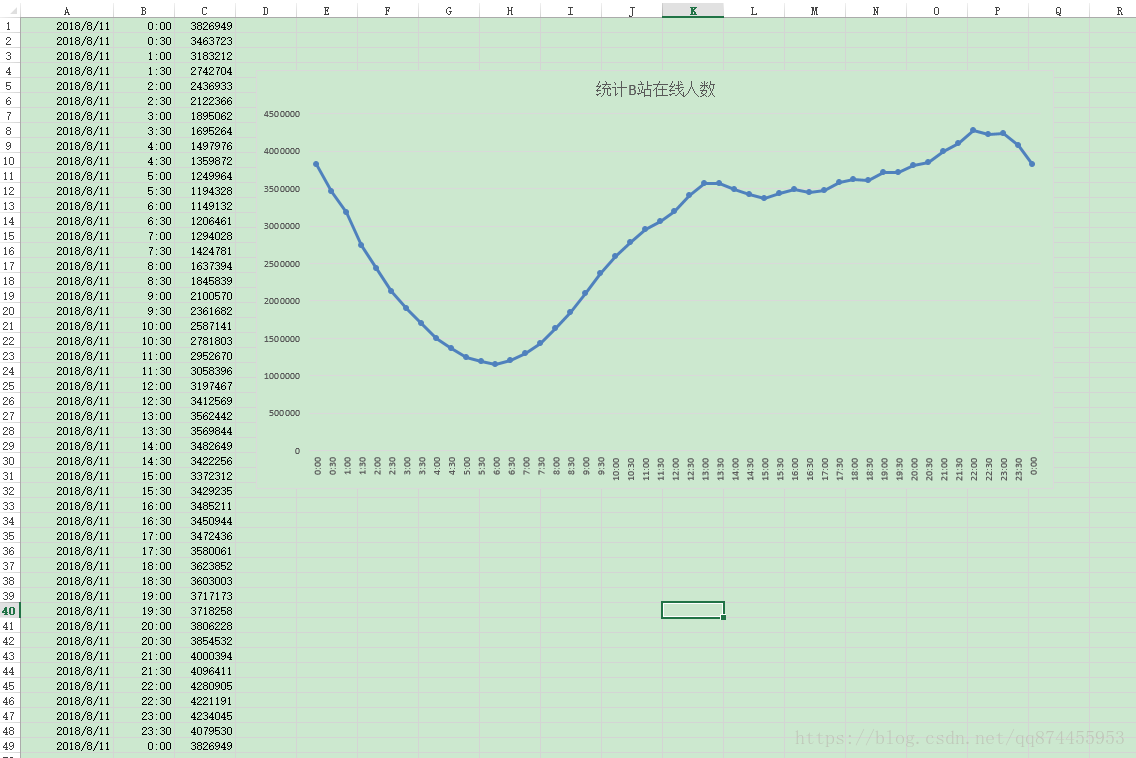
折线图
用python爬取B站在线用户人数的更多相关文章
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- python爬取某站新闻,并分析最近新闻关键词
在爬取某站时并做简单分析时,遇到如下问题和大家分享,避免犯错: 一丶网站的path为 /info/1013/13930.htm ,其中13930为不同新闻的 ID 值,但是这个数虽然为升序,但是没有任 ...
- python爬取b站排行榜
爬取b站排行榜并存到mysql中 目的 b站是我平时看得最多的一个网站,最近接到了一个爬虫的课设.首先要选择一个网站,并对其进行爬取,最后将该网站的数据存储并使其可视化. 网站的结构 目标网站:bil ...
- Python爬取b站任意up主所有视频弹幕
爬取b站弹幕并不困难.要得到up主所有视频弹幕,我们首先进入up主视频页面,即https://space.bilibili.com/id号/video这个页面.按F12打开开发者菜单,刷新一下,在ne ...
- Python爬取B站耗子尾汁、不讲武德出处的视频弹幕
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前言 耗子喂汁是什么意思什么梗呢?可能很多人不知道,这个梗是出自马保国,经常上网的人可能听说过这个 ...
- 使用python爬取P站图片
刚开学时有一段时间周末没事,于是经常在P站的特辑里收图,但是P站加载图片的速度比较感人,觉得自己身为计算机专业,怎么可以做一张张图慢慢下这么low的事,而且这样效率的确也太低了,于是就想写个程序来帮我 ...
- python爬取B站视频弹幕分析并制作词云
1.分析网页 视频地址: www.bilibili.com/video/BV19E… 本身博主同时也是一名up主,虽然已经断更好久了,但是不妨碍我爬取弹幕信息来分析呀. 这次我选取的是自己 唯一的爆款 ...
随机推荐
- three.js 将图片马赛克化
这篇郭先生来说说BufferGeometry,类型化数组和粒子系统的使用,并且让图片有马赛克效果(同理可以让不清晰的图片清晰化),如图所示.在线案例点击博客原文 1. 解析图片 解析图片和上一篇一样 ...
- react实战 : react 与 svg
有一个需求是这样的. 一个组件里若干个区块.区块数量不定. 区块里面是一个波浪效果组件,而这个一般用 SVG 做. 所以就变成了在 react 中使用 SVG 的问题. 首先是波浪效果需要的样式. . ...
- 修改ElementUI样式的几种方式
ElementUI是一款非常强大的前端UI组件库,它默认定义了很多美观的样式,但是我们在实际开发过程中不可避免地遇到需要修改ElementUI默认样式.下面总结了几种修改默认样式的方法. 1. 新建全 ...
- wpf中实现快捷键
<Window.InputBindings> <KeyBinding Gesture="Ctrl+Alt+Q" Command="{Binding Yo ...
- 如何在Windows、Linux系统中安装Redis
一:Windos下安装Redis并设置自动启动 1.下载windows版本的Redis 去官网找了很久,发现原来在官网上可以下载的windows版本的,现在官网已经没有windows版本的下载地址,只 ...
- 2.pandas的数据结构
对于文件来说,读取只是最初级的要求,那我们要对文件进行数据分析,首先就应该要知道,pandas会将我们熟悉的文件转换成了什么形式的数据结构,以便于后续的操作 数据结构 pandas对文件一共有两种数据 ...
- 第四课 OOP封装继承多态解析,接口抽象类选择 2019-04-21
父类 xx = new 子类(); xx.method(); 1 普通方法由编译时决定(左边) --- 提高效率 2 虚方法(virtual) 由运行时决定-- -多态,灵活 3 抽象方法由运行时决 ...
- Lua学习入门(基本数据类型)
数据类型 Lua 中有 8 个基本类型分别为:nil.boolean.number.string.userdata.function.thread 和 table. 数据类型 描述 nil 这个最简单 ...
- MacOS下JDK8的安装与配置
微信搜索"艺术行者",关注并回复关键词"jdk8"获取安装包和API文档资料! 一.安装环节 1.打开网页 https://www.oracle.com/jav ...
- Tkinter经典写法
1.继承 tkinter.Frame 类,实现类的基本写法 2.创建主窗口及主窗口大小位置及标题 3.将需要添加的组件放入到类中进行创建, 继承的 Frame 类需要使用 master 参数作为父类的 ...