基于Mahout的电影推荐系统
基于Mahout的电影推荐系统
1.Mahout 简介
Apache Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。经典算法包括聚类、分类、协同过滤、进化编程等等,并且,在 Mahout 的最近版本中还加入了对 Apache Hadoop 的支持,使这些算法可以更高效的运行在云计算环境中。
2.Taste简介
Taste 是 Apache Mahout 提供的一个协同过滤算法的高效实现,它是一个基于 Java 实现的可扩展的,高效的推荐引擎。Taste 既实现了最基本的基于用户的和基于内容的推荐算法,同时也提供了扩展接口,使用户可以方便的定义和实现自己的推荐算法。同时,Taste 不仅仅只适用于 Java 应用程序,它可以作为内部服务器的一个组件以 HTTP 和 Web Service 的形式向外界提供推荐的逻辑。Taste 的设计使它能满足企业对推荐引擎在性能、灵活性和可扩展性等方面的要求。
图 1. Taste 的主要组件图
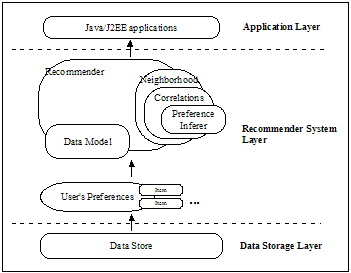
Taste 由以下五个主要的组件组成:
- DataModel:DataModel 是用户喜好信息的抽象接口,它的具体实现支持从任意类型的数据源抽取用户喜好信息。Taste 默认提供 JDBCDataModel 和 FileDataModel,分别支持从数据库和文件中读取用户的喜好信息。
- UserSimilarity 和 ItemSimilarity:UserSimilarity 用于定义两个用户间的相似度,它是基于协同过滤的推荐引擎的核心部分,可以用来计算用户的“邻居”,这里我们将与当前用户口味相似的用户称为他的邻居。ItemSimilarity 类似的,计算内容之间的相似度。
- UserNeighborhood:用于基于用户相似度的推荐方法中,推荐的内容是基于找到与当前用户喜好相似的“邻居用户”的方式产生的。UserNeighborhood 定义了确定邻居用户的方法,具体实现一般是基于 UserSimilarity 计算得到的。
- Recommender:Recommender 是推荐引擎的抽象接口,Taste 中的核心组件。程序中,为它提供一个 DataModel,它可以计算出对不同用户的推荐内容。实际应用中,主要使用它的实现类 GenericUserBasedRecommender 或者 GenericItemBasedRecommender,分别实现基于用户相似度的推荐引擎或者基于内容的推荐引擎。
3.系统介绍
(1)说明:系统制作比较简单,只为展示mahout的taste推荐算法,算法说明来自http://www.ibm.com/developerworks/cn/java/j-lo-mahout/
(2)准备工作:
环境:jdk,mysql,mahout-0.5,eclipse;
数据集:MovieLens 1M - Consists of 1 million ratings from 6000 users on 4000 movies. 数据集链接:http://www.grouplens.org/node/12
数据集说明:
These files contain 1,000,209 anonymous ratings of approximately 3,900 movies
made by 6,040 MovieLens users who joined MovieLens in 2000.
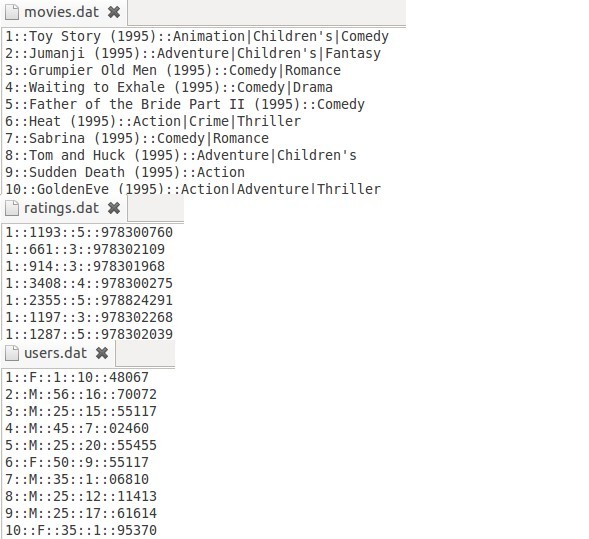
movies.dat的文件描述是 电影编号::电影名::电影类别
ratings.dat的文件描述是 用户编号::电影编号::电影评分::时间戳
users.dat的文件描述是 用户编号::性别::年龄::职业::Zip-code
(3)实施:
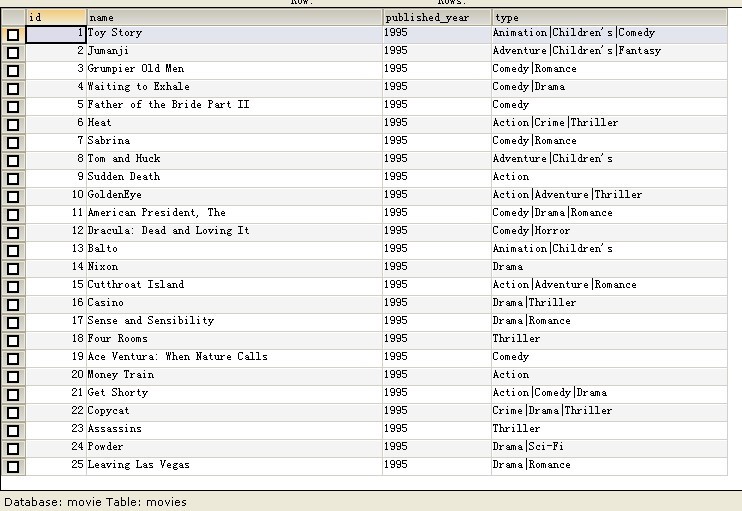
数据库录入:将数据集导入mysql

1 CREATE DATABASE movie;
2 USE movie;
3 CREATE TABLE movies ( //对应movies.dat
4 id INTEGER NOT NULL AUTO_INCREMENT,
5 name varchar(100) NOT NULL,
6 published_year varchar(4) default NULL,
7 type varchar(100) default NULL,
8 PRIMARY KEY (id)
9 );
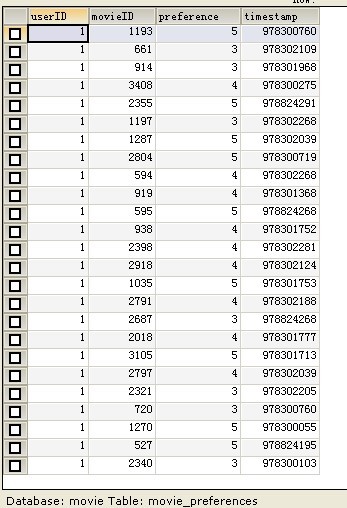
10 CREATE TABLE movie_preferences ( //对应ratings.dat
11 userID INTEGER NOT NULL,
12 movieID INTEGER NOT NULL,
13 preference INTEGER NOT NULL DEFAULT 0,
14 timestamp INTEGER not null default 0,
15 FOREIGN KEY (movieID) REFERENCES movies(id) ON DELETE CASCADE
16 );
推荐算法介绍:
基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是,根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“K- 邻居”的算法;然后,基于这 K 个邻居的历史偏好信息,为当前用户进行推荐。下图 4 给出了原理图。
基于用户的协同过滤推荐机制的基本原理

上图示意出基于用户的协同过滤推荐机制的基本原理,假设用户 A 喜欢物品 A,物品 C,用户 B 喜欢物品 B,用户 C 喜欢物品 A ,物品 C 和物品 D;从 这些用户的历史喜好信息中,我们可以发现用户 A 和用户 C 的口味和偏好是比较类似的,同时用户 C 还喜欢物品 D,那么我们可以推断用户 A 可能也喜欢 物品 D,因此可以将物品 D 推荐给用户 A。
基于项目的协同过滤推荐
基于项目的协同过滤推荐的基本原理也是类似的,只是说它使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好 信息,将类似的物品推荐给用户,图 5 很好的诠释了它的基本原理。
假设用户 A 喜欢物品 A 和物品 C,用户 B 喜欢物品 A,物品 B 和物品 C,用户 C 喜欢物品 A,从这些用户的历史喜好可以分析出物品 A 和物品 C 时比 较类似的,喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
与上面讲的类似,基于项目的协同过滤推荐和基于内容的推荐其实都是基于物品相似度预测推荐,只是相似度计算的方法不一样,前者是从用户历史的偏好 推断,而后者是基于物品本身的属性特征信息。
基于项目的协同过滤推荐机制的基本原理

核心算法代码展示:
import org.apache.mahout.cf.taste.impl.model.file.*;//FileDataModel
import org.apache.mahout.cf.taste.model.*;//DAtaModel
import org.apache.mahout.cf.taste.impl.neighborhood.*;
import org.apache.mahout.cf.taste.impl.recommender.*;
import org.apache.mahout.cf.taste.impl.similarity.*;
import org.apache.mahout.cf.taste.neighborhood.*;
import org.apache.mahout.cf.taste.similarity.*;
import org.apache.mahout.cf.taste.recommender.*; import java.io.*;
import java.util.*; public class RecommendDeal{
int userID;
int length; public RecommendDeal(int userID){
this.userID=userID; }
//*******************基于用户的推荐********************
public List<RecommendedItem> userBasedRecommender() {
// step:1 构建模型 2 计算相似度 3 查找k紧邻 4 构造推荐引擎
List<RecommendedItem> recommendations = null;
try {
length=(int)((Math.random()+3)*10); DataModel model = new FileDataModel(new File("D:\\ratings.txt"));//构造数据模型,Database-based
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);//用PearsonCorrelation 算法计算用户相似度
UserNeighborhood neighborhood = new NearestNUserNeighborhood(length, similarity, model);//计算用户的“邻居”,这里将与该用户最近距离为 3 的用户设置为该用户的“邻居”。
Recommender recommender = new CachingRecommender(new GenericUserBasedRecommender(model, neighborhood, similarity));//构造推荐引擎,采用 CachingRecommender 为 RecommendationItem 进行缓存
recommendations = recommender.recommend(this.userID, 20);//得到推荐的结果,20是推荐的数目
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
return recommendations;
}
//**********************基于项目的推荐*******************
public List<RecommendedItem> ItemBasedRecommender(){
List<RecommendedItem> recommendations = null;
length=(int)((Math.random()+1)*10);
try {
DataModel model = new FileDataModel(new File("D:\\ratings.txt"));//构造数据模型,File-based
ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);//计算内容相似度
Recommender recommender = new GenericItemBasedRecommender(model, similarity);//构造推荐引擎
recommendations = recommender.recommend(this.userID, length);//得到推荐接过
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
return recommendations;
} }
读入文件说明:由于数据量比较大,100W条,通过数据库读数据太慢,采用从文件中直接读取,(也许是我电脑的问题)我的文件是ratings.txt
 通过推荐算法得出结果后,从数据库查出对应信息,显示在前台。
通过推荐算法得出结果后,从数据库查出对应信息,显示在前台。
项目截图:
1>框架图:只用了链接mysql的包,和mahout的包,无其他包,如图
2>效果图:
login
登录后选择,点直接推荐是基于用户的,点随便看看是基于项目的

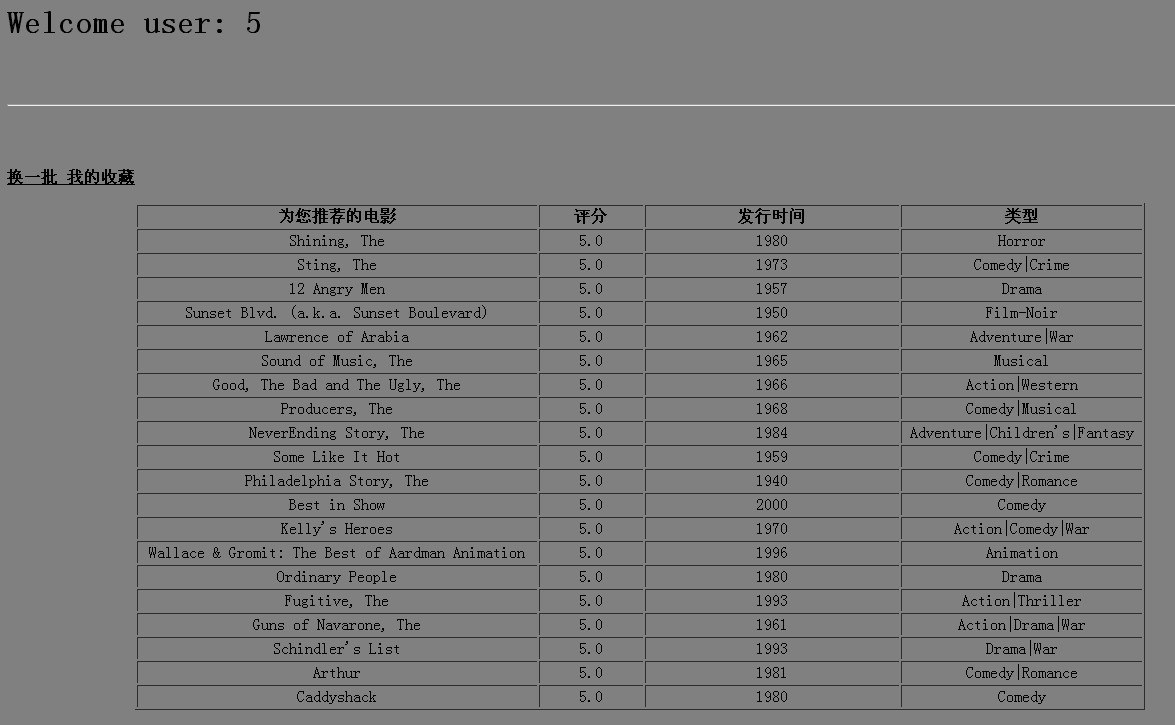
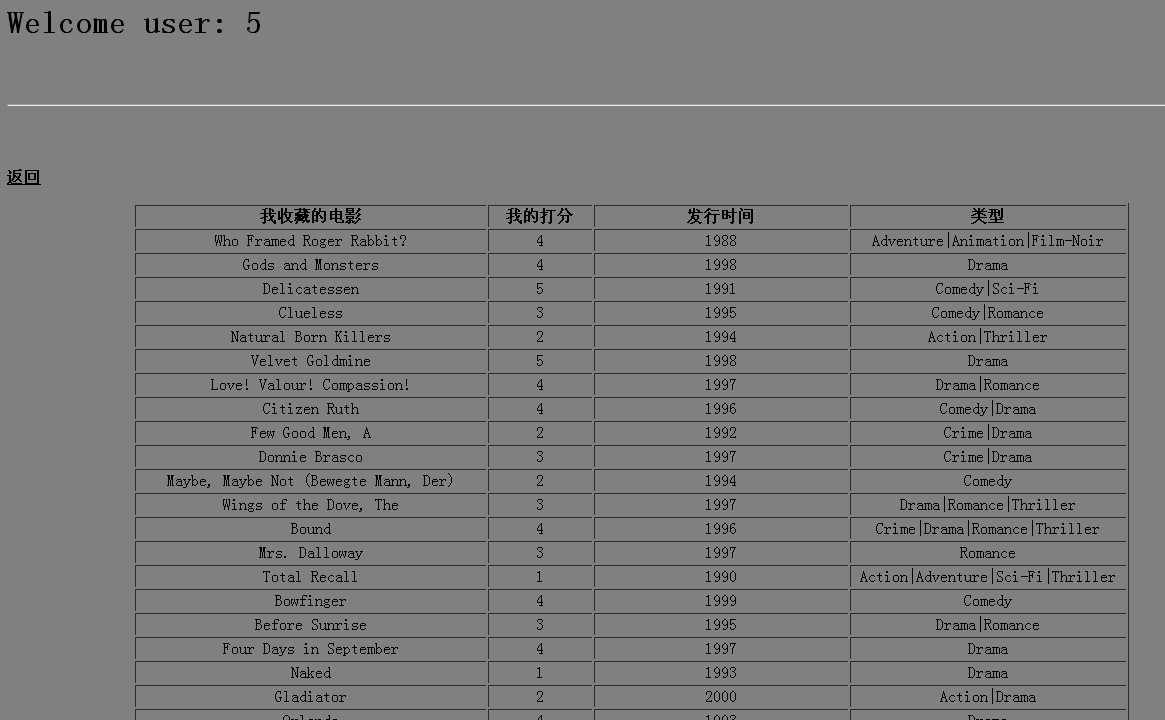
点击系统推荐,直接出结果:
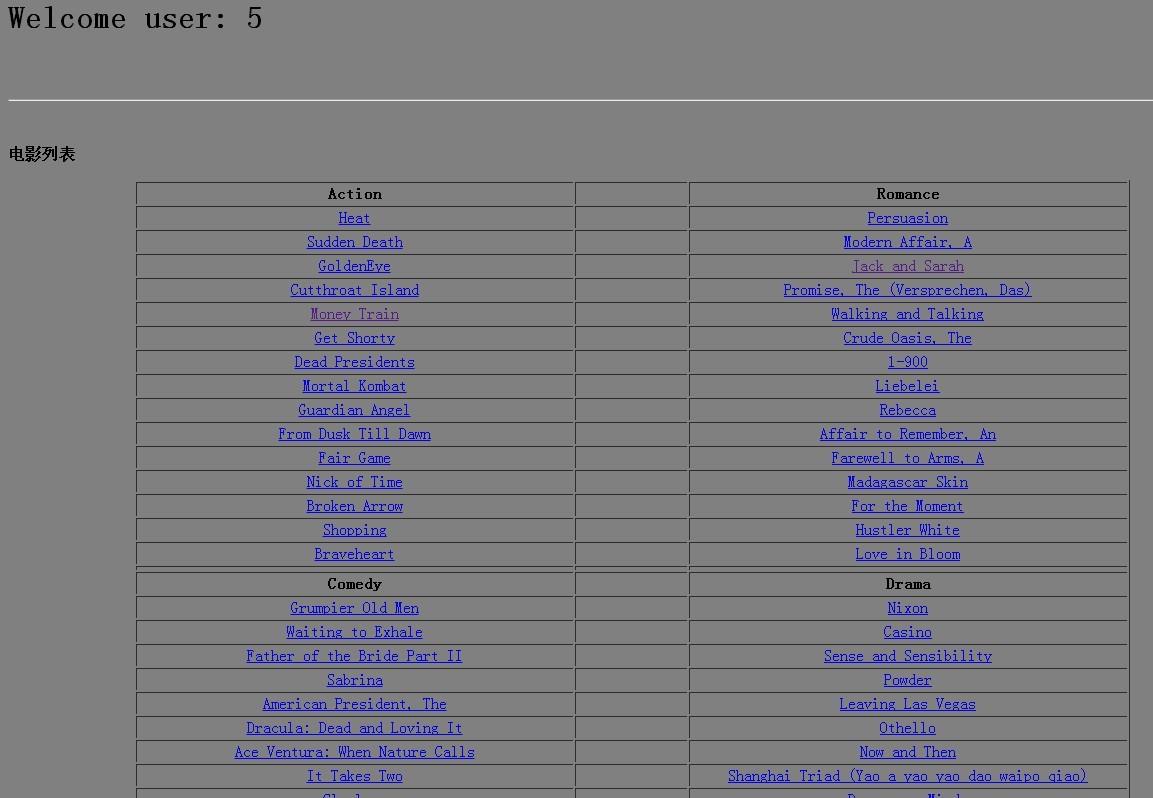
点击随便看看,展示部分电影,通过链接,显示电影详情,并实现项目推荐
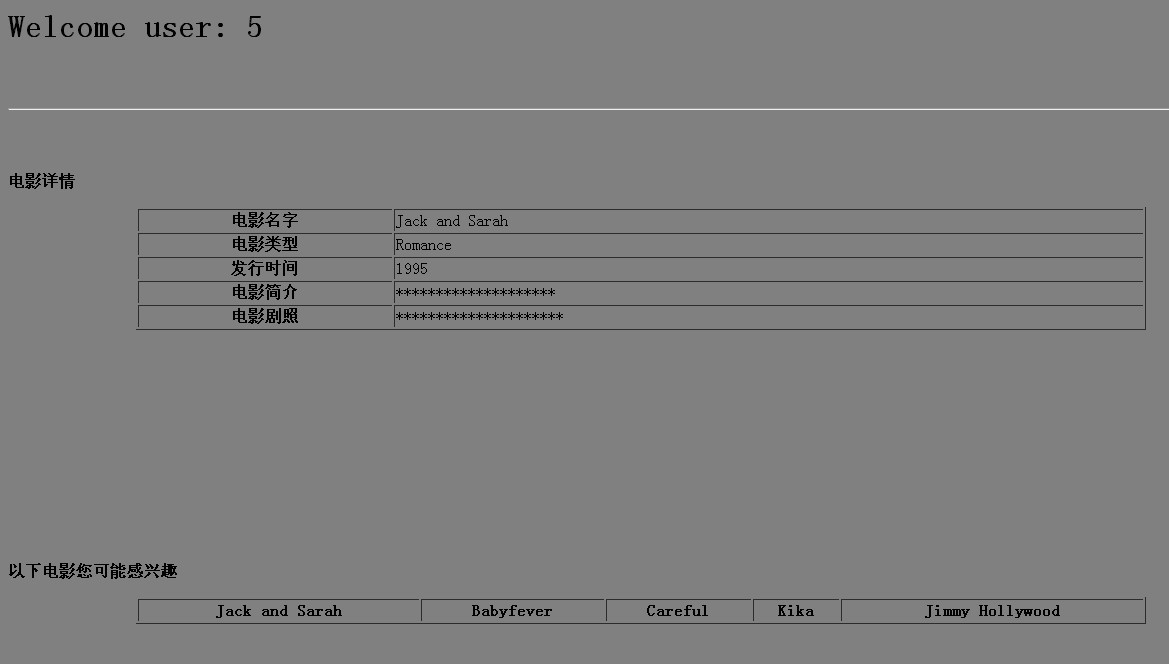
这里只推荐了5个,根据需要推荐的条数可以调整
4.总结
此项目做得简单而丑陋,一方面是时间原因,另一方面是初衷,之所以做这个是了解一下推荐算法,通过前台能够直观展现出来,也可以为正在学习这方面知识的同学,做个参考!
此外,在数据量比较大的情况下,我发现串行跑的很吃力,接下来的工作可以在hadoop上继续研究一下Taste! 参考:http://www.ibm.com/developerworks/cn/java/j-lo-mahout/
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html
http://blog.csdn.net/huhui_cs/article/details/8596388
基于Mahout的电影推荐系统的更多相关文章
- 基于pytorch的电影推荐系统
本文介绍一个基于pytorch的电影推荐系统. 代码移植自https://github.com/chengstone/movie_recommender. 原作者用了tf1.0实现了这个基于movie ...
- 基于Spark的电影推荐系统(电影网站)
第一部分-电影网站: 软件架构: SpringBoot+Mybatis+JSP 项目描述:主要实现电影网站的展现 和 用户的所有动作的地方 技术选型: 技术 名称 官网 Spring Boot 容器 ...
- 基于Spark的电影推荐系统(实战简介)
写在前面 一直不知道这个专栏该如何开始写,思来想去,还是暂时把自己对这个项目的一些想法 和大家分享 的形式来展现.有什么问题,欢迎大家一起留言讨论. 这个项目的源代码是在https://github. ...
- 基于Spark的电影推荐系统(推荐系统~2)
第四部分-推荐系统-数据ETL 本模块完成数据清洗,并将清洗后的数据load到Hive数据表里面去 前置准备: spark +hive vim $SPARK_HOME/conf/hive-site.x ...
- 基于Spark的电影推荐系统(推荐系统~4)
第四部分-推荐系统-模型训练 本模块基于第3节 数据加工得到的训练集和测试集数据 做模型训练,最后得到一系列的模型,进而做 预测. 训练多个模型,取其中最好,即取RMSE(均方根误差)值最小的模型 说 ...
- 基于Spark的电影推荐系统(推荐系统~7)
基于Spark的电影推荐系统(推荐系统~7) 22/100 发布文章 liuge36 第四部分-推荐系统-实时推荐 本模块基于第4节得到的模型,开始为用户做实时推荐,推荐用户最有可能喜爱的5部电影. ...
- 基于Spark的电影推荐系统(推荐系统~1)
第四部分-推荐系统-项目介绍 行业背景: 快速:Apache Spark以内存计算为核心 通用 :一站式解决各个问题,ADHOC SQL查询,流计算,数据挖掘,图计算 完整的生态圈 只要掌握Spark ...
- 基于Spark的电影推荐系统
数据文件: u.data(userid itemid rating timestamp) u.item(主要使用 movieid movietitle) 数据操作 把u.data导入RDD, t ...
- Python基于机器学习方法实现的电影推荐系统
推荐算法在互联网行业的应用非常广泛,今日头条.美团点评等都有个性化推荐,推荐算法抽象来讲,是一种对于内容满意度的拟合函数,涉及到用户特征和内容特征,作为模型训练所需维度的两大来源,而点击率,页面停留时 ...
随机推荐
- [引]LINQ to XML 类概述
本文转自:http://msdn.microsoft.com/zh-cn/library/bb387023.aspx 本主题提供 System.Xml.Linq 命名空间中 LINQ to XML 类 ...
- 关于SWT的容器类之----面板Composite类和Group类
1.Comosite类谱系图. Composite的用法: 格式:Composite(Composite parent,int style) 用法:Composite composite = new ...
- Guzzle Unable to parse JSON data: JSON_ERROR_SYNTAX - Syntax error, malformed JSON
项目更新到正式平台时,出现Guzzle(5.3) client get请求出现:Unable to parse JSON data: JSON_ERROR_SYNTAX - Syntax error, ...
- videojs 动态加载视频
VideoJS dynamic source change via RESTful API 'Undefined' issue with changing RTMP source on compres ...
- .NET学习笔记(3) — VisualStudio使用总结
目录 一:VS是什么? 二:VS可以创建什么类型的工程? 三:VS的常用功能? 四:VS都有哪些使用技巧? 五:注意事项 六:资源汇总 一:VS是什么? Microsoft Visual Stud ...
- MySQL 테이블 타입(Heap, MyIsam, InnoDB...) 변경하기
alter table 을 이용해서 기존의 생성된 테이블의 타입(Heap, MyIsam, InnoDB...)을 변경하는 명령어 입니다. 잠시 까먹은 분은 계실지 몰라도 원래 모르는 ...
- ios 视频音乐播放
IOS开发小技巧(视频和音乐播放).IOS视频播放代码(添加MediaPlayer.framework和#import) -(void)playMovie:(NSString *)fileName{ ...
- FileInputStream 与 BufferedInputStream 效率对比
我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3550158.html ,享受整齐的排版.有效的链接.正确的代码缩进.更好的阅读体 ...
- C++ 中的“ !” 运算
在介绍“ !”运算之前,我们要知道一个变量n,如果n>0,那么我们可以在逻辑上叫它“真”,如果n<=0 ,那么我们可以在逻辑上叫它“假”. n为真时,!n就为假(false),转换为整型值 ...
- 第46条:for-each循环优先于传统的for循环
for-each循环通过完全隐藏迭代器或者索引变量,避免混乱和出错的可能,适用于集合和数组和任何实现Iterable接口的对象. 使用传统for循环,容易出错: enum Face { ONE, TW ...