hadoop倒排索引
1.前言
学习hadoop的童鞋,倒排索引这个算法还是挺重要的。这是以后展开工作的基础。首先,我们来认识下什么是倒拍索引:
倒排索引简单地就是:根据单词,返回它在哪个文件中出现过,而且频率是多少的结果。这就像百度里的搜索,你输入一个关键字,那么百度引擎就迅速的在它的服务器里找到有该关键字的文件,并根据频率和其他一些策略(如页面点击投票率)等来给你返回结果。这个过程中,倒排索引就起到很关键的作用。
2.分析设计
倒排索引涉及几个过程:Map过程,Combine过程,Reduce过程。下面我们来分析以上的过程。
2.1Map过程
当你把需要处理的文档上传到hdfs时,首先默认的TextInputFormat类对输入的文件进行处理,得到文件中每一行的偏移量和这一行内容的键值对<偏移量,内容>做为map的输入。在改写map函数的时候,我们就需要考虑,怎么设计key和value的值来适合MapReduce框架,从而得到正确的结果。由于我们要得到单词,所属的文档URL,词频,而<key,value>只有两个值,那么就必须得合并其中得两个信息了。这里我们设计key=单词+URL,value=词频。即map得输出为<单词+URL,词频>,之所以将单词+URL做为key,时利用MapReduce框架自带得Map端进行排序。
下面举个简单得例子:

图1 map过程 输入/输出
2.2 Combine过程
combine过程将key值相同得value值累加,得到一个单词在文档上得词频。但是为了把相同得key交给同一个reduce处理,我们需要设计为key=单词,value=URL+词频
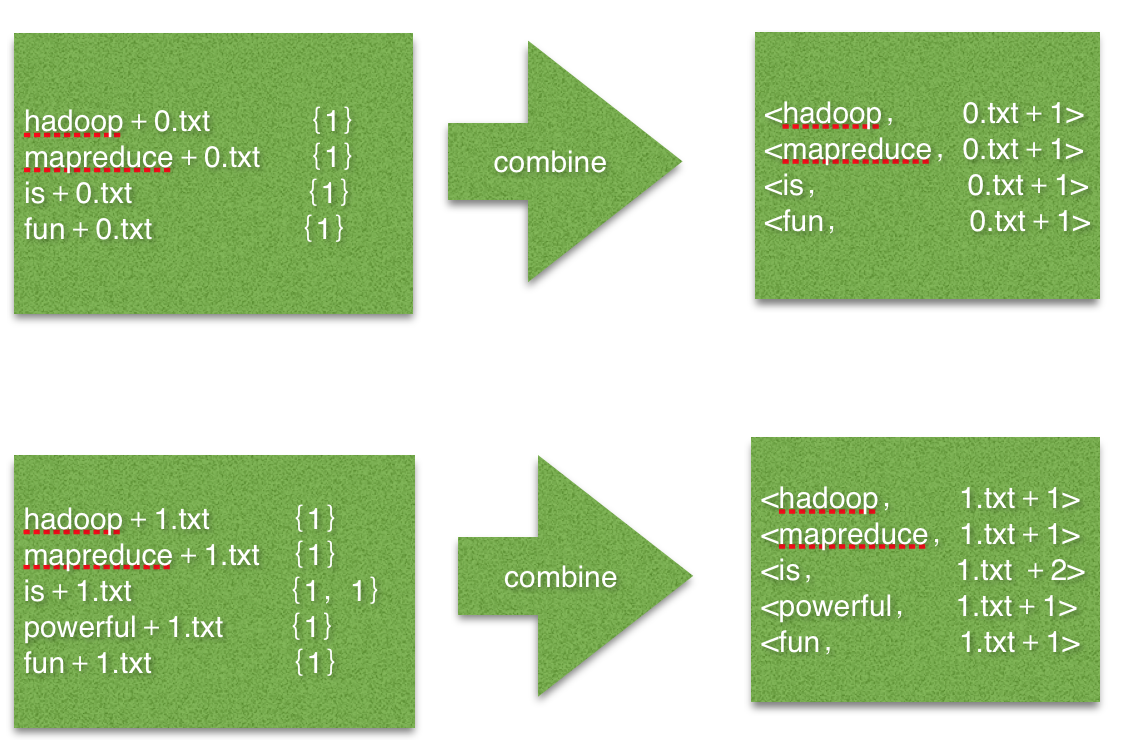
图2 Combin过程 输入/输出
2.3Reduce过程
reduce过程其实就是一个合并的过程了,只需将相同的key值的value值合并成倒排索引需要的格式即可。
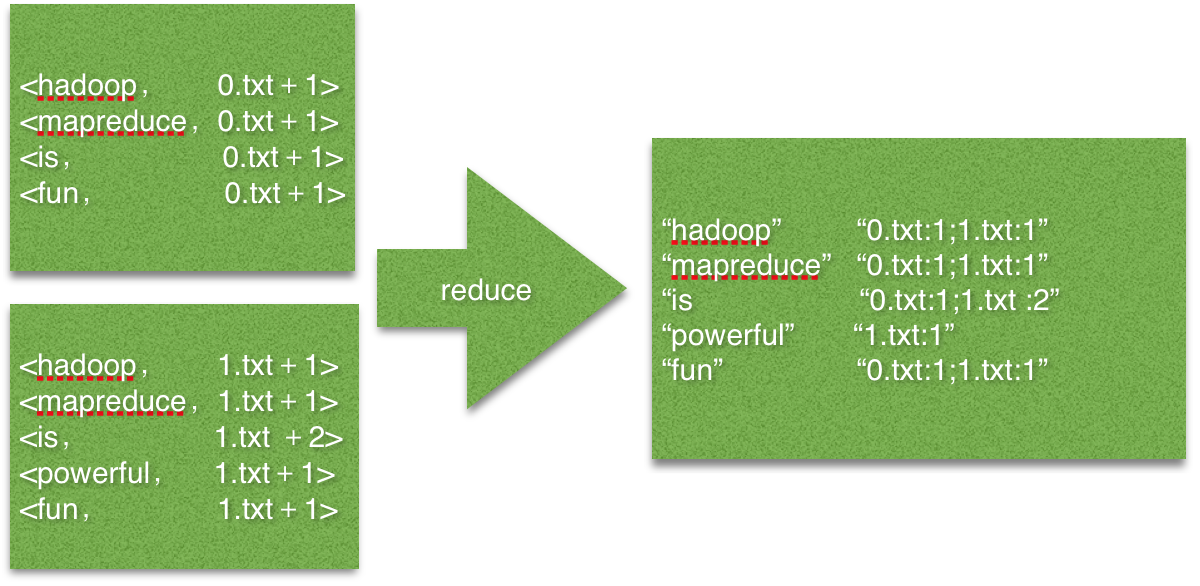
图3 reduce过程 输入/输出
3.源代码
package reverseIndex; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class InvertedIndex { public static class InvertedIndexMapper extends Mapper<Object, Text, Text, Text>{
private Text keyInfo=new Text();
private Text valueInfo=new Text();
private FileSplit split; public void map(Object key,Text value,Context context)throws IOException,InterruptedException {
//获得<key,value>对所属的对象
split=(FileSplit)context.getInputSplit();
StringTokenizer itr=new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
//key值有单词和url组成,如"mapreduce:1.txt"
keyInfo.set(itr.nextToken()+":"+split.getPath().toString());
valueInfo.set("1");
context.write(keyInfo, valueInfo);
} }
}
public static class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text>{
private Text info=new Text();
public void reduce(Text key,Iterable<Text> values,Context context)throws IOException,InterruptedException {
//统计词频
int sum=0;
for (Text value:values) {
sum+=Integer.parseInt(value.toString());
} int splitIndex=key.toString().indexOf(":");
//重新设置value值由url和词频组成
info.set(key.toString().substring(splitIndex+1)+":"+sum);
//重新设置key值为单词
key.set(key.toString().substring(0,splitIndex));
context.write(key, info);
}
}
public static class InvertedIndexReduce extends Reducer<Text, Text, Text, Text> {
private Text result=new Text();
public void reduce(Text key,Iterable<Text>values,Context context) throws IOException,InterruptedException{
//生成文档列表
String fileList=new String();
for (Text value:values) {
fileList+=value.toString()+";";
}
result.set(fileList);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
String[] otherArgs=new GenericOptionsParser(conf,args).getRemainingArgs();
if (otherArgs.length!=2) {
System.err.println("Usage:invertedindex<in><out>");
System.exit(2);
}
Job job=new Job(conf,"InvertedIndex");
job.setJarByClass(InvertedIndex.class); job.setMapperClass(InvertedIndexMapper.class); job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReduce.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true)?0:1); } }
hadoop倒排索引的更多相关文章
- Hadoop 倒排索引
倒排索引是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎.它主要是用来存储某个单词(或词组)在一个文档或一组文档中存储位置的映射,即提供了一种根据内容来查找文档的方式.由于不是根据文档来确 ...
- Hadoop之倒排索引
前言: 从IT跨度到DT,如今的数据每天都在海量的增长.面对如此巨大的数据,如何能让搜索引擎更好的工作呢?本文作为Hadoop系列的第二篇,将介绍分布式情况下搜索引擎的基础实现,即“倒排索引”. 1. ...
- hadoop学习笔记之倒排索引
开发工具:eclipse 目标:对下面文档phone_numbers进行倒排索引: 13599999999 1008613899999999 12013944444444 13800138000137 ...
- hadoop实现倒排索引
hadoop实现倒排索引 本文用hadoop实现倒排索引算法,用基本的分两步完成,不使用combine 第一步 读入文档,统计文档中各个单词的个数,与word count类似,但这里把word-fil ...
- Hadoop学习笔记(8) ——实战 做个倒排索引
Hadoop学习笔记(8) ——实战 做个倒排索引 倒排索引是文档检索系统中最常用数据结构.根据单词反过来查在文档中出现的频率,而不是根据文档来,所以称倒排索引(Inverted Index).结构如 ...
- Hadoop案例(四)倒排索引(多job串联)与全局计数器
一. 倒排索引(多job串联) 1. 需求分析 有大量的文本(文档.网页),需要建立搜索索引 xyg pingping xyg ss xyg ss a.txt xyg pingping xyg pin ...
- hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例
一.MapReduce介绍 (最好以下面的两个示例来理解原理) 1. MapReduce的基本思想 Map-reduce的思想就是“分而治之” Map Mapper负责“分”,即把复杂的任务分解为若干 ...
- Hadoop实战-MapReduce之倒排索引(八)
倒排索引 (就是key和Value对调的显示结果) 一.需求:下面是用户播放音乐记录,统计歌曲被哪些用户播放过 tom LittleApple jack YesterdayO ...
- Hadoop MapReduce编程 API入门系列之倒排索引(二十四)
不多说,直接上代码. 2016-12-12 21:54:04,509 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JV ...
随机推荐
- C++使用类型代替枚举量
自己写的C++类型枚举量,可以使用类型识别取代模板,绑定枚举量和多组调用函数,在调用阶段只要指定某组函数就可以根据枚举量调用相应函数. 代码如下: #ifndef __MYENUM_H__ #defi ...
- SPA解释:单页应用程序
单页Web应用(single page web application,SPA),就是只有一张Web页面的应用,是加载单个HTML 页面并在用户与应用程序交互时动态更新该页面的Web应用程序. 单页W ...
- oracle 备份与还原 及相关操作
drop user 用户名 cascade; ........删除用户 create user 用户名 identified by 密码 default tablespace 数据文件名 tempor ...
- Lucene使用IKAnalyzer分词实例 及 IKAnalyzer扩展词库
文章转载自:http://www.cnblogs.com/dennisit/archive/2013/04/07/3005847.html 方案一: 基于配置的词典扩充 项目结构图如下: IK分词器还 ...
- JQuery插件开发 - 模板
(function($) { $.fn.PluginName = function(options) { // 创建一个默认设置对象 var defaults = { key : "Defa ...
- 【原】去掉UltraGrid第三方控件中的Drag a column header here to group by that column
- git记住用户名密码
git config --global credential.helper store
- VB最新使用教程
Visual Basic是一种由 微软公司开发的结构化的.模块化的.面向对象的.包含协助开发环境的事件驱动为机制的可视化程序设计语言.这是一种可用于微软自家产品开发的语言.它源自于BASIC编程语言. ...
- Java对象校验框架之Oval
只要有接口,就会有参数的校验,目前开源的校验框架已经非常多了,不过不得不提一下Oval.OVal 是一个可扩展的Java对象数据验证框架,验证的规则可以通过配置文件.Annotation.POJO ...
- Python-Day3 Python基础进阶之集和/文件读写/函数
一.集和 集合是一个无序的,不重复的数据组合,它的主要作用如下: 去重,把一个列表变成集合,就自动去重了 关系测试,测试两组数据之前的交集.差集.并集等关系 1.创建集合 >>> s ...