Azkaban 工作流调度器
Azkaban 工作流调度器
1 概述
1.1 为什么需要工作流调度系统
a)一个完整的数据分析系统通常都是由大量任务单元组成,shell脚本程序,java程序,mapreduce程序、hive脚本等。
b)各任务单元之间存在时间先后及前后依赖关系。
c)为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。
1.2 工作流调度实现方式
简单的任务调度:直接使用linux的crontab来定义;
复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如ooize、azkaban等。
1.3 常见工作流调度系统
在hadoop领域,常见的工作流调度器有Oozie, Azkaban,Cascading,Hamake等。
1.4 Azkaban 与 Oozie对比
对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。
2 Azkaban 介绍
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
功能特点:
Web用户界面
方便上传工作流
方便设置任务之间的关系
调度工作流
认证/授权(权限的工作)
能够杀死并重新启动工作流
模块化和可插拔的插件机制
项目工作区
工作流和任务的日志记录和审计
2.1 Azkaban 安装部署
2.1.1 准备工作:
azkaban-web-server-2.5.0.tar.gz
azkaban-executor-server-2.5.0.tar.gz
MYSQL
2.1.2 安装
1)分别解压webserver和executorServer
2)创建SSL配置
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
3) 在mysql数据库中创建azkaban库,执行sql脚本create-all-sql-3.39.0-12-gb44c688.sql(注意:该脚本在db模块中,要讲mysql引擎改为innoDB)
2.1.3 配置文件:
2.1.3.1 先配置好服务器节点上的时区
a) 先生成时区配置文件Asia/Shanghai,用交互式命令 tzselect 即可。
b) 拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
2.1.3.2 azkaban web服务器配置
conf目录下文件
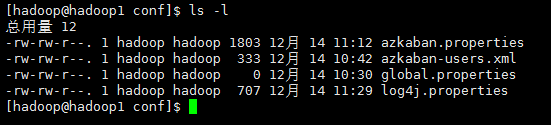
# Azkaban Personalization Settings
azkaban.name=Test
azkaban.label=My Local Azkaban
azkaban.color=#FF3601
azkaban.default.servlet.path=/index
web.resource.dir=web/
default.timezone.id=Asia/Shanghai
# Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
user.manager.xml.file=conf/azkaban-users.xml
# Loader for projects
executor.global.properties=conf/global.properties
azkaban.project.dir=projects
database.type=mysql
mysql.port=3306
mysql.host=localhost
mysql.database=azkaban
mysql.user=root
mysql.password=123456
mysql.numconnections=100
# Velocity dev mode
velocity.dev.mode=false
# Azkaban Jetty server properties.
jetty.maxThreads=25
jetty.ssl.port=8443
jetty.port=8081
jetty.keystore=keystore
jetty.password=123456
jetty.keypassword=123456
jetty.truststore=keystore
jetty.trustpassword=123456
# Azkaban Executor settings
executor.port=12321
# mail settings
mail.sender=xxx@126.com
mail.host=smtp.126.com
# User facing web server configurations used to construct the user facing server URLs. They are useful when there is a reverse proxy between Azkaban web servers and users.
# enduser -> myazkabanhost:443 -> proxy -> localhost:8081
# when this parameters set then these parameters are used to generate email links.
# if these parameters are not set then jetty.hostname, and jetty.port(if ssl configured jetty.ssl.port) are used.
# azkaban.webserver.external_hostname=myazkabanhost.com
# azkaban.webserver.external_ssl_port=443
# azkaban.webserver.external_port=8081
mail.user=xxxxxxxx
mail.password=**********
job.failure.email=xxxxxxxx@163.com
job.success.email=xxxxxxxx@163.com
lockdown.create.projects=false
cache.directory=cache
azkaban.properties
<azkaban-users>
<user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/>
<user password="metrics" roles="metrics" username="metrics"/>
<user username="admin" password="admin" roles="admin,metrics" />
<role name="admin" permissions="ADMIN"/>
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
azkaban-users.xml
2.1.3.3 azkaban 执行器配置
# Azkaban Personalization Settings
default.timezone.id=Asia/Shanghai
# Loader for projects
executor.global.properties=conf/global.properties
azkaban.project.dir=projects
# 数据库配置
database.type=mysql
mysql.port=3306
mysql.host=localhost
mysql.database=azkaban
mysql.user=root
mysql.password=123456
mysql.numconnections=100
#执行服务器配置
executor.port=12321
executor.connector.stats=true
executor.maxThreads=50
executor.flow.threads=30
# Azkaban plugin settings
azkaban.jobtype.plugin.dir=plugins/jobtypes
azkaban.properties
详细配置请参考:http://azkaban.github.io/azkaban/docs/latest/ (3.0版本编译完后web和exec中没有配置文件 需要将solo中的配置文件复制过去)
2.1.4 启动
在azkaban web服务器目录下执行启动命令
bin/azkaban-web-start.sh
注:在web服务器根目录运行
在执行服务器目录下执行启动命令
bin/azkaban-executor-start.sh
注:只能要执行服务器根目录运行
启动完成后,在浏览器(建议使用谷歌浏览器)中输入https://服务器IP地址:8443 ,即可访问azkaban服务了.在登录中输入刚才新的户用名及密码,点击 login.
3 实战
Azkaba内置的任务类型支持command、java。
3.1 Command类型单一job示例
a) 创建job描述文件
vi command.job
#command.job
type=command
command=echo 'hello'
b)将job资源文件打包成zip文件
zip command.job
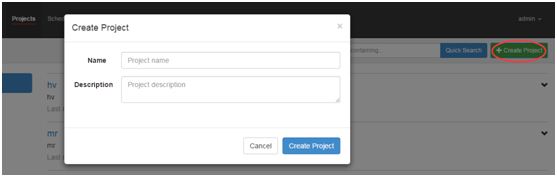
c) 通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
上传zip
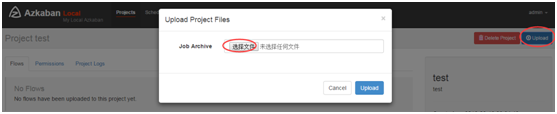
d)启动执行该job

3.2 Command类型多job工作流flow
a)创建有依赖关系的多个job描述
第一个job:foo.job
# foo.job
type=command
command=echo foo
第二个job:bar.job依赖foo.job
# bar.job
type=command
dependencies=foo
command=echo bar
b)将所有job打成一个zip包
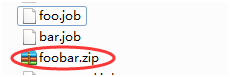
c) 在azkaban 的web管理界面创建工程并上传zip包
d)启动工作流flow
3.3 HDFS操作任务
# fs.job
type=command
command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop fs -mkdir /azaz
3.4 MapReduce任务
# mrwc.job
type=command
command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop jar hadoop-mapreduce-examples-2.6.1.jar wordcount /wordcount/input /wordcount/azout
将所有资源打包成zip

3.5 HIVE脚本任务
Hive脚本: test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',';
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
Job描述文件:hivef.job
# hivef.job
type=command
command=/home/hadoop/apps/hive/bin/hive -f 'test.sql'
Azkaban 工作流调度器的更多相关文章
- Azkaban工作流调度器
Azkaban工作流调度器 在Hadoop领域常用的工作流调度系统 Oozie,Azkaban,Cascading,Hamake等等. 性能对比: 安装: 创建ssl配置 keytool -keyst ...
- azkaban工作流调度器及相关工具对比
本文转载自:工作流调度器azkaban,主要用于架构选型,安装请参考:Azkaban安装与简介,azkaban的简单使用 为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成: ...
- 工作流调度器azkaban(以及各种工作流调度器比对)
1:工作流调度系统的作用: (1):一个完整的数据分析系统通常都是由大量任务单元组成:比如,shell脚本程序,java程序,mapreduce程序.hive脚本等:(2):各任务单元之间存在时间先后 ...
- 工作流调度器azkaban
为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成: shell脚本程序,java程序,mapreduce程序.hive脚本等 各任务单元之间存在时间先后及前后依赖关系 为了很 ...
- 工作流调度器azkaban2.5.0的安装和使用
为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成: shell脚本程序,java程序,mapreduce程序.hive脚本等 各任务单元之间存在时间先后及前后依赖关系 为了很 ...
- 【Hadoop离线基础总结】工作流调度器azkaban
目录 Azkaban概述 工作流调度系统的作用 工作流调度系统的实现 常见工作流调度工具对比 Azkaban简单介绍 安装部署 Azkaban的编译 azkaban单服务模式安装与使用 azkaban ...
- 07_Azkaban工作流调度器简介及其安装
Azkaban介绍 Azkaban是一个Linkedin开源的一个批量工作流任务调度器.用于在一个工作流内以一个特定的顺序运行一组工作和流程. Azkaban定义了一种KV文件格式来建立任务之间的依赖 ...
- 大数据学习——azkaban工作流调度系统
azkaban的安装部署 在/root/apps 1目录下新建azkaban文件夹 上传安装包到azkaban 2解压 .tar.gz 3删掉安装包 [root@mini1 azkaban]# .ta ...
- 工作流调度系统Azkaban的简介和使用
1 概述 1.1 为什么需要工作流调度系统 l 一个完整的数据分析系统通常都是由大量任务单元组成: shell脚本程序,java程序,mapreduce程序.hive脚本等 l 各任务单元之间存在时间 ...
随机推荐
- MyBatis(2)-全局配置文件
本文的代码是在MyBatis(1)-简单入门基础之上进行学习的,如有不懂请先看此博文MyBatis(1)-简单入门! 1)配置文件的安装 --->在联网的情况下,点击去下载http://myba ...
- 虚拟机和主机文件实时同步 -- winsshfs的快速入手
之前在公司使用mac ,并且通过mac下的osfuse和sshfs连接,直接将虚拟机的文件目录同步到了本地,并且可以进行实时操作修改,对于写项目,确实是省了很大一部分上传的精力. 于是在自己的win下 ...
- CS20Chapter2
constants操作 import tensorflow as tf a = tf.constant([2, 2], name='a') b = tf.constant([[0, 1], [2, 3 ...
- Shell笔记-01
打开文本编辑器,新建一个文件,扩展名为sh(sh代表shell),扩展名并不影响脚本执行,见名知意就好,如果你用php写shell 脚本,扩展名就用php好了. 输入一些代码: #!/bin/bash ...
- 如何转换Xcode里打印的unicode编码日志
转换Xcode里打印的unicode编码日志 1)打开Terminal 2)输入python 3)print(u'\u6027\u611f\u597d\u83b1\u575e\u5973\u661f\ ...
- CC2640R2F&TI-RTOS 拿到 TI CC2640R2F 开发板 第二件事就是 LED 驱动 ,点个灯
/* * board_led.c * * Created on: 2018年7月3日 * Author: admin */ #include "board_uart.h" #inc ...
- gdb tui中切换窗口
gdb的gui用法 调试代码的时候,只能看到下一行,每次使用list非常烦,不知道当前代码的context http://beej.us/guide/bggdb/#compiling 简单来说就是在 ...
- 中文字体@font-face的导入
由于英文字母只有26个,所以生成.eot..woff..ttf..svg等文件是比较小的,也就十几KB而已.但是对于汉字来说,常用的汉字就已经2500个了,生成的文件一般要2-3MB,如此庞大的包对页 ...
- Java中的监听器
servlet的技术规范包括三个:servlet,listener,filter,今天记录一下listener的学习. 监听器就是监听某个对象的状态变化的技术.监听器包括事件源,监听器,注册监听器以及 ...
- [Linux]使用宝塔面板做负载均衡时遇到的问题和解决办法
最近公司的小程序因为高峰期访问缓慢的问题,打算用负载均衡试试.本人是个新手,在网上找了几篇负载均衡的文章看了看,最后还是用了宝塔面板的负载均衡插件...这个服务器我也是刚刚接手,很多东西都是以前的同事 ...