Hdfs&MapReduce测试
Hdfs&MapReduce测试
测试 上传文件到hdfs
随意打开一个文件夹传一个文件试试(把javafx-src.zip传到hdfs的/根目录下):hadoop fs -put javafx-src.zip hdfs://node01:9000/
用客户端(windows主机)浏览器打开 http://node01:50070 能看到这文件(当然,先要在windows配置下hosts,加一行node01 192.168.216.100)

测试 运行一个MapReduce程序
cd hadoop-3.0.0/share/hadoop/mapreduce 有个example程序jar包
hadoop jar hadoop-mapreduce-examples-3.0.0.jar pi 5 5 运行其中一个pi程序,参数是map的任务数量和每个map的取样数
运行失败,log如下
Current usage: 38.3 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.
解决方案:https://blog.csdn.net/paicMis/article/details/73477019 按照这个的方法三,到mapred-site.xml中设置map和reduce任务的内存配置
我设置的参数如下:
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2048M</value>
</property>
再次运行成功。
Hdfs的实现思想粗略
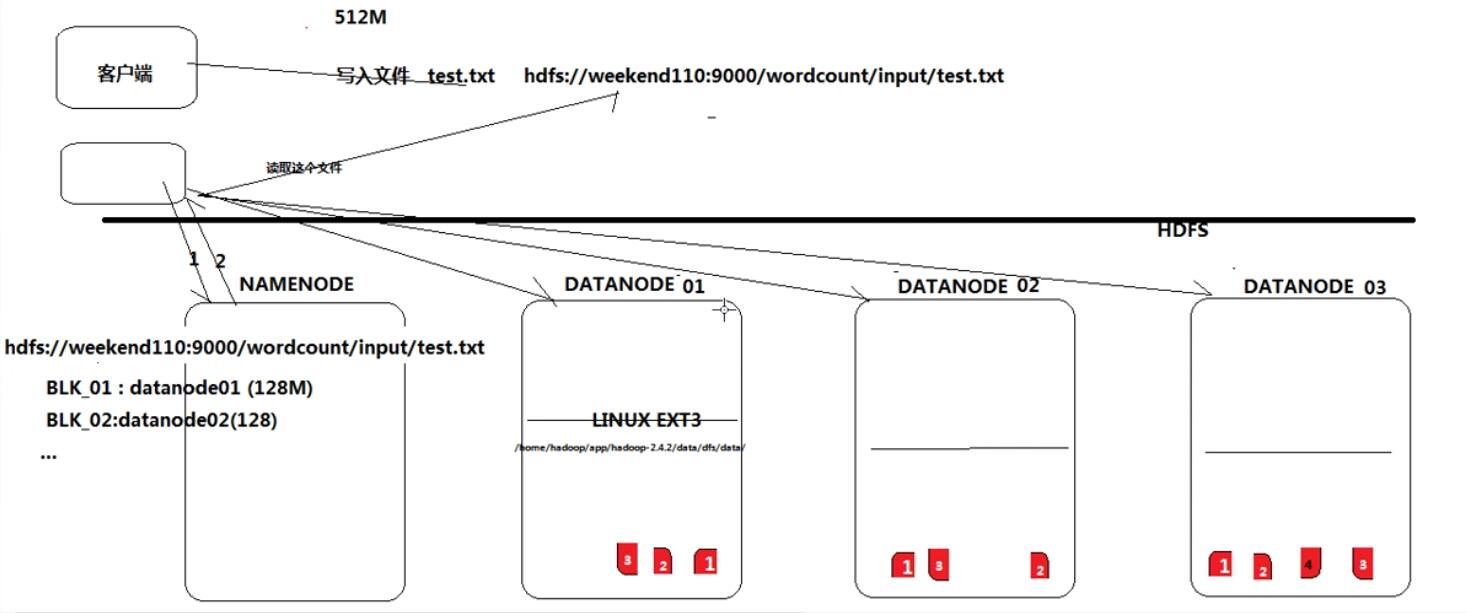
- hdfs是通过分布式集群来存储文件,但为客户端提供了一个便捷的访问方式(一个虚拟的目录结构)
- 文件存储到hdfs集群中去的时候是被切分成block的(由客户端负责切分)
- 文件的block存放在若干台datanode节点上(由hdfs负责拷贝和互传,拷贝出来的第一个副本会优先放在另一个机架上)
- hdfs文件系统中的文件与真实的block之间的映射关系,用namenode管理
- 每一个block在集群中会存储多个副本,可以提高数据的可靠性和访问的吞吐量,提高并发能力
Hdfs的shell操作
基本跟linux上的shell操作类似。hadoop fs(file system)-xx
最常用的shell指令:
hadoop fs -ls
hadoop fs -cat
hadoop fs -put
hadoop fs -get
试试看查看文件
[thousfeet@node01 mapreduce]$ hadoop fs -ls /
Found 5 items
-rw-r--r-- 1 thousfeet supergroup 5202881 2018-03-23 11:30 /javafx-src.zip
drwxr-xr-x - thousfeet supergroup 0 2018-03-23 15:30 /output
drwx------ - thousfeet supergroup 0 2018-03-23 11:42 /tmp
drwxr-xr-x - thousfeet supergroup 0 2018-03-23 11:42 /user
drwxr-xr-x - thousfeet supergroup 0 2018-03-23 12:08 /wordcount
第二列的 1 表示这个文件在hdfs中的副本数,文件夹是元数据是个虚拟的东西,所以没有副本
Hdfs&MapReduce测试的更多相关文章
- 4 weekend110的hdfs&mapreduce测试 + hdfs的实现机制初始 + hdfs的shell操作 + 无密登陆配置
Hdfs是根/目录,windows是每一个盘符, 1 从Linux里传一个到,hdfs里去 2 从hdfs里下一个到,linux里去 想从hdfs里,下载到linux, 涨知识,记住,hdfs是建 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- HDFS部署测试记录(2019/05)
目录 HDFS部署测试记录 0.HDFS基础知识 1.基本组成结构与文件访问过程 2.NameNode启动时如何维护元数据 3.HDFS文件上传流程 1.系统环境 1.安装大致记录: 2.磁盘分区 3 ...
- Alluxio+HDFS+MapReduce集成及测试
目录 1.在 HDFS 上配置 Alluxio 1.1.节点角色 1.2.软件版本 1.3.准备工作 1.3.1.设置 SSH 免密登录 1.3.2.安装 JDK 1.3.3.安装 Hadoop 1. ...
- 【Hadoop测试程序】编写MapReduce测试Hadoop环境
我们使用之前搭建好的Hadoop环境,可参见: <[Hadoop环境搭建]Centos6.8搭建hadoop伪分布模式>http://www.cnblogs.com/ssslinppp/p ...
- YARN集群的mapreduce测试(六)
两张表链接操作(分布式缓存): ----------------------------------假设:其中一张A表,只有20条数据记录(比如group表)另外一张非常大,上亿的记录数量(比如use ...
- YARN集群的mapreduce测试(五)
将user表计算后的结果分区存储 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryNameN ...
- YARN集群的mapreduce测试(四)
将手机用户使用流量的数据进行分组,排序: 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryN ...
随机推荐
- 发布.net 4.0的站点到IIS7.5下时无法访问
现象: 初始发布.net 4.0站点到IIS7.5下时,各种配置都完毕的情况下依旧无法访问.首页显示站点目录结构(注:开启目录结构访问后会显示这个错误,否则会提示开启),访问次级目录提示:Handle ...
- 基于RedHat6.5的Greenplum环境配置
安装Greenplum的时候遇到了很多坑,在此记录下 欢迎园友补充问题,共同研究解决! 安装说明 1.环境说明 操作系统:Red hat 6.5 64 位 2.配置规范 2.1基本说明 greenpl ...
- 航空公司客户价值分析(KMeans聚类)
PS.图片可能不清楚,代码 数据集都在 https://github.com/xubin97/Data-Mining_exp1 项目介绍: 本案例的目标是客户价值识别,通过航空公司客户数据识别不同价值 ...
- 方法返回多个值参数Out使用的方法
string str; Console.WriteLine("请输入用户名"); string user = Console.ReadLine().ToString(); Cons ...
- MySQL---3、常用命令大全
一.连接MySQL 格式: mysql -h主机地址 -u用户名 -p用户密码 1.例1:连接到本机上的MYSQL. 首先在打开DOS窗口,然后进入目录 mysqlbin,再键入命令mysql -ur ...
- ETL第一篇(Kettle Spoon) 初遇
ETL第一篇(Kettle Spoon) 初遇 ETL第二篇 调用webservice 简介 Kettle 是一款国外开源的 ETL 工具,纯 Java 编写,绿色无需安装,数据抽取高效稳定(数据迁移 ...
- 基于SSM框架配置多数据源
项目基于ssm + maven,通过注解可以实现自动切换数据源. 一.pom.xml <?xml version="1.0" encoding="UTF-8&quo ...
- hdu 1026 Ignatius and the Princess I 搜索,输出路径
Ignatius and the Princess I Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (J ...
- MyBatis缓存通俗易懂
1.1 mybatis缓存介绍 如下图,是mybatis一级缓存和二级缓存的区别图解: Mybatis一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的 ...
- Oracle查看表空间容量
select /*+ no_merge */ al.tablespace_name, round(al.currsizemb) currsizemb, round(al.maxsizemb) maxs ...