python爬虫-使用cookie登录
前言:
什么是cookie?
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib库保存我们登录的Cookie,然后再抓取其他页面,这样就达到了我们的目的。
一、Urllib库简介
Urllib是python内置的HTTP请求库,官方地址:https://docs.python.org/3/library/urllib.html
包括以下模块:
>>>urllib.request 请求模块 >>>urllib.error 异常处理模块 >>>urllib.parse url解析模块 >>>urllib.robotparser robots.txt解析模块
二、urllib.request.urlopen介绍
uurlopen一般常用的有三个参数,它的参数如下:
urllib.requeset.urlopen(url,data,timeout)
简单的例子:
1、url参数的使用(请求的URL)
response = urllib.request.urlopen('http://www.baidu.com')
2、data参数的使用(以post请求方式请求)
data= bytes(urllib.parse.urlencode({'word':'hello'}), encoding='utf8')
response= urllib.request.urlopen('http://www.baidu.com/post', data=data)
3、timeout参数的使用(请求设置一个超时时间,而不是让程序一直在等待结果)
response= urllib.request.urlopen('http://www.baidu.com/get', timeout=)
三、构造Requset
1、数据传送POST和GET(举例说明:此处列举登录的请求,定义一个字典为values,参数为:email和password,然后利用urllib.parse.urlencode方法将字典编码,命名为data,构建request时传入两个参数:url、data。运行程序,即可实现登陆。)
GET方式:直接以链接形式访问,链接中包含了所有的参数。
LOGIN_URL= "http://*******/postLogin/" values={'email':'*******@***com','password':'****'} data=urllib.parse.urlencode(values).encode() geturl = LOGIN_URL+ "?"+data request = urllib.request.Request(geturl)
POST方式:上面说的data参数就是用在这里的,我们传送的数据就是这个参数data。
LOGIN_URL='http://******/postLogin/'
values={'email':'*******@***.com','password':'*****'}
data=urllib.parse.urlencode(values).encode()
request=urllib.request.Request(URL,data)
2、设置Headers(有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性)

举例:(这个例子只是说明了怎样设置headers)
user_agent = r'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0'
headers={'User-Agent':user_agent,'Connection':'keep-alive'}
request=urllib.request.Request(URL,data,headers)
四、使用cookie登录
1、获取登录网址
浏览器输入需要登录的网址:'http://*****/login'(注意:这个并非其真实站点登录网址),使用抓包工具fiddler抓包(其他工具也可)找到登录后看到的request。
此处确定需要登录的网址为:'http://*****/postLogin/'

2、查看要传送的post数据
找到登录后的request中有webforms的信息,会列出登录要用的post数据,包括Email,password,auth。
找到登录后看到的request的headers信息,找出User-Agent设置、connection设置等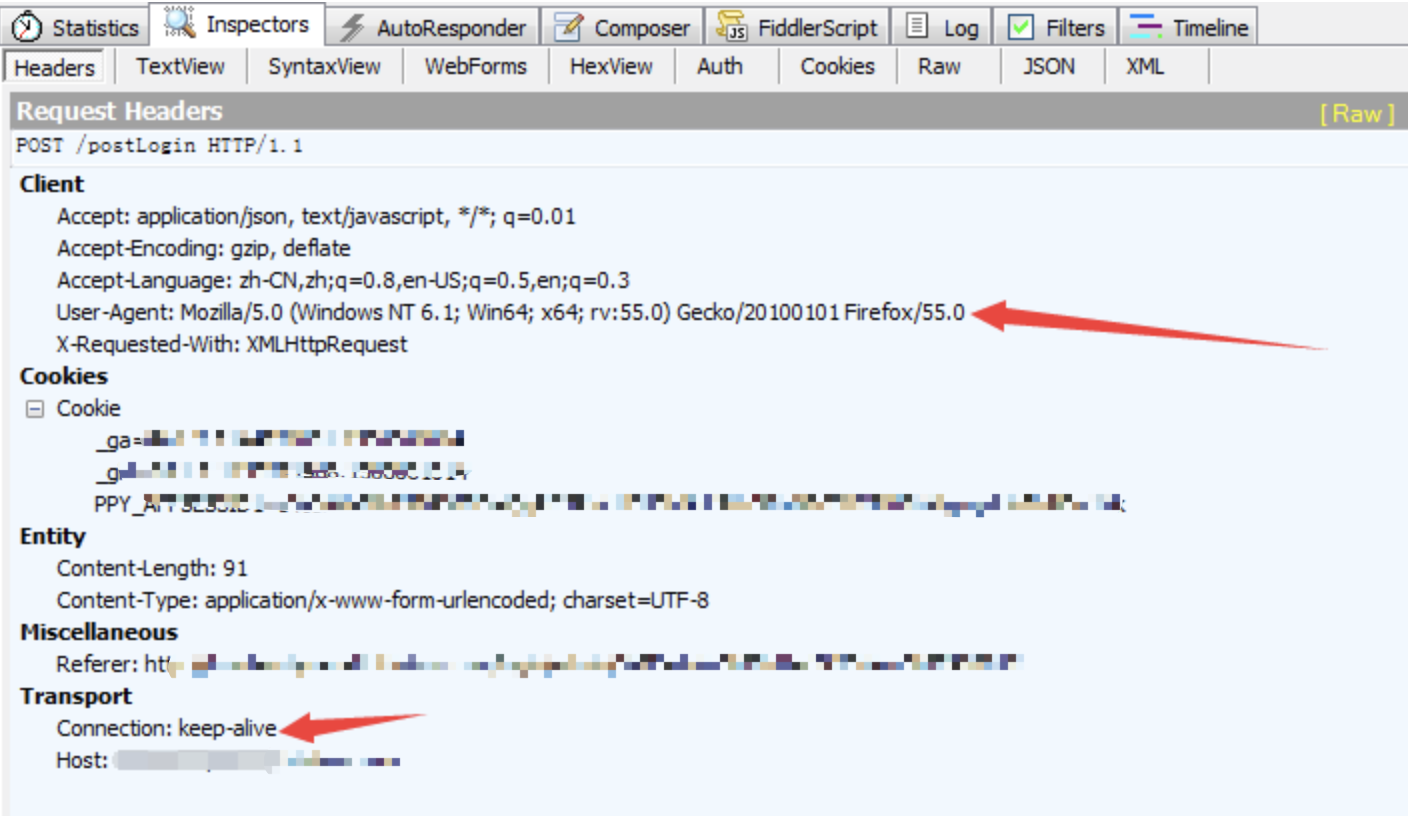
4、开始编码,使用cookie登录该网站
import urllib.error, urllib.request, urllib.parse
import http.cookiejar LOGIN_URL = 'http://******/postLogin'
#get_url为使用cookie所登陆的网址,该网址必须先登录才可
get_url = 'https://*****/pending'
values = {'email':'*****','password':'******','auth':'admin'}
postdata = urllib.parse.urlencode(values).encode()
user_agent = r'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36' \
r' (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36'
headers = {'User-Agent':user_agent, 'Connection':'keep-alive'}
#将cookie保存在本地,并命名为cookie.txt
cookie_filename = 'cookie.txt'
cookie_aff = http.cookiejar.MozillaCookieJar(cookie_filename)
handler = urllib.request.HTTPCookieProcessor(cookie_aff)
opener = urllib.request.build_opener(handler) request = urllib.request.Request(LOGIN_URL, postdata, headers)
try:
response = opener.open(request)
except urllib.error.URLError as e:
print(e.reason) cookie_aff.save(ignore_discard=True, ignore_expires=True) for item in cookie_aff:
print('Name ='+ item.name)
print('Value ='+ item.value)
#使用cookie登陆get_url
get_request = urllib.request.Request(get_url,headers=headers)
get_response = opener.open(get_request)
print(get_response.read().decode())
5、反复使用cookie登录
(上面代码中我们保存cookie到本地了,以下代码我们能够直接从文件导入cookie进行登录,不用再构建request了)
import urllib.request, urllib.parse
import http.cookiejar get_url = 'https://******/pending'
cookie_filename = 'cookie.txt'
cookie_aff = http.cookiejar.MozillaCookieJar(cookie_filename)
cookie_aff.load(cookie_filename,ignore_discard=True,ignore_expires=True) handler = urllib.request.HTTPCookieProcessor(cookie_aff)
opener = urllib.request.build_opener(handler)
#使用cookie登陆get_url
get_request = urllib.request.Request(get_url)
get_response = opener.open(get_request)
print(get_response.read().decode())
以上
python爬虫-使用cookie登录的更多相关文章
- python爬虫+使用cookie登录豆瓣
2017-10-09 19:06:22 版权声明:本文为博主原创文章,未经博主允许不得转载. 前言: 先获得cookie,然后自动登录豆瓣和新浪微博 系统环境: 64位win10系统,同时装pytho ...
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
- Python爬虫之模拟登录微信wechat
不知何时,微信已经成为我们不可缺少的一部分了,我们的社交圈.关注的新闻或是公众号.还有个人信息或是隐私都被绑定在了一起.既然它这么重要,如果我们可以利用爬虫模拟登录,是不是就意味着我们可以获取这些信息 ...
- Python爬虫-百度模拟登录(一)
千呼万唤屎出来呀,百度模拟登录终于要呈现在大家眼前了,最近比较忙,晚上又得早点休息,这篇文章写了好几天才完成.这个成功以后,我打算试试百度网盘的其他接口实现.看看能不能把服务器文件上传到网盘,好歹也有 ...
- python爬虫-知乎登录
#!/usr/bin/env python3 # -*- coding: utf-8 -*- ''' Required - requests (必须) - pillow (可选) ''' import ...
- python爬虫之Cookie
由于http协议是无状态协议(假如登录成功,当访问该网站的其他网页时,登录状态消失),此时,需要将会话信息保存起来,通过cookie或者session的方式 cookie 将所有的回话信息保存在客户端 ...
- Python爬虫之Cookie和Session
关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可能很多人直接回答也不好说的特别清楚,所以整理这样一篇文章,也帮助自己加深理解 什么 ...
- Python爬虫之关于登录那些事
常见的登录方式有以下两种: 查看登录页面,csrf,cookie;授权:cookie 直接发送post请求,获取cookie 上面只是简单的描述,下面是详细的针对两种登录方式的时候爬虫的处理方法 第一 ...
- Python 爬虫之模拟登录
最近应朋友要求,帮忙爬取了小红书创作平台的数据,感觉整个过程很有意思,因此记录一下.在这之前自己没怎么爬过需要账户登录的网站数据,所以刚开始去看小红书的登录认证时一头雾水,等到一步步走下来,最终成功, ...
随机推荐
- 027.1 反射技术 Class
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性:这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反 ...
- vultr vps(ubuntu)忘记密码
参考官方解决方案:https://www.vultr.com/docs/boot-into-single-user-mode-reset-root-password 在此仅给出ubuntu下的解决 D ...
- Moleskine智能笔+专用本:写完随时传到手机
http://www.totiot.com/61805.html Moleskine公司生产的速写本和速写板一直是涂鸦爱好者和速记员们的首选.该公司还联合Adobe. Livescribe. Ever ...
- Qt5中运行后台网络读取线程与主UI线程互交
项目中有一个需求就是,因为需要请求服务端数据,因为网络的读取会阻塞,所以该过程不能放在Qt中的UI主线程当中,需要用一个后台线程来读取数据,数据准备完毕后 在通过Qt5中的信号槽机制来跨线程的传递数据 ...
- STL 1–迭代器std::begin()和std::end()使用
迭代器是一个行为类似于指针的模板类对象.只需要迭代器iter指向一个有效对象,就可以通过使用*iter解引用的方式来获取一个对象的引用.通常会使用一对迭代器来定义一段元素,可以是任意支持迭代器对象的元 ...
- Jquery分页组件
最近工作不是很忙,所以就看看淘宝kissy分页组件源码,感觉代码也不怎么难 容易理解,所以就按照他们的思路自己重新理一遍,来加深自己对他们的理解,同时对他们的分页组件进行一些重构(因为他们分页是做好了 ...
- opencv7-ml之KNN
准备知识 在文件"opencv\sources\modules\ml\src\precomp.hpp"中 有cvPrepareTrainData的函数原型. int cvPrepa ...
- 基于树莓派3的CAN总线编程
基于树莓派3的CAN总线编程 原创 2016年09月08日 10:16:13 标签: 树莓派3 / MCP2515 / CAN总线 / python / 命令行 5254 简介 树莓派3使用Pytho ...
- Ubuntu忘记密码的解决办法
ubuntu忘记root密码怎么办?如果普通用户忘记了怎么办 第一种方法: 无论你是否申请了root帐号,或是普通账号密码忘记了都没有问题的! 1.重启ubuntu,随即长按shift进入grub菜单 ...
- VBA删除 语法
Option Explicit '清空数据 Private Sub CommandButton1_Click() Dim qknum As Integer '选择是或者否 来确认删除数据 '中对话 ...