Python爬虫之关于登录那些事
常见的登录方式有以下两种:
- 查看登录页面,csrf,cookie;授权;cookie
- 直接发送post请求,获取cookie
上面只是简单的描述,下面是详细的针对两种登录方式的时候爬虫的处理方法
第一种情况
这种例子其实也比较多,现在很多网站的登录都是第一种的方法,这里通过以github为例子:
分析页面
获取authenticity_token信息
我们都知道登录页面这里都是一个form表单提交,我可以可以通过谷歌浏览器对其进行分析
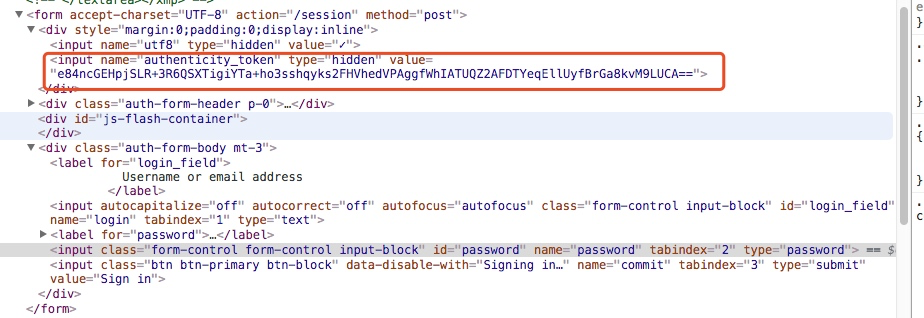
如上图我们找到了这个token信息
所以我们在登录之前应该先通过代码访问这个登录页面获取这个authenticity_token信息
获取登陆页面的cookie信息
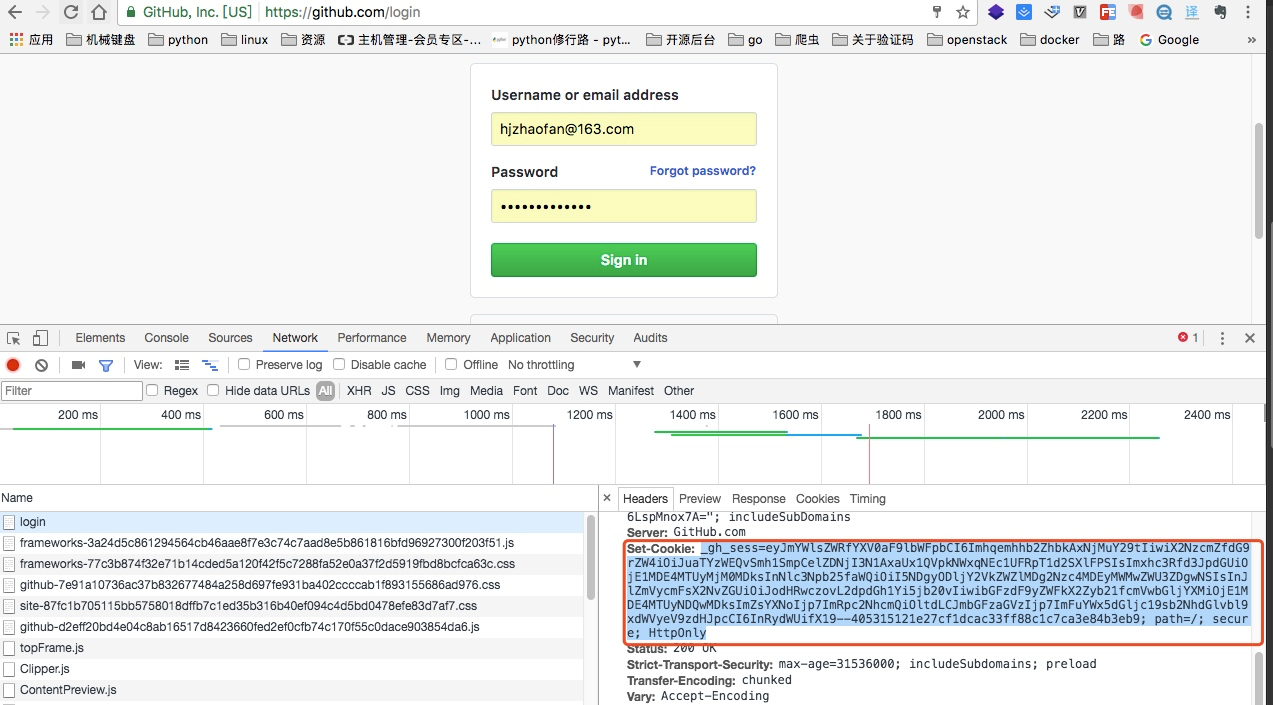
set-cookie这里是登录页面的cookie
分析登录包获取提交地址
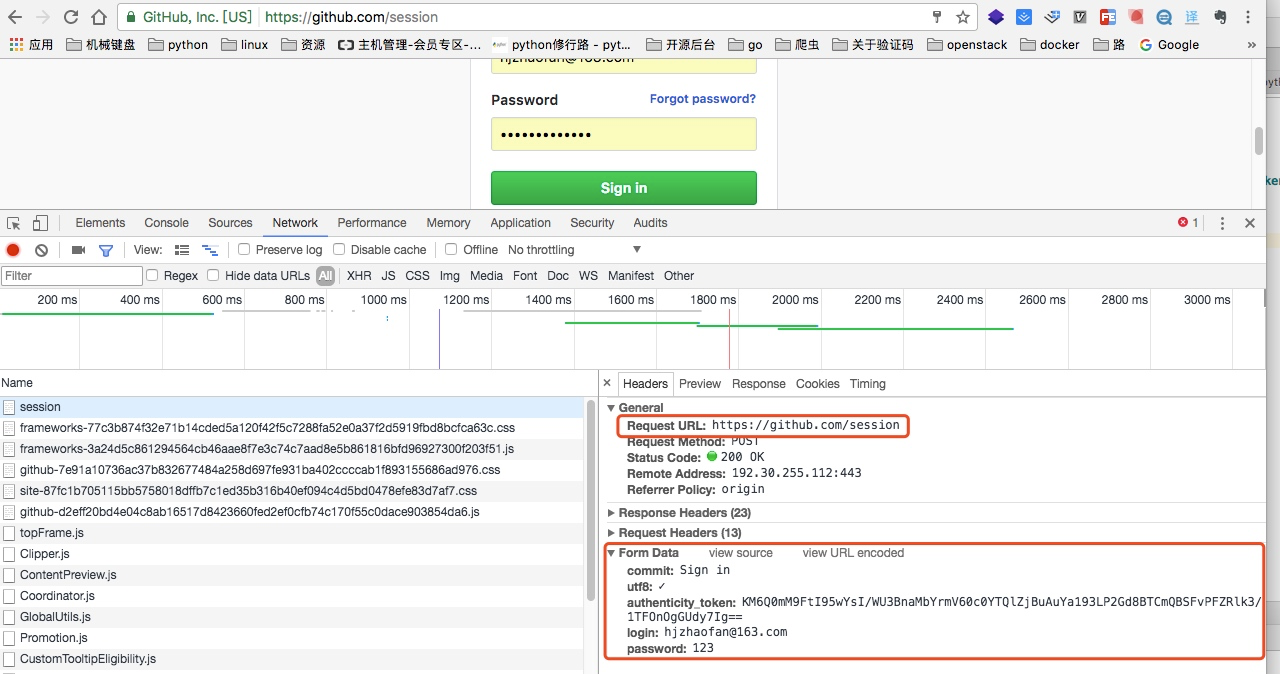
当我们输入用户名和密码之后点击提交,我们可以从包里找到如上图的地址,就是post请求提交form的信息
请求的地址:https://github.com/session
请求的参数有:
"commit": "Sign in",
"utf8":"✓",
"authenticity_token":“KM6Q0mM9FtI95wYsI/WU3BnaMbYrmV60c0YTQlZjBuAuYa193LP2Gd8BTCmQBSFvPFZRlk3/1TFOnOgGUdy7Ig==”,
"login":"hjzhaofan@163.com",
"password":"123"
从这里我们也可以看出提交参数中的“authenticity_token”,而这个参数就是需要我们从登陆页面先获取到。
当我们登录成功后:

再次访问github,这个时候cookie里就增加了两个cookie信息,而这个信息是登录后在增加的信息
所以如果我们想要通过程序登录,我们就需要在登录成功后再次获取cookie信息
然后通过这个cookie去访问我们github的其他信息例如我们的个人信息设置页面:
https://github.com/settings/profile
代码实现
下面代码实现了登录并访问https://github.com/settings/repositories

import requests
from bs4 import BeautifulSoup Base_URL = "https://github.com/login"
Login_URL = "https://github.com/session" def get_github_html(url):
'''
这里用于获取登录页的html,以及cookie
:param url: https://github.com/login
:return: 登录页面的HTML,以及第一次的cooke
'''
response = requests.get(url)
first_cookie = response.cookies.get_dict()
return response.text,first_cookie def get_token(html):
'''
处理登录后页面的html
:param html:
:return: 获取csrftoken
'''
soup = BeautifulSoup(html,'lxml')
res = soup.find("input",attrs={"name":"authenticity_token"})
token = res["value"]
return token def gihub_login(url,token,cookie):
'''
这个是用于登录
:param url: https://github.com/session
:param token: csrftoken
:param cookie: 第一次登录时候的cookie
:return: 返回第一次和第二次合并后的cooke
''' data= {
"commit": "Sign in",
"utf8":"✓",
"authenticity_token":token,
"login":"你的github账号",
"password":"*****"
}
response = requests.post(url,data=data,cookies=cookie)
print(response.status_code)
cookie = response.cookies.get_dict()
#这里注释的解释一下,是因为之前github是通过将两次的cookie进行合并的
#现在不用了可以直接获取就行
# cookie.update(second_cookie)
return cookie if __name__ == '__main__':
html,cookie = get_github_html(Base_URL)
token = get_token(html)
cookie = gihub_login(Login_URL,token,cookie)
response = requests.get("https://github.com/settings/repositories",cookies=cookie)
print(response.text)
第二种情况
这里通过伯乐在线为例子,这个相对于第一种就比较简单了,没有太多的分析过程直接发送post请求,然后获取cookie,通过cookie去访问其他页面,下面直接是代码实现例子:
http://www.jobbole.com/bookmark/ 这个地址是只有登录之后才能访问的页面,否则会直接返回登录页面
这里说一下:http://www.jobbole.com/wp-admin/admin-ajax.php是登录的请求地址这个可以在抓包里可以看到
import requests
def login():
url = "http://www.jobbole.com/wp-admin/admin-ajax.php"
data = {
"action": "user_login",
"user_login":"zhaofan1015",
"user_pass": '******',
}
response = requests.post(url,data)
cookie = response.cookies.get_dict()
print(cookie)
url2 ="http://www.jobbole.com/bookmark/"
response2 = requests.get(url2,cookies=cookie)
print(response2.text) login()
常见的登录方式有以下两种:
- 查看登录页面,csrf,cookie;授权;cookie
- 直接发送post请求,获取cookie
上面只是简单的描述,下面是详细的针对两种登录方式的时候爬虫的处理方法
第一种情况
这种例子其实也比较多,现在很多网站的登录都是第一种的方法,这里通过以github为例子:
分析页面
获取authenticity_token信息
我们都知道登录页面这里都是一个form表单提交,我可以可以通过谷歌浏览器对其进行分析
如上图我们找到了这个token信息
所以我们在登录之前应该先通过代码访问这个登录页面获取这个authenticity_token信息
获取登陆页面的cookie信息
set-cookie这里是登录页面的cookie
分析登录包获取提交地址
当我们输入用户名和密码之后点击提交,我们可以从包里找到如上图的地址,就是post请求提交form的信息
请求的地址:https://github.com/session
请求的参数有:
"commit": "Sign in",
"utf8":"✓",
"authenticity_token":“KM6Q0mM9FtI95wYsI/WU3BnaMbYrmV60c0YTQlZjBuAuYa193LP2Gd8BTCmQBSFvPFZRlk3/1TFOnOgGUdy7Ig==”,
"login":"hjzhaofan@163.com",
"password":"123"
从这里我们也可以看出提交参数中的“authenticity_token”,而这个参数就是需要我们从登陆页面先获取到。
当我们登录成功后:
再次访问github,这个时候cookie里就增加了两个cookie信息,而这个信息是登录后在增加的信息
所以如果我们想要通过程序登录,我们就需要在登录成功后再次获取cookie信息
然后通过这个cookie去访问我们github的其他信息例如我们的个人信息设置页面:
https://github.com/settings/profile
代码实现
下面代码实现了登录并访问https://github.com/settings/repositories
import requests
from bs4 import BeautifulSoup Base_URL = "https://github.com/login"
Login_URL = "https://github.com/session" def get_github_html(url):
'''
这里用于获取登录页的html,以及cookie
:param url: https://github.com/login
:return: 登录页面的HTML,以及第一次的cooke
'''
response = requests.get(url)
first_cookie = response.cookies.get_dict()
return response.text,first_cookie def get_token(html):
'''
处理登录后页面的html
:param html:
:return: 获取csrftoken
'''
soup = BeautifulSoup(html,'lxml')
res = soup.find("input",attrs={"name":"authenticity_token"})
token = res["value"]
return token def gihub_login(url,token,cookie):
'''
这个是用于登录
:param url: https://github.com/session
:param token: csrftoken
:param cookie: 第一次登录时候的cookie
:return: 返回第一次和第二次合并后的cooke
''' data= {
"commit": "Sign in",
"utf8":"✓",
"authenticity_token":token,
"login":"你的github账号",
"password":"*****"
}
response = requests.post(url,data=data,cookies=cookie)
print(response.status_code)
cookie = response.cookies.get_dict()
#这里注释的解释一下,是因为之前github是通过将两次的cookie进行合并的
#现在不用了可以直接获取就行
# cookie.update(second_cookie)
return cookie if __name__ == '__main__':
html,cookie = get_github_html(Base_URL)
token = get_token(html)
cookie = gihub_login(Login_URL,token,cookie)
response = requests.get("https://github.com/settings/repositories",cookies=cookie)
print(response.text)
第二种情况
这里通过伯乐在线为例子,这个相对于第一种就比较简单了,没有太多的分析过程直接发送post请求,然后获取cookie,通过cookie去访问其他页面,下面直接是代码实现例子:
http://www.jobbole.com/bookmark/ 这个地址是只有登录之后才能访问的页面,否则会直接返回登录页面
这里说一下:http://www.jobbole.com/wp-admin/admin-ajax.php是登录的请求地址这个可以在抓包里可以看到
import requests
def login():
url = "http://www.jobbole.com/wp-admin/admin-ajax.php"
data = {
"action": "user_login",
"user_login":"zhaofan1015",
"user_pass": '******',
}
response = requests.post(url,data)
cookie = response.cookies.get_dict()
print(cookie)
url2 ="http://www.jobbole.com/bookmark/"
response2 = requests.get(url2,cookies=cookie)
print(response2.text) login()
Python爬虫之关于登录那些事的更多相关文章
- Python爬虫之模拟登录微信wechat
不知何时,微信已经成为我们不可缺少的一部分了,我们的社交圈.关注的新闻或是公众号.还有个人信息或是隐私都被绑定在了一起.既然它这么重要,如果我们可以利用爬虫模拟登录,是不是就意味着我们可以获取这些信息 ...
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- Python爬虫-百度模拟登录(一)
千呼万唤屎出来呀,百度模拟登录终于要呈现在大家眼前了,最近比较忙,晚上又得早点休息,这篇文章写了好几天才完成.这个成功以后,我打算试试百度网盘的其他接口实现.看看能不能把服务器文件上传到网盘,好歹也有 ...
- python爬虫+使用cookie登录豆瓣
2017-10-09 19:06:22 版权声明:本文为博主原创文章,未经博主允许不得转载. 前言: 先获得cookie,然后自动登录豆瓣和新浪微博 系统环境: 64位win10系统,同时装pytho ...
- Python爬虫实战:爬糗事百科的段子
一个偶然的机会接触了Python,感觉很好用,但是一直在看c++啥的,也没系统学习.用过之后也荒废了许久.之前想建个公众号自动爬糗事百科的段子,但是没能建起来,真是尴尬,代码上传的服务器上之后,不能正 ...
- python爬虫--模拟12306登录
模拟12306登录 超级鹰: #!/usr/bin/env python # coding:utf-8 import requests from hashlib import md5 class Ch ...
- python爬虫-知乎登录
#!/usr/bin/env python3 # -*- coding: utf-8 -*- ''' Required - requests (必须) - pillow (可选) ''' import ...
- python爬虫scrapy之登录知乎
下面我们看看用scrapy模拟登录的基本写法: 注意:我们经常调试代码的时候基本都用chrome浏览器,但是我就因为用了谷歌浏览器(它总是登录的时候不提示我用验证码,误导我以为登录时不需要验证码,其实 ...
随机推荐
- ip白名单 通过* ? 检测IP匹配 轻量级
#include "stdafx.h" #include <windows.h> #include <string.h> #include <asse ...
- 面向对象与基于对象 学习记录 thread举例
/********************************************************************/* @file* @author def< qq gr ...
- 由已打开的文件读取数据---read
头文件:#include<unistd.h> 函数原型:ssize_t read(int fd,void *buf,size_t count); 参数说明:fd:文件描述符 buf:存放读 ...
- JavaScript中的 prototype 和 constructor
prototype属性 任何js函数都可以用作构造函数, 而构造函数需要用到prototype属性, 因此, 每个js函数F(除了ES5的Function.bind()方法返回的函数外) 都自动拥有 ...
- python 文件合并和编号
# -*- coding:utf-8 -*- import os import re p1=r"([0-9][0-9][AB])\.\w{3}$" pattern1=re.comp ...
- Python中的replace方法
replace 方法:返回根据正则表达式进行文字替换后的字符串的复制. stringObj.replace(rgExp, replaceText) 参数 stringObj必选项.要执行该替换的 St ...
- (KMP)Simpsons’ Hidden Talents -- hdu -- 2594
http://acm.hdu.edu.cn/showproblem.php?pid=2594 Simpsons’ Hidden Talents Time Limit: 2000/1000 MS (Ja ...
- (并查集)A Bug's Life -- POJ -- 2492
链接: http://poj.org/problem?id=2492 http://acm.hust.edu.cn/vjudge/contest/view.action?cid=82830#probl ...
- AQS详解(AbstractQueuedSynchronizer)
Intrinsic VS explicity 1. 不一定保证公平 1. 提供公平和非公平的选择 2. 无 2. 提供超时的 ...
- 【NumberValidators】增值税发票代码验证
同大陆身份证验证一样,该部分是按照国家增值税发票代码的定制规则,进行发票代码验证,如果需要查验发票信息是否正确,应该通过第三方接口(大约一毛钱查验一次),或者直接上国家税务总局全国增值税发票查验平台进 ...