mysql监控优化(二)主从复制
复制解决的基本问题是让一台服务器的数据和其他服务器保持同步。一台主服务器的数据可以同步到多台从服务器上。并且从服务器也可以被配置为另外一台服务器的主库。主库和从库之间可以有多种不同的组合方式。
MySQL支持两种复制方案:基于语句的复制(statement-based replication)和基于行的复制(Row-based replication)。基于语句的复制在MySQL3.23就已经存在,它是使用较多的复制方式。基于行的复制是MySQL5.1引入的。这2种复制方式都是通过记录主服务器的二进制日志,并在从服务器进行重放(replay)完成复制。它们都是异步的。也就是说,从服务器上的数据并非都是最新的。
复制通常不会增加主库的开销,主要是启用二进制日志带来的开销,但出于备份戒及时从崩溃中恢复的目的,这些开销是必要的。通过复制可以将读操作指向从库来获得更好的读扩展,但对于写操作,并不适合通过复制来扩展。
1、mysql复制用途
- 分布数据
MySQL通常不会对带宽造成很大的压力。因此可以在不同的地理位置来分布数据,实现跨机房跨地域的数据分布。
- 负载均衡
通过MySQL复制可以将读操作分布到多个服务器上,实现对读密集型应用的优化。
- 备份
复制对备份很有帮助,但是从服务器并不是备份。
- 高可用性和故障转移
复制可以避免在应用程序中出现MySQL失效。好癿故隓转移能显著的减少停机时间,甚至让用户无感知。
- 测试MySQL版本升级
一个常见的方法是先把从服务器升级到MySQL新版本,然后用它来测试查询,确保无异常后再升级主服务器
2、案例:客户投诉:修改了xx信息,提示修改成功。再查看还是旧数据。怎么回事?
很有可能是数据库主从延迟造成的
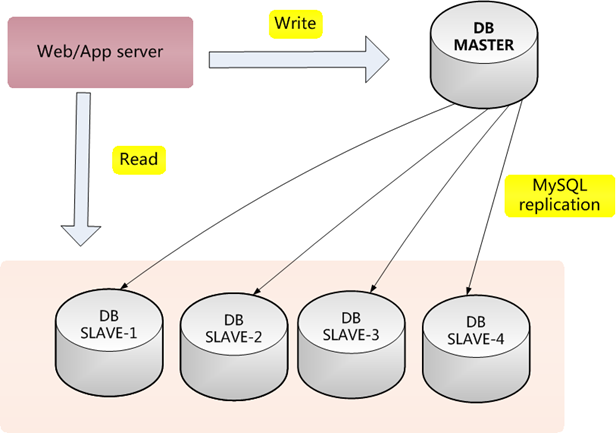
3、MySQL主从延时延时问题如何处理?
1.偶发性延时:控制写入速度,削峰填谷。
2.频发性延时:拆分数据库实现多点写入
3.最后一招:从库磁盘硬件升级为ssd
4、 mysql主从复制的过程是怎样的呢?如下图所示
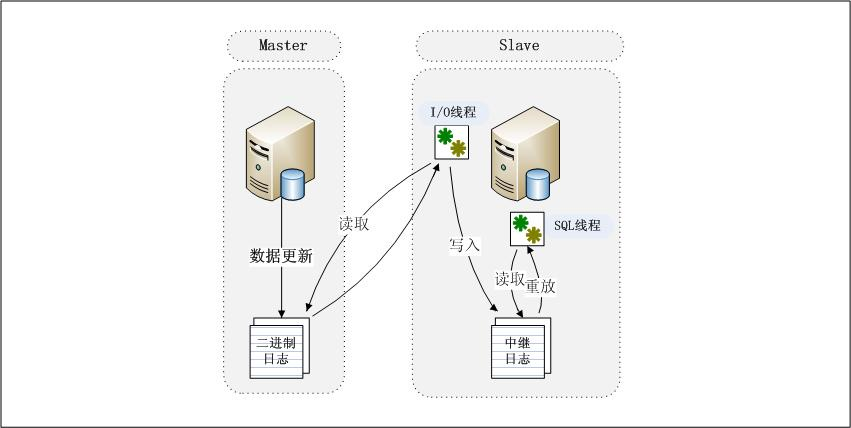
3个线程完成复制:
- 主库1个线程负责记录数据库变更日志
- 从库1个线程负责拉取主库的变更日志
- 从库1个线程负责执行主库的变更日志
- 实现了获取事件和重放事件的解耦,允许异步进行。
- 复制的瓶颈:主库并行(多线程)写入和从库串行(单线程)写入,会造成主从延迟。
mysql监控优化(二)主从复制的更多相关文章
- MySQL性能优化(二):优化数据库的设计
原文:MySQL性能优化(二):优化数据库的设计 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.n ...
- MySql监控优化
MySQL监控 MySQL服务器硬件和OS(操作系统)调优: 1.有足够的物理内存,能将整个InnoDB文件加载到内存里 —— 如果访问的文件在内存里,而不是在磁盘上,InnoDB会快很多. ...
- mysql监控优化(一)连接数和缓存
一.mysql的连接数 MYSQL数据库安装完成后,默认最大连接数是100,一般流量稍微大一点的论坛或网站这个连接数是远远不够的,连接数少的话,在大并发下连接数会不够用,会有很多线程在等待其他连接释放 ...
- [mysql终极优化]之主从复制与读写分离详细设置教程
读写分离与主从复制是提升mysql性能的重要及必要手段,大中型管理系统或网站必用之. 一.什么是读写分离与主从复制 先看图 如上图所示,当web server1/2/3要写入数据时,则向mysql d ...
- mysql性能优化(二)
###> mysql中有一个explain 命令可以用来分析select 语句的运行效果,例如explain可以获得select语句使用的索引情况.排序的情况等等.除此以外,explain 的e ...
- mysql监控优化(三)慢查询
顾名思义,慢查询日志中记录的是执行时间较长的query,也就是我们常说的slowquery,通过设--log-slow-queries[=file_name]来打开该功能并设置记录位置和文件名.慢查询 ...
- Mysql性能优化三(分表、增量备份、还原)
接上篇Mysql性能优化二 对表进行水平划分 如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了.如果我拆成100个表,那么每个表只有10万条记录.当然这需要数据在逻 ...
- 京东MySQL监控之Zabbix优化、自动化
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://wangwei007.blog.51cto.com/68019/1833332 随 ...
- 二十种实战调优MySQL性能优化的经验
二十种实战调优MySQL性能优化的经验 发布时间:2012 年 2 月 15 日 发布者: OurMySQL 来源:web大本营 才被阅读:3,354 次 消灭0评论 本文将为大家介 ...
随机推荐
- Cocos2d-x 3.0final 终结者系列教程07-画图节点Node
在Cocos2d-x中全部能看到的都是引擎调用底层图形库函数绘制完毕的. Cocos2d-x将屏幕全部要绘制的全部内容逻辑上保存到一个场景Scene中(尺寸通常会和屏幕大小一致) 而在Scene中又包 ...
- EF应用一:Code First模式
EF的核心程序集位于System.Data.Entity.dll和System.Data.EntityFramework.dll中.支持CodeFirst的位于EntityFramework.dll中 ...
- 07 Test结构
Test 有多种实现方式, [ 等价于 test, 并且 [ 是一个内建命令, 效率很高 另外, [[]] 也是测试, [[]]结构比bash[]更灵活, 这是一个扩展test命令, 从ksh88继承 ...
- Generator生成器函数
接触过Ajax请求的会遇到过异步调用的问题,为了保证调用顺序的正确性,一般我们会在回调函数中调用,也有用到一些新的解决方案如Promise相关的技术. 在异步编程中,还有一种常用的解决方案,它就是Ge ...
- 关于Web应用程序,下列说法错误的是( )。
关于Web应用程序,下列说法错误的是( ). A.WEB-INF目录存在于web应用的根目录下 B. WEB-INF目录与classes 目录平行 C. web.xml在WEB-INF目录下 D. W ...
- UCASE() 函数
UCASE() 函数 UCASE 函数把字段的值转换为大写. SQL UCASE() 语法 SELECT UCASE(column_name) FROM table_name
- 【NOIP模拟题】“与”(位运算)
因为是与运算,所以我们可以贪心地每次找最高位的,将他们加入到新的序列中,然后每一次在这个新的序列继续找下一个位. 然后最后序列中任意两个的与运算的值都是一样的且是最大的. #include <c ...
- 整理混乱JS代码。
一. 拷贝到MyEclipse的js文件 内然后 Ctrl+Shift+F 自动格式化代码. 二.百度搜索 :格式化js.
- mysql根据查询结果,创建表
create table copy_materials_details (SELECT * FROM `materials_details`);
- Powershell理解汇总
官方帮助文档https://msdn.microsoft.com/zh-cn/powershell/scripting/powershell-scripting 管道/重定向 管道 : 是指把上一条 ...