【转载】Beautiful Soup库(bs4)入门
from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.23us.so/')
html = r.text
soup = BeautifulSoup(html,'html.parser')
print soup.prettify()
from bs4 import BeautifulSoup
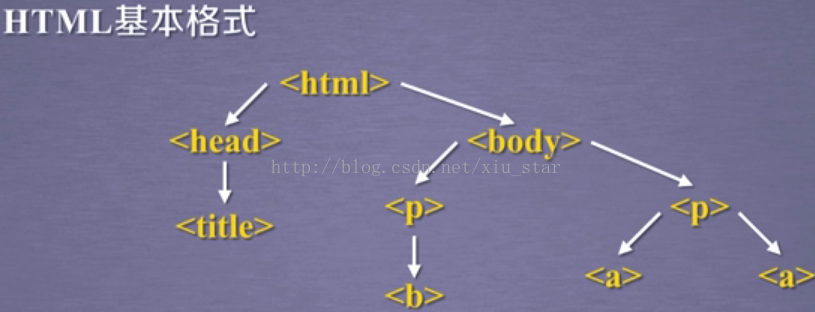
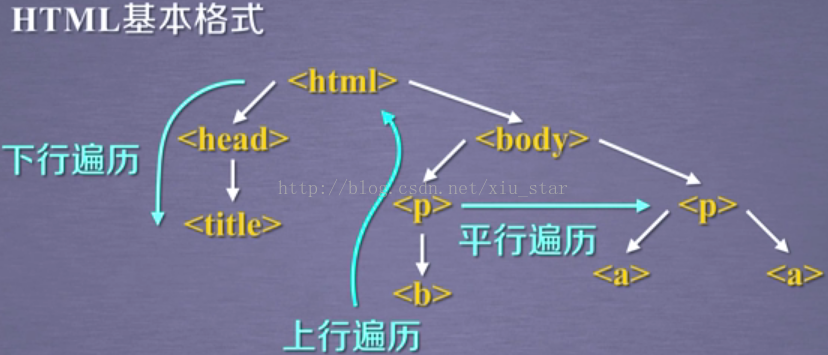
标签树的下行遍历:
- .contents属性:子节点的列表,将<tag>所有儿子节点存入列表
- .children属性:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
- .descendants属性:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
child = soup.body.contents
print(child)
for child in soup.body.descendants:
print(child)
- .parent属性:节点的父标签
- parents属性:节点先辈标签的迭代类型,用于循环遍历先辈节点


from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
print(soup.prettify()) #打印解析好的内容
from bs4 import BeautifulSoup


标签树的下行遍历:
- .contents属性:子节点的列表,将<tag>所有儿子节点存入列表
- .children属性:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
- .descendants属性:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
child = soup.body.contents
print(child)
for child in soup.body.descendants:
- .parent属性:节点的父标签
- parents属性:节点先辈标签的迭代类型,用于循环遍历先辈节点
【转载】Beautiful Soup库(bs4)入门的更多相关文章
- Beautiful Soup库入门
1.安装:pip install beautifulsoup4 Beautiful Soup库是解析.遍历.维护“标签树”的功能库 2.引用:(1)from bs4 import BeautifulS ...
- Beautiful Soup库基础用法(爬虫)
初识Beautiful Soup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/# 中文文档:https://www.crumm ...
- Python Beautiful Soup库
Beautiful Soup库 Beautiful Soup库:https://www.crummy.com/software/BeautifulSoup/ 安装Beautiful Soup: 使用B ...
- crawler碎碎念4 关于python requests、Beautiful Soup库、SQLlite的基本操作
Requests import requests from PIL import Image from io improt BytesTO import jason url = "..... ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- python beautiful soup库的超详细用法
原文地址https://blog.csdn.net/love666666shen/article/details/77512353 参考文章https://cuiqingcai.com/1319.ht ...
- python之Beautiful Soup库
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
- Beautiful Soup库介绍
开始前需安装Beautiful Soup 和lxml. Beautiful Soup在解析时依赖解析器,下表列出bs4支持的解析器. 解析器 使用方法 Python标准库 BeautifulSoup( ...
- Beautiful Soup库
原文传送门:静觅 » Python爬虫利器二之Beautiful Soup的用法
随机推荐
- 【UOJ#188】Sanrd(min_25筛)
[UOJ#188]Sanrd(min_25筛) 题面 UOJ 题解 今天菊开讲的题目.(千古神犇陈菊开,扑通扑通跪下来) 题目要求的就是所有数的次大质因子的和. 这个部分和\(min\_25\)筛中枚 ...
- BZOJ1072 排列perm 【状压dp】
Description 给一个数字串s和正整数d, 统计s有多少种不同的排列能被d整除(可以有前导0).例如123434有90种排列能 被2整除,其中末位为2的有30种,末位为4的有60种. Inpu ...
- 洛谷 P3802 小魔女帕琪 解题报告
P3802 小魔女帕琪 题目背景 从前有一个聪明的小魔女帕琪,兴趣是狩猎吸血鬼. 帕琪能熟练使用七种属性(金.木.水.火.土.日.月)的魔法,除了能使用这么多种属性魔法外,她还能将两种以上属性组合,从 ...
- Python3 字典 pop() 方法
Python3 字典 描述 Python 字典 pop() 方法删除字典给定键 key 所对应的值,返回值为被删除的值.key值必须给出. 否则,返回default值. 语法 pop()方法语法: ...
- 洛谷P3740 [HAOI2014]贴海报
题目描述 Bytetown城市要进行市长竞选,所有的选民可以畅所欲言地对竞选市长的候选人发表言论.为了统一管理,城市委员会为选民准备了一个张贴海报的electoral墙. 张贴规则如下: electo ...
- UVA-10791 数学
UVA-10791 题意: 输入n (1<=n<2^31) 求至少两个正整数使得他们的lcm等于n并且他们的和最小,输出最小和 代码: // a*b=lcm*gcd => a=lcm ...
- base64解码
网络传输经常用base64编码的数据,因此我们需要将其解码成正常字符集合. base64.h #ifdef __cplusplus extern "C" { #endif char ...
- LeetCode-Insertion Sort List[AC源码]
package com.lw.leet5; /** * @ClassName:Solution * @Description: * Insertion Sort List * Sort a linke ...
- 部署维护docker环境
其实前面已经用salt,安装部署了docker应用环境了,过程中还是遇到了不少问题,所以这里再相对仔细的记录一下,docker手机安装过程应注意的事情 安装过程部分参考了刘天斯大师文档部署 1,安装环 ...
- LintCode 156: Merge Interval
LintCode 156: Merge Interval 题目描述 给出若干闭合区间,合并所有重叠的部分. 样例 给出的区间列表 => 合并后的区间列表: [ [ [1, 3], [1, 6], ...