Beautiful Soup库入门
1.安装:pip install beautifulsoup4
Beautiful Soup库是解析、遍历、维护“标签树”的功能库
2.引用:(1)from bs4 import BeautifulSoup (2)import bs4
BeautifulSoup对应一个HTML/XML文档的全部内容
3.解析器:(1)html.parser (2)lxml pip install lxml (3)html5lib pip install html5lib
4.BeautifulSoup类的基本元素: <p class = "title">...</p>
| Tag | 标签,最基本的信息组成单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字,<p>...</p>的名字是'P',格式:<tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:<tag>.attrs |
| NavigableString | 标签内非属性字符串,<>...</>中字符串,格式:<tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
5.BeabutifulSoup类型是标签树的根节点
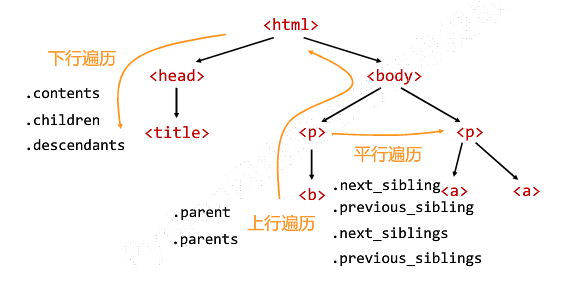
(1)标签树的下行遍历:
| .contents | 子节点的列表,将<tag>所有儿子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
(2)标签树的上行遍历:
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
(3)标签树的平行遍历:
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
上行遍历需判断是否为本身(例下:)
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
6.bs4库的prettify()方法:
| .prettify()为HTML文本<>及其内容增加更加'\n' | |
| .prettify()可用于标签,方法:<tag>.prettify() |
bs4库将任何HTML输入都变成utf-8编码
7.信息标记的三种形式:XML JSON YAML
信息提取的一般方法:
方法一:完整解析信息的标记形式,再提取关键信息 方法二:无视标记形式,直接搜索关键信息
融合方法:结合形式解析与搜索方法,提取关键信息
8.HTML内容查找方法:<>.find_all(name, attrs, recursive, string, **kwargs)
| name | 对标签名称的检索字符串 |
| attrs | 对标签属性值的检索字符串,可标注属性检索 |
| recursive | 是否对子孙全部检索,默认True |
| string | <>...</>中字符串区域的检索字符串 |
<tag>(...) 等价于 <tag>.find_all(..) soup(..) 等价于 soup.find_all(..)
| <>.find() | 搜索且只返回一个结果,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,同.find()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,同.find()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,同.find()参数 |
Beautiful Soup库入门的更多相关文章
- python Beautiful Soup库入门
bs4库的HTML内容遍历方法 基于bs4库的HTML格式输出 显示:友好的显示 <tag>.prettify() 编码:bs4库将任何HTML输入都变成utf-8编码(python 3. ...
- 【转载】Beautiful Soup库(bs4)入门
转载自:Beautiful Soup库(bs4)入门 该库能够解析HTML和XML 使用Beautiful Soup库: from bs4 import BeautifulSoup impo ...
- Beautiful Soup库基础用法(爬虫)
初识Beautiful Soup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/# 中文文档:https://www.crumm ...
- Python Beautiful Soup库
Beautiful Soup库 Beautiful Soup库:https://www.crummy.com/software/BeautifulSoup/ 安装Beautiful Soup: 使用B ...
- python beautiful soup库的超详细用法
原文地址https://blog.csdn.net/love666666shen/article/details/77512353 参考文章https://cuiqingcai.com/1319.ht ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- python之Beautiful Soup库
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
- Beautiful Soup库介绍
开始前需安装Beautiful Soup 和lxml. Beautiful Soup在解析时依赖解析器,下表列出bs4支持的解析器. 解析器 使用方法 Python标准库 BeautifulSoup( ...
- Beautiful Soup库
原文传送门:静觅 » Python爬虫利器二之Beautiful Soup的用法
随机推荐
- iOS开源库分类
语言库 rx aop kvo 功能库 UI network data-model-map cache 跨平台库 wkjscorebridge jspatch 性能监控库:友盟 部署库:jspathc ...
- Linux中的磁盘练习
查看磁盘接口类型 ide dh[a-z] scsi sd[a-z] 添加磁盘 先添加一个磁盘 cd /dev/ ls sd* 可以看到先添加的磁盘 磁盘分区 .fdisk /dev/sdb n (添加 ...
- Euclid`s Game
题目 给定两个整数 a 和 b,Stan和Ollie轮流从较大的数字中减去较小的数的倍数.这里的倍数是指1倍.2倍这样的整数倍,并且相减后的结果不能小于0.Stan先手,在自己的回合将其中一个数变成零 ...
- GuGuFishtion HDU - 6390 (欧拉函数,容斥)
GuGuFishtion \[ Time Limit: 1500 ms\quad Memory Limit: 65536 kB \] 题意 给出定义\(Gu(a, b) = \frac{\phi(ab ...
- UFUN 函数 UF_UI UF_DISP函数( UF_UI_select_with_class_dialog 、UF_DISP_set_highlight)
//设置class_dialog选择过滤 static int init_proc(UF_UI_selection_p_t select,void* user_data) { //过滤类别的个数 ; ...
- Jupyter的快捷键使用
命令模式 (按键 Esc 开启) Enter : 转入编辑模式 Shift-Enter : 运行本单元,选中下个单元 Ctrl-Enter : 运行本单元 Alt-Enter : 运行本单元,在其下插 ...
- datetime.now()提示没有now方法
py3.6 导入方法是 from datetime import datetime 在使用datetime.now()的时候报错,说没有now 在保存module的create_time字段的时候,提 ...
- 为什么学习JavaScript设计模式,因为它是核心
那么什么是设计模式呢?当我们在玩游戏的时候,我们会去追求如何最快地通过,去追求获得已什么高效率的操作获得最好的奖品:下班回家,我们打开手机app查询最便捷的路线去坐车:叫外卖时候,也会找附近最近又实惠 ...
- Xcode9/iOS 11 无线调试方法
1.确保手机已经升级到 iOS 11 ,Xcode 已经升级到 9.0 版本,用手机连接电脑,打开 Xcode 选择路径如下图 2.勾选 Connect via network ,勾选之后拔掉手机. ...
- 【CSP模拟赛】Freda的旗帜
题目描述 要开运动会了,Freda承担起了制作全校旗帜的工作.旗帜的制作方法是这样的:Freda一共有C种颜色的布条,每种布条都有无数个,你可以认为这些布条的长.宽.厚都相等,只有颜色可能不同.每个 ...