【SQL查询】分区查询Over
1. Over介绍
Over为开窗函数。就是把满足条件的数据分成几个区域,每个区域可以通过像现实中的“窗口”来观察统计这些数据。
over不能单独使用,要和分析函数:rank(), dense_rank(), row_number(),ntile()等一起使用。
2. 示例
(1)脚本
/* 表结构*/
CREATE TABLE student(
no int,
ca varchar(20),
name varchar(50),
subject varchar(50),
scorce int
); /* 数据 */
INSERT INTO student VALUES(1, '1班', '张三', '语文', 85);
INSERT INTO student VALUES(2, '1班', '张三', '数学', 90);
INSERT INTO student VALUES(3, '1班', '张三', '英语', 70);
INSERT INTO student VALUES(4, '1班', '李四', '语文', 70);
INSERT INTO student VALUES(5, '1班', '李四', '数学', 99);
INSERT INTO student VALUES(6, '1班', '李四', '英语', 62);
INSERT INTO student VALUES(7, '1班', '王五', '语文', 82);
INSERT INTO student VALUES(8, '1班', '王五', '数学', 74);
INSERT INTO student VALUES(9, '1班', '王五', '英语', 89);
INSERT INTO student VALUES(10, '2班', '刘晓希', '语文', 77);
INSERT INTO student VALUES(11, '2班', '刘晓希', '数学', 99);
INSERT INTO student VALUES(12, '2班', '刘晓希', '英语', 80);
INSERT INTO student VALUES(13, '2班', '朱鹏', '语文', 87);
INSERT INTO student VALUES(14, '2班', '朱鹏', '数学', 86);
INSERT INTO student VALUES(15, '2班', '朱鹏', '英语', 76);
INSERT INTO student VALUES(16, '2班', '欧阳雪', '语文', 91);
INSERT INTO student VALUES(17, '2班', '欧阳雪', '数学', 83);
INSERT INTO student VALUES(18, '2班', '欧阳雪', '英语', 77);
commit;
(2)Rank(排名):
select t.*, rank() over(partition by t.subject order by t.scorce desc) as paiming from student t;
按照科目进行分区,每个区域按照分数进行排序,并得出排序结果的排名号。rank()是跳跃排序,有两个第1名,接下来就是第3名。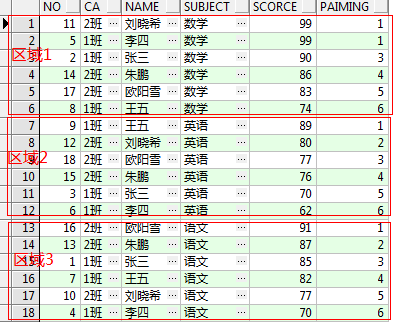
(2)Dense_Rank(密集排名)
select t.*,dense_rank() over(partition by t.subject order by t.scorce desc) as paiming from student t;
按照科目进行分区,每个区域按照分数进行排序,并得出排序结果的排名号。dense_rank()为连续排序,有两个第1名,接下来就是第2名。
(3)row_number(行号)
select t.*,row_number() over(partition by t.subject order by t.scorce desc) as num from student t;
按照科目进行分区,每个区域按照分数进行排序,并得出排序结果的序号。
【SQL查询】分区查询Over的更多相关文章
- 50种方法优化SQL Server数据库查询
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 ...
- 优化SQL Server数据库查询方法
SQL Server数据库查询速度慢的原因有很多,常见的有以下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列 ...
- 转载 50种方法优化SQL Server数据库查询
原文地址 http://www.cnblogs.com/zhycyq/articles/2636748.html 50种方法优化SQL Server数据库查询 查询速度慢的原因很多,常见如下几种: 1 ...
- oracle表空间表分区详解及oracle表分区查询使用方法(转+整理)
欢迎和大家交流技术相关问题: 邮箱: jiangxinnju@163.com 博客园地址: http://www.cnblogs.com/jiangxinnju GitHub地址: https://g ...
- SQL Fundamentals: 子查询 || 分析函数(PARTITION BY,ORDER BY, WINDOWING)
SQL Fundamentals || Oracle SQL语言 子查询(基础) 1.认识子查询 2.WHERE子句中使用子查询 3.在HAVING子句中使用子查询 4.在FROM子句中使用子查询 5 ...
- sql优化 慢查询分析
查询速度慢的原因很多,常见如下几种 SQL慢查询分析 转自:https://www.cnblogs.com/firstdream/p/5899383.html 1.没有索引或者没有用到索引(这是查询慢 ...
- Sql server2005 优化查询速度50个方法小结
Sql server2005 优化查询速度50个方法小结 Sql server2005优化查询速度51法查询速度慢的原因很多,常见如下几种,大家可以参考下. I/O吞吐量小,形成了瓶颈效应. ...
- Laravel Query Builder 复杂查询案例:子查询实现分区查询 partition by
案例 案例:Laravel 在文章列表中附带上前10条评论?,在获取文章列表时同时把每个文章的前10条评论一同查询出来. 这是典型分区查询案例,需要根据 comments 表中的 post_id 字段 ...
- SQL性能优化-查询条件与字段分开执行,union代替in与or,存储过程代替union
PS:概要.背景.结语都是日常“装X”,可以跳过直接看优化历程 环境:SQL Server 2008 R2.阿里云RDS:辅助工具:SQL 审计 概要 一个订单列表分页查询功能,单从SQL性能来讲,从 ...
- Linq to SQL 语法查询(链接查询,子查询 & in操作 & join,分组统计等)
Linq to SQL 语法查询(链接查询,子查询 & in操作 & join,分组统计等) 子查询 描述:查询订单数超过5的顾客信息 查询句法: var 子查询 = from c i ...
随机推荐
- 混合开发的大趋势之一React Native与Android联调
转载请注明出处:王亟亟的大牛之路 先安利,有空我都会更,看到的好东西都会放进来:https://github.com/ddwhan0123/Useful-Open-Source-Android 公司某 ...
- eclipse 工程没有build path
项目的.project文件添加: <buildSpec><buildCommand><name>org.eclipse.jdt.core.javabuilder&l ...
- SSH免密码登录Linux
如果两台linux之间交互频繁,但是每次交互如果都需要输入密码,就会很麻烦,通过配置SSH就可以解决这一问题 下面就说下配置流程(下面流程在不同机器上全部操作一边) 1)cd ~到这个目录中 2)ss ...
- Python学习札记(六) Basic3 List和Tuple
参考:List Tuple Note List List是Python中一个很吊的数据结构,类似C语言的数组. 1.定义:listname = [variable 1, v2, v3, ..., vn ...
- 批量操作QT UI中的控件
背景:在一个项目中,可能一个UI中存在大量相同的tablewidget,combobox,label等控件,每种可能有100个,此时想对它们进行同样的操作 方案:(以tablewidget为例,UI中 ...
- 利用Object.defineProperty实现Vue数据双向绑定
body部分很简单,一个输入框和一个展示的div <div> <p>你好,<input id='nickName'></p> <div id=&q ...
- ThinkPHP开发笔记-用户登录注册
1.修改模块配置,Application/当前模块名/Conf/config.php <?php return array( //数据库配置信息 'DB_TYPE' => 'mysql', ...
- TCP_DB_中间件_数据打包格式
ZC: 这里约定的是,C和S之间 传输的TCP数据包的格式 1.TCP数据包 打包格式 1.1.TCP包长度(int32) + TCP包序号(int32) + TCP包类型(int32) + TCP包 ...
- [Vue]使用 vue-i18n 切换中英文
1.引入 vue-i18n import Vue from 'vue' import VueI18n from 'vue-i18n' import merge from 'lodash/merge' ...
- Android系统源代码
Android系统源代码 在线源码网站 1,http://androidxref.com 2,http://www.grepcode.com/ 3,http://www.androidos.net.c ...