golang版并发爬虫
准备爬取内涵段子的几则笑话,先查看网址:http://www.budejie.com/text/
简单分析后发现每页的url呈加1趋势
第一页: http://www.budejie.com/text/1
第二页:http://www.budejie.com/text/2
...
每页的段子:
<a href="/detail-28278217.html"> 内容</a>
<a href="/detail-28270675.html"> 内容</a>
....
所以正则表达式的解释规则是<a href="/detail-\d{8}.html">(?s:(.*?))</a>,第一个分组的内容就是需要的文字。
代码如下:
package main
import (
"fmt"
"regexp"
"strconv"
"net/http"
"log"
"os"
"strings"
) func onespider(n int, ch chan int) {
url := "http://www.budejie.com/text/" + strconv.Itoa(n)
resp, err := http.Get(url)
if err != nil {
log.Fatal("get error")
}
defer resp.Body.Close()
reg, err1 := regexp.Compile(`<a href="/detail-\d{8}.html">(?s:(.*?))</a>`)
if err1 != nil {
log.Fatal("compile error")
}
var respstring string
buf := make([]byte, )
for {
n, _ := resp.Body.Read(buf)
if n == {
break
}
respstring += string(buf[:n])
} cont := reg.FindAllStringSubmatch(respstring, -)
file, _ := os.OpenFile("./爬虫/"+"第"+strconv.Itoa(n)+"页爬虫.txt", os.O_RDWR|os.O_TRUNC|os.O_CREATE, )
defer file.CLose()
var i int
for _, value := range cont {
if len(value[]) < {
continue
}
value[] = strings.Replace(value[], "<br />", "\n", -)
index := strconv.Itoa(i+)
file.Write([]byte("第"+index+"则段:\n"+value[]+"\n\n\n"))
i++
}
ch <- n
}
func Spider(s, e int) {
ch := make(chan int)
for i := s; i <= e; i++ {
go onespider(i, ch)
}
for i := s; i <= e; i++ {
n := <- ch
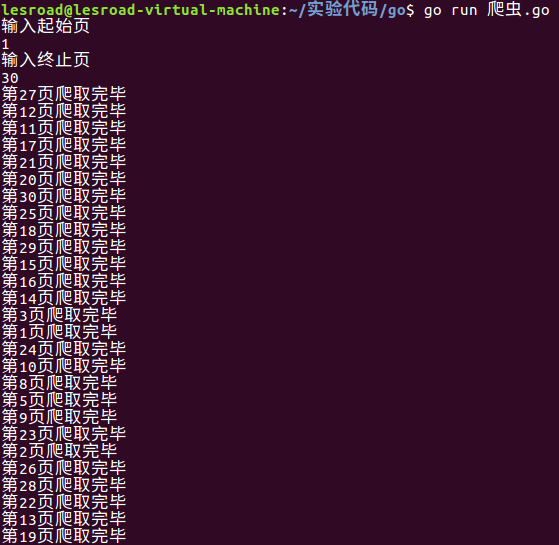
fmt.Printf("第%d页爬取完毕\n", n)
}
}
func main(){
var start, end int
fmt.Println("输入起始页")
fmt.Scan(&start)
fmt.Println("输入终止页")
fmt.Scan(&end)
Spider(start, end)
}
运行截图:
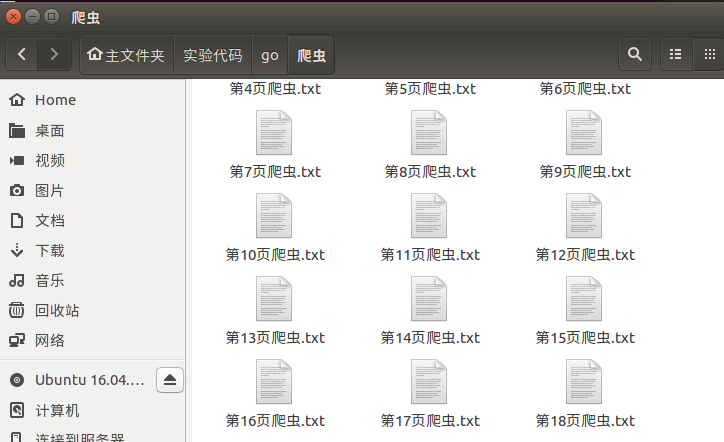
效果截图:
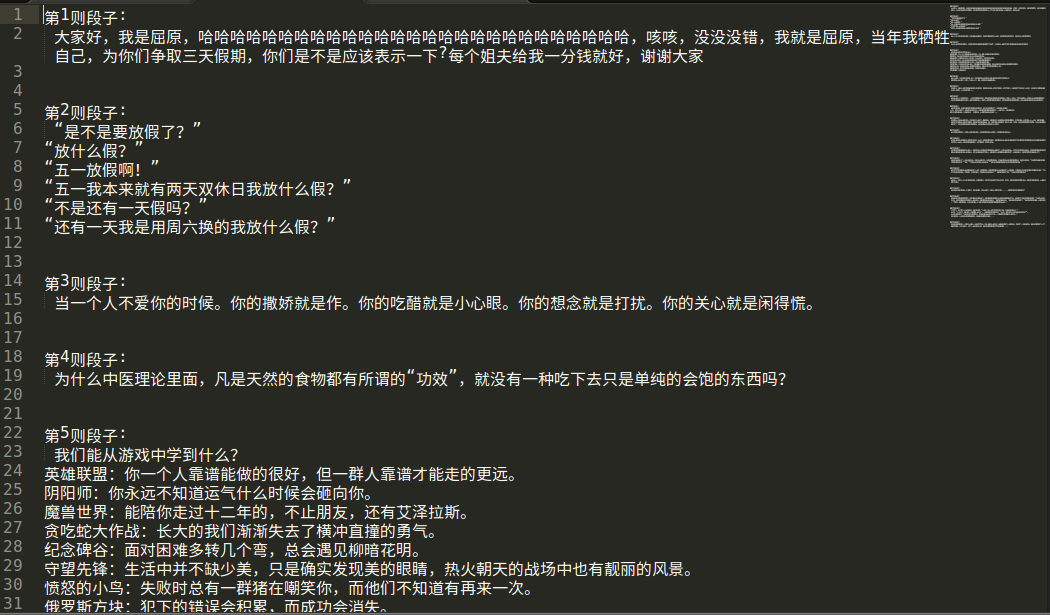
最后我发现第2页之后的段子都是重复的。。。
golang版并发爬虫的更多相关文章
- golang实现并发爬虫三(用队列调度器实现)
欲看此文,必先可先看: golang实现并发爬虫一(单任务版本爬虫功能) gollang实现并发爬虫二(简单调度器) 上文中的用简单的调度器实现了并发爬虫. 并且,也提到了这种并发爬虫的实现可以提高爬 ...
- golang实现并发爬虫一(单任务版本爬虫功能)
目的是写一个golang并发爬虫版本的演化过程. 那么在演化之前,当然是先跑通一下单任务版本的架构. 正如人走路之前是一定要学会爬走一般. 首先看一下单任务版本的爬虫架构,如下: 这是单任务版本爬虫的 ...
- golang实现并发爬虫二(简单调度器)
上篇文章当中实现了单任务版爬虫. 那么这篇文章就大概说下,如何在上一个版本中进行升级改造,使之成为一个多任务版本的爬虫.加快我们爬取的速度. 话不多说,先看图: 其实呢,实现方法就是加了一个sched ...
- golang的并发
Golang的并发涉及二个概念: goroutine channel goroutine由关键字go创建. channel由关键字chan定义 channel的理解稍难点, 最简单地, 你把它当成Un ...
- Golang版protobuf编译
官方网址: https://developers.google.com/protocol-buffers/ (需要FQ) 代码仓库: https://github.com/google/protobu ...
- golang的并发不等于并行
先 看下面一道面试题: func main() { runtime.GOMAXPROCS(1) wg := sync.WaitGroup{} wg.Add(20) for i := 0; i < ...
- [Golang] kafka集群搭建和golang版生产者和消费者
一.kafka集群搭建 至于kafka是什么我都不多做介绍了,网上写的已经非常详尽了. 1. 下载zookeeper https://zookeeper.apache.org/releases.ht ...
- Go语言之进阶篇简单版并发服务器
1.简单版并发服务器 示例1: package main import ( "fmt" "net" "strings" ) //处理用户请求 ...
- swing版网络爬虫-丑牛迷你采集器2.0
swing版网络爬虫-丑牛迷你采集器2.0 http://www.javacoo.com/code/704.jhtml 整合JEECMS http://bbs.jeecms.com/fabu/3186 ...
随机推荐
- 48. Rotate Image(旋转矩阵)
You are given an n x n 2D matrix representing an image. Rotate the image by 90 degrees (clockwise) ...
- 【android】夜间模式简单实现
完整代码,请参考我的博客园客户端,git地址:http://git.oschina.net/yso/CNBlogs 关于阅读类的app,有个夜间模式真是太重要了. 那么有两种方式可以实现夜间模式 1: ...
- ASP.NET MVC5 视图相关学习
MVC Razor模板引擎中3个重要的方法:@RenderBody.@RenderPage.@RenderSection 1.@RenderBody 在Razor引擎中布局页面类似于asp.net中的 ...
- 分布式系统 SOA与中间件
在分布式系统中,有一个基础的理论 CAP,Consistency一致性 Availability可用性 Partition Tolerance分区容忍性,任何一个系统都不可能同时满足这三个条件(高富帅 ...
- redis 简单命令操作
一.概述: 在该系列的前几篇博客中,主要讲述的是与Redis数据类型相关的命令,如String.List.Set.Hashes和Sorted-Set.这些命令都具有一个共同点,即所有的操作都是针对与K ...
- 20145313张雪纯 《Java程序设计》8周学习总结
20145313张雪纯 <Java程序设计>8周学习总结 教材学习内容总结 java.util.logging包的优点在于提供了日志功能相关类与接口,不必额外配置日志组件就可以在标准jav ...
- RocEDU.阅读.写作《乌合之众》(三)
第二卷 群体的意见与信念 第三章 群体领袖及其说服的手法 群体领袖 领袖对于群体十分重要,他是群体形成意见并取得一致的核心.他常常是个实干家而非思想家,信念极其坚定并且有自我牺牲的倾向.领袖具有非常专 ...
- 20145329 《Java程序设计》课程总结
每周读书笔记链接汇总 •第一周读书笔记 http://www.cnblogs.com/jdy1453/p/5248592.html •第二周读书笔记 http://www.cnblogs.com/jd ...
- 20145240《网络对抗》逆向及Bof基础实践
逆向及Bof基础实践 1.1 实践目标 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串. 该程序同时包 ...
- Hive Shell常用操作
1.Hive非交互模式常用命令: 1) hive -e:从命令行执行指定的HQL,不需要分号: % hive -e 'select * from dummy' > a.txt 2) hive – ...