数据挖掘系列(1)关联规则挖掘基本概念与Aprior算法
整理数据挖掘的基本概念和算法,包括关联规则挖掘、分类、聚类的常用算法,敬请期待。今天讲的是关联规则挖掘的最基本的知识。
关联规则挖掘在电商、零售、大气物理、生物医学已经有了广泛的应用,本篇文章将介绍一些基本知识和Aprori算法。
啤酒与尿布的故事已经成为了关联规则挖掘的经典案例,还有人专门出了一本书《啤酒与尿布》,虽然说这个故事是哈弗商学院杜撰出来的,但确实能很好的解释关联规则挖掘的原理。我们这里以一个超市购物篮迷你数据集来解释关联规则挖掘的基本概念:
| TID | Items |
| T1 | {牛奶,面包} |
| T2 | {面包,尿布,啤酒,鸡蛋} |
| T3 | {牛奶,尿布,啤酒,可乐} |
| T4 | {面包,牛奶,尿布,啤酒} |
| T5 | {面包,牛奶,尿布,可乐} |
表中的每一行代表一次购买清单(注意你购买十盒牛奶也只计一次,即只记录某个商品的出现与否)。数据记录的所有项的集合称为总项集,上表中的总项集S={牛奶,面包,尿布,啤酒,鸡蛋,可乐}。
一、关联规则、自信度、自持度的定义
关联规则就是有关联的规则,形式是这样定义的:两个不相交的非空集合X、Y,如果有X-->Y,就说X-->Y是一条关联规则。举个例子,在上面的表中,我们发现购买啤酒就一定会购买尿布,{啤酒}-->{尿布}就是一条关联规则。关联规则的强度用支持度(support)和自信度(confidence)来描述,
支持度的定义:support(X-->Y) = |X交Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数。例如:support({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/数据记录数 = 3/5=60%。
自信度的定义:confidence(X-->Y) = |X交Y|/|X| = 集合X与集合Y中的项在一条记录中同时出现的次数/集合X出现的个数 。例如:confidence({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/啤酒出现的次数=3/3=100%;confidence({尿布}-->{啤酒}) = 啤酒和尿布同时出现的次数/尿布出现的次数 = 3/4 = 75%。
这里定义的支持度和自信度都是相对的支持度和自信度,不是绝对支持度,绝对支持度abs_support = 数据记录数N*support。
支持度和自信度越高,说明规则越强,关联规则挖掘就是挖掘出满足一定强度的规则。
二、关联规则挖掘的定义与步骤
关联规则挖掘的定义:给定一个交易数据集T,找出其中所有支持度support >= min_support、自信度confidence >= min_confidence的关联规则。
有一个简单而粗鲁的方法可以找出所需要的规则,那就是穷举项集的所有组合,并测试每个组合是否满足条件,一个元素个数为n的项集的组合个数为2^n-1(除去空集),所需要的时间复杂度明显为O(2^N),对于普通的超市,其商品的项集数也在1万以上,用指数时间复杂度的算法不能在可接受的时间内解决问题。怎样快速挖出满足条件的关联规则是关联挖掘的需要解决的主要问题。
仔细想一下,我们会发现对于{啤酒-->尿布},{尿布-->啤酒}这两个规则的支持度实际上只需要计算{尿布,啤酒}的支持度,即它们交集的支持度。于是我们把关联规则挖掘分两步进行:
1)生成频繁项集
这一阶段找出所有满足最小支持度的项集,找出的这些项集称为频繁项集。
2)生成规则
在上一步产生的频繁项集的基础上生成满足最小自信度的规则,产生的规则称为强规则。
关联规则挖掘所花费的时间主要是在生成频繁项集上,因为找出的频繁项集往往不会很多,利用频繁项集生成规则也就不会花太多的时间,而生成频繁项集需要测试很多的备选项集,如果不加优化,所需的时间是O(2^N)。
三、Apriori定律
为了减少频繁项集的生成时间,我们应该尽早的消除一些完全不可能是频繁项集的集合,Apriori的两条定律就是干这事的。
Apriori定律1):如果一个集合是频繁项集,则它的所有子集都是频繁项集。举例:假设一个集合{A,B}是频繁项集,即A、B同时出现在一条记录的次数大于等于最小支持度min_support,则它的子集{A},{B}出现次数必定大于等于min_support,即它的子集都是频繁项集。
Apriori定律2):如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。举例:假设集合{A}不是频繁项集,即A出现的次数小于min_support,则它的任何超集如{A,B}出现的次数必定小于min_support,因此其超集必定也不是频繁项集。
利用这两条定律,我们抛掉很多的候选项集,Apriori算法就是利用这两个定理来实现快速挖掘频繁项集的。
四、Apriori算法
Apriori是由a priori合并而来的,它的意思是后面的是在前面的基础上推出来的,即先验推导,怎么个先验法,其实就是二级频繁项集是在一级频繁项集的基础上产生的,三级频繁项集是在二级频繁项集的基础上产生的,以此类推。
Apriori算法属于候选消除算法,是一个生成候选集、消除不满足条件的候选集、并不断循环直到不再产生候选集的过程。
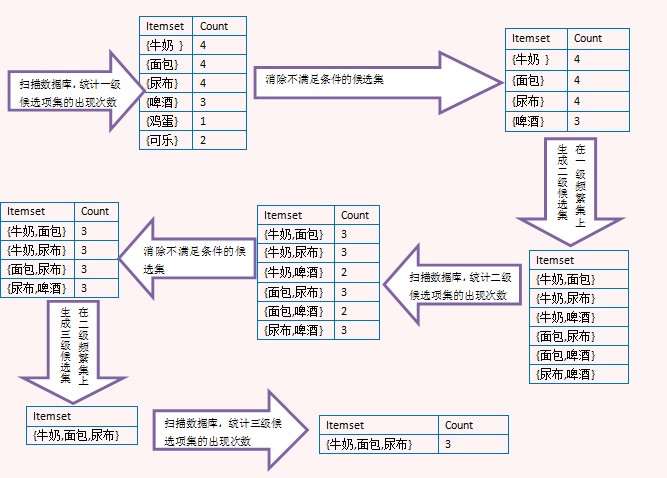
上面的图演示了Apriori算法的过程,注意看由二级频繁项集生成三级候选项集时,没有{牛奶,面包,啤酒},那是因为{面包,啤酒}不是二级频繁项集,这里利用了Apriori定理。最后生成三级频繁项集后,没有更高一级的候选项集,因此整个算法结束,{牛奶,面包,尿布}是最大频繁子集。
算法的思想知道了,这里也就不上伪代码了,我认为理解了算法的思想后,子集去构思实现才能理解更深刻,这里贴一下我的关键代码:

1 public static void main(String[] args) {
2 // TODO Auto-generated method stub
3 record = getRecord();// 获取原始数据记录
4 List<List<String>> cItemset = findFirstCandidate();// 获取第一次的备选集
5 List<List<String>> lItemset = getSupportedItemset(cItemset);// 获取备选集cItemset满足支持的集合
6
7 while (endTag != true) {// 只要能继续挖掘
8 List<List<String>> ckItemset = getNextCandidate(lItemset);// 获取第下一次的备选集
9 List<List<String>> lkItemset = getSupportedItemset(ckItemset);// 获取备选集cItemset满足支持的集合
10 getConfidencedItemset(lkItemset, lItemset, dkCountMap, dCountMap);// 获取备选集cItemset满足置信度的集合
11 if (confItemset.size() != 0)// 满足置信度的集合不为空
12 printConfItemset(confItemset);// 打印满足置信度的集合
13 confItemset.clear();// 清空置信度的集合
14 cItemset = ckItemset;// 保存数据,为下次循环迭代准备
15 lItemset = lkItemset;
16 dCountMap.clear();
17 dCountMap.putAll(dkCountMap);
18 }
如果想看完整的代码,可以查看github,数据集的格式跟本文所述的略有不通,但不影响对算法的理解。
下一篇将介绍效率更高的算法--FP-Grow算法。
参考文献:
[1].Pang-Ning Tan,Michael Steinbach. Introduction to Data Mining.
[2].HanJiaWei. Data Mining: concept and techniques.
转载出处:http://www.cnblogs.com/fengfenggirl/p/associate_apriori.html
数据挖掘系列(1)关联规则挖掘基本概念与Aprior算法的更多相关文章
- 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法
转自:http://www.cnblogs.com/fengfenggirl/p/associate_apriori.html 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法 我计划 ...
- 数据挖掘进阶之关联规则挖掘FP-Growth算法
数据挖掘进阶之关联规则挖掘FP-Growth算法 绪 近期在写论文方面涉及到了数据挖掘,需要通过数据挖掘方法实现软件与用户间交互模式的获取.分析与分类研究.主要涉及到关联规则与序列模式挖掘两块.关联规 ...
- 数据挖掘算法之关联规则挖掘(一)apriori算法
关联规则挖掘算法在生活中的应用处处可见,几乎在各个电子商务网站上都可以看到其应用 举个简单的例子 如当当网,在你浏览一本书的时候,可以在页面中看到一些套餐推荐,本书+有关系的书1+有关系的书2+... ...
- [数据挖掘课程笔记]关联规则挖掘 - Apriori算法
两种度量: 支持度(support) support(A→B) = count(AUB)/N (N是数据库中记录的条数) 自信度(confidence)confidence(A→B) = count ...
- 数据挖掘算法之关联规则挖掘(二)FPGrowth算法
之前介绍的apriori算法中因为存在许多的缺陷,例如进行大量的全表扫描和计算量巨大的自然连接,所以现在几乎已经不再使用 在mahout的算法库中使用的是PFP算法,该算法是FPGrowth算法的分布 ...
- FP-Tree -关联规则挖掘算法(转载)
在关联规则挖掘领域最经典的算法法是Apriori,其致命的缺点是需要多次扫描事务数据库.于是人们提出了各种裁剪(prune)数据集的方法以减少I/O开支 支持度和置信度 严格地说Apriori和FP- ...
- 数据挖掘系列(4)使用weka做关联规则挖掘
前面几篇介绍了关联规则的一些基本概念和两个基本算法,但实际在商业应用中,写算法反而比较少,理解数据,把握数据,利用工具才是重要的,前面的基础篇是对算法的理解,这篇将介绍开源利用数据挖掘工具weka进行 ...
- 数据挖掘系列(5)使用mahout做海量数据关联规则挖掘
上一篇介绍了用开源数据挖掘软件weka做关联规则挖掘,weka方便实用,但不能处理大数据集,因为内存放不下,给它再多的时间也是无用,因此需要进行分布式计算,mahout是一个基于hadoop的分布式数 ...
- 数据挖掘算法之-关联规则挖掘(Association Rule)
在数据挖掘的知识模式中,关联规则模式是比较重要的一种.关联规则的概念由Agrawal.Imielinski.Swami 提出,是数据中一种简单但很实用的规则.关联规则模式属于描述型模式,发现关联规则的 ...
随机推荐
- Android百度地图附加搜索和公交路线方案搜索
合肥程序员群:49313181. 合肥实名程序员群:128131462 (不愿透露姓名和信息者勿加入) Q Q:408365330 E-Mail:egojit@qq.com 综述: 今 ...
- perl基础:传递hash类型参数
1 如果是只有一个参数要传,且是hash,最直接想到的办法就是像传其他类型参数一样直接传, 如: subFuntion(%hash1); 2 如果有多于一个参数要传,这里假设只有一个参数的类型是h ...
- Scala学习 —— 元组&映射
再说集合之前,我们先来回顾一下映射&元祖 映射是键/值对偶的集合,Scala有一个通用的叫法--元组,也就是n个对象的聚集,并不一定要相同类型的.对偶不过是一个n=2的元祖.元祖对于那种需要将 ...
- HTML <div> 标签
定义和用法: <div> 可定义文档中的分区或节(division/section). <div> 标签可以把文档分割为独立的.不同的部分.它可以用作严格的组织工具,并且不使用 ...
- java中this 关键字的使用
在方法中定义使用的this关键字,它的值是当前对象的引用.也就是说你只能用它来调用属于当前对象的方法或者使用this处理方法中成员变量和局部变量重名的情况.而且,更为重要的是this和super都无法 ...
- Android系统的架构
android的系统架构和其操作系统一样,采用了分层的架构.从架构图看,android分为四个层,从高层到低层分别是应用程序层.应用程序框架层.系统运行库层和linux核心层. 1.应用程序 Andr ...
- Ubuntu日常问题搜集和解决办法
搜集了日常工作中linuxmint的使用的命令备份和遇到的问题以及解决办法.(持续更新中) 保持ssh链接超时不自动断开 用ssh链接服务端,一段时间不操作或屏幕没输出(比如复制文件)的时候,会自动断 ...
- 白皮 Chapter 2
7.2 做题一遍就过的感觉简直太美好啦~然而我并没有测试数据QAQ //program name digit #include<cstdio> #include<iostream&g ...
- JavaScript 变量作用域
一. 变量声明 变量用var关键字来声明,如下所示: 变量在未声明的情况下被初始化,会被添加到全局环境. JavaScript执行代码时,会创建一个上下文执行环境,全局环境是最外围的环境.每个函数在被 ...
- C学习
\a:警报 1.exit(),提前结束程序.include <stdlib.h> 2.getch()无缓存.getchar()有缓存,多条连用时注意末尾换行符否则始终.putchar(). ...