or等价改写union SQL案例
同事找我优化一些SQL,其中有个SQL比较经典,拿出来分享给大家,从原来执行2分钟,到1.4S出结果。
-- 原SQL
SELECT
count (*)
FROM (
SELECT
DISTINCT T1.id,
T1.doc_no,
T1.title,
T1.type,
T1.addTime,
T1.urgency,
T1.addUser,
T1.fileNo,
T1.fileNoID,
T1.orgId,
T1.deptId,
T1.fromDept,
T1.docType,
T1.docTypeID,
T1.isOld,
T1.publicState,
T1.oaPublicState,
P.state AS activeState,
P.cate_id AS cateID,
P.id AS procInsID
FROM
A T1,
B P
WHERE
T1.id = P.case_id
AND T1.addTime >= '2021-11-17 00:00:00'
AND T1.addTime <= '2022-11-17 23:59:59'
AND T1.type IN ('receive', 'dispatch', 'draft')
AND (T1.oapublicstate = '1'
OR EXISTS (
SELECT
P.case_id AS wf_case_id
FROM
wf_proc_ins_handlers H
WHERE
P.id = H.proc_ins_id
AND H.handler_id = '704fa12e-0166-1000-e000-05a00a010169'))) x;

这个节点循环了 47108 次,这个节点所需要的时间计算为 47108 * 2.695 = 126,956.06ms ,2分钟,影响了整条SQL的执行时间。
对应的SQL语句是这段
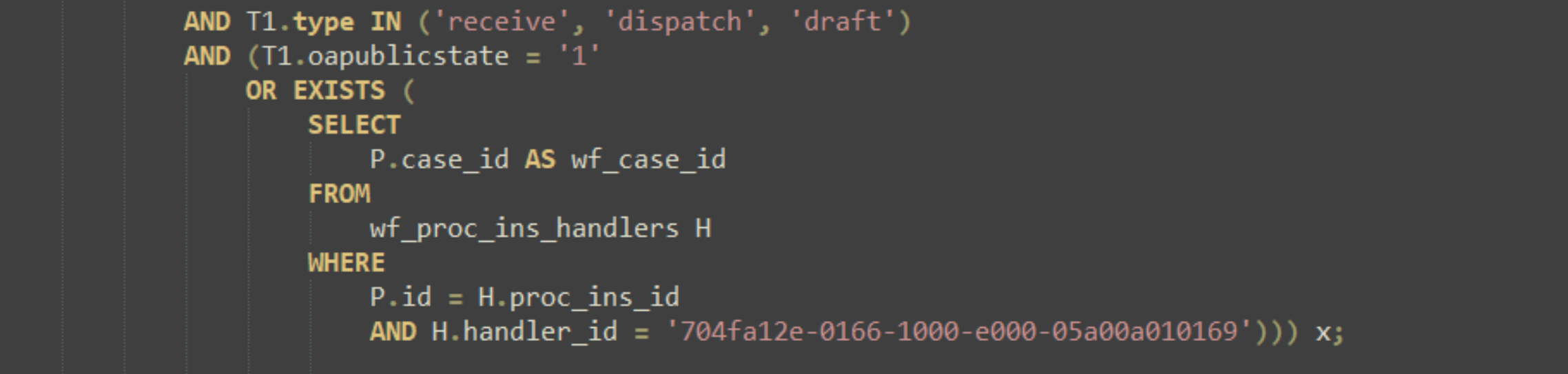
这种语句使用OR 加任何索引都不好使,想要优化只能改写改SQL。
-- 改写SQL优化 with x as (
SELECT
DISTINCT T1.id,
T1.doc_no,
T1.title,
T1.type,
T1.addTime,
T1.urgency,
T1.addUser,
T1.fileNo,
T1.fileNoID,
T1.orgId,
T1.deptId,
T1.fromDept,
T1.docType,
T1.docTypeID,
T1.isOld,
T1.publicState,
T1.oaPublicState,
P.state AS activeState,
P.cate_id AS cateID,
P.id AS procInsID
FROM
A T1,
B P
WHERE
T1.id = P.case_id
AND T1.addTime >= '2021-11-17 00:00:00'
AND T1.addTime <= '2022-11-17 23:59:59'
AND T1.type IN ('receive', 'dispatch', 'draft') )
select count(*) from (
select x1.* from x x1 where x1.oapublicstate = '1'
union
select x2.* from x x2 left join wf_proc_ins_handlers h on x2.procInsID = h.proc_ins_id where h.handler_id = '704fa12e-0166-1000-e000-05a00a010169' and h.proc_ins_id is not null
);
SQL 执行计划

修改之后只需要1.4S 就能出结果,两条语句比较 count(*) 结果集等价。
or等价改写union SQL案例的更多相关文章
- 《Oracle查询优化改写技巧与案例》学习笔记-------使用数字篇
一个系列的读书笔记,读的书是有教无类和落落两位老师编写的<Oracle查询优化改写技巧与案例>. 用这个系列的读书笔记来督促自己学习Oracle,同时,对于其中一些内容,希望大家看到以后, ...
- 《 Oracle查询优化改写 技巧与案例 》电子工业出版社
第1章单表查询 11.1 查询表中所有的行与列 11.2 从表中检索部分行 21.3 查找空值 31.4 将空值转换为实际值 41.5 查找满足多个条件的行 51.6 从表中检索部分列 61.7 为列 ...
- 利用Merge into 改写Update SQL 一例
前言 客户说,生产系统最近CPU使用率经常达到100%,请DBA帮忙调查一下. 根据客户提供的情况描述及对应时间段,我导出AWR,发现如下问题: 11v41vaj06pjd :每次执行消耗2,378, ...
- OR 改写union数据变少
<pre name="code" class="sql">SQL> SELECT deptno FROM emp WHERE mgr = 76 ...
- dense_rank()+hash提示改写优化SQL
数据库环境:SQL SERVER 2005 今天看到一条SQL,返回10条数据,执行了50多S.刚好有空,就对它进行了优化,优化后1S出结果. 先看下原始SQL SELECT t1.line_no , ...
- 性能测试四十二:sql案例之联合索引最左前缀
联合索引:一个索引同时作用于多个字段 联合索引的最左前缀: A.B.C3个字段--联合索引 这个时候,可以使用的查询条件有:A.A+B.A+C.A+B+C,唯独不能使用B+C,即最左侧那个字段必须匹配 ...
- 性能测试四十一:sql案例之慢sql配置、执行计划和索引
MYSQL 慢查询使用方法MYSQL慢查询介绍分析MySQL语句查询性能的问题时候,可以在MySQL记录中查询超过指定时间的语句,我们将超过指定时间的SQL语句查询称为“慢查询”.MYSQL自带的慢查 ...
- pl/sql案例
项目生命周期: 瀑布模型 拿到一个项目后,首先:分析需要用到的SQL语句: 其次:分析需要定义的变量初始值是多少,怎么得到最终值: 案例一: 统计每年入职的员工数量以及总数量: SQL语句:selec ...
- 实际SQL案例解决方法整理_LEAD函数相关
表结构及数据如下: 需求: 将记录按照时间顺序排列,每三条记录为一组,若第二条记录与第一条记录相差5分钟,则删除该记录,若第三条与第二条记录相差5分钟,则删除该记录, 第二组同理,遍历全表,按要求删除 ...
- Hive手写SQL案例
1-请详细描述将一个有结构的文本文件student.txt导入到一个hive表中的步骤,及其关键字 假设student.txt 有以下几列:id,name,gender三列 1-创建数据库 creat ...
随机推荐
- OSS的使用(谷粒商城58-64)
OSS的使用(谷粒商城58-64) 购买之类的就不在这里详述了,阿里云文档几乎都写了 创建bucket 学习阶段,相对独特的点在于我们需要选择公共读 项目开发阶段,不能选择公共读了,要尽量选择私有(代 ...
- DevOps|服务治理与服务保障实践指南
朱晋君@君哥聊技术 我自己为了消化里边的内容,整理了一个脑图,希望对你有帮助. 凌晨四点被公司的监控告警叫醒了,告警的原因是生产环境跑批任务发生故障.即刻起床处理故障,但还是花了不少时间才解决. 这次 ...
- 【分享】如何才能简洁高效不失优雅的爆破ZIP文件?
0x01 前言 在CTF比赛中,压缩包密码的爆破一直是一个热门话题.在这个过程中,简洁高效的方法是至关重要的.本文将介绍一些实用的技巧和工具,帮助您高效地爆破ZIP文件密码,而不失优雅.我们将探讨一些 ...
- 超详细的webpack之开始体验吧
webpack是一个前端工程化非常重要静态模块化打包工具,可以帮我们把 less.sass.esmodule.commonjs 等模块依赖处理成浏览器可识别的静态资源. 虽然webpack非常好用,但 ...
- Spring Cloud Gateway Actuator API SpEL表达式注入命令执行漏洞(CVE-2022-22947)
描述: Spring Cloud Gateway 是基于 Spring Framework 和 Spring Boot 构建的 API 网关,它旨在为微服务架构提供一种简单.有效.统一的 API 路由 ...
- 从一些常见的错误聊聊mysql服务端的关键配置
背景 每一年都进行大促前压测,每一次都需要再次关注到一些基础资源的使用问题,订单中心这边数据库比较多,最近频繁报数据库异常,所以对数据库一些配置问题也进行了研究,本文给出一些常见的数据库配置,说明这些 ...
- 14.4K Star,一款外观漂亮、运行快速、动画细腻的开源免费UI组件库
之前给大家推荐了很多后台模版,有读者希望推荐一些跟通用的好看组件,毕竟出了后台还有很多其他场景嘛.所以,今天继续给大家推荐一个广受好评的UI组件库:NextUI 主要特性 NextUI的主要目标是简化 ...
- Programming abstractions in C阅读笔记:p130-p131
<Programming Abstractions In C>学习第52天,p130-p131,总结如下: 一.技术总结 1. pig latin game 通过pig latin gam ...
- Python 设置环境变量方法
Python中的os模块 Python中的os模块提供了很多与操作系统相关的功能.其中就包括设置环境变量的方法,即setenv()方法. 使用os.setenv()方法设置环境变量 import os ...
- 「codeforces - 1608F」MEX counting
link. 首先考虑暴力,枚举规划前缀 \([1, i]\) 和前缀 mex \(x\),则我们需要 \(x\) 个数来填了 \([0, x)\),还剩下 \(i-x\) 个数随便填 \([0, x) ...