mysql练习案例(实操)
最近想要在回去复习mysql语句,就在网上找了一些案例练习,起初找得都是零零散散的,后面参考这篇博客做出了一个实操案例。Eric_Squirrel:mysql学生表经典案例50题。
首先是建表,我用的是mysql5.7,基本上没有问题
建库
创建alibaba数据库
create database alibaba;
切换到alibaba数据库
use alibaba;
建表
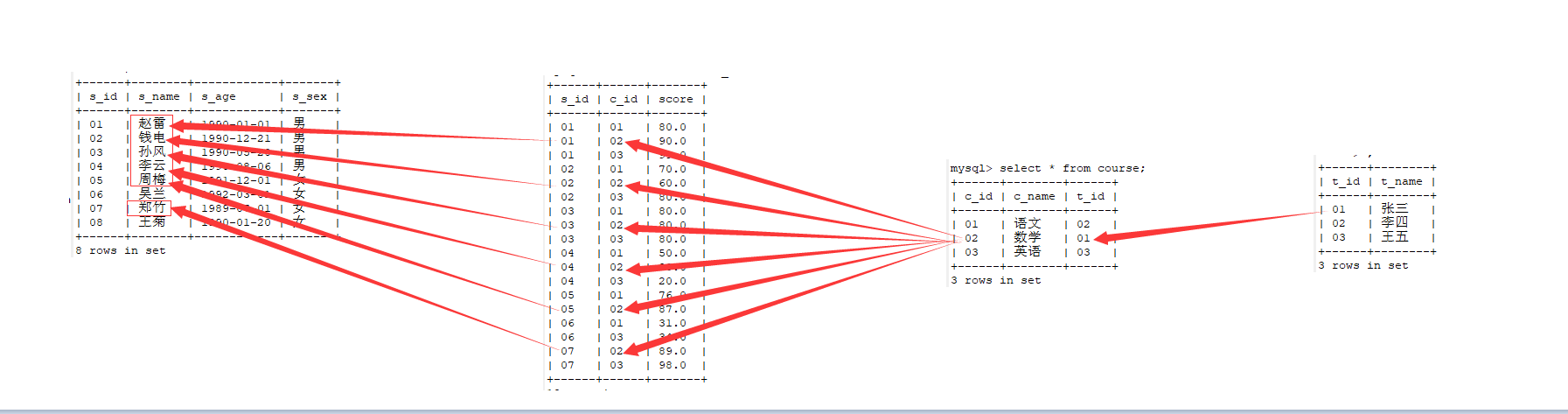
创建学生表student表=
create table student(s_id varchar(10),s_name varchar(10),s_age date,s_sex varchar(10)) engine=InnoDB default charset utf8;
insert into student(s_id,s_name,s_age,s_sex)
values('01' , '赵雷', '1990-01-01' , '男'),
('02' , '钱电' , '1990-12-21' , '男')
,('03' , '孙风' , '1990-05-20' , '男')
,('04' , '李云' , '1990-08-06' , '男')
,('05' , '周梅' , '1991-12-01' , '女')
,('06' , '吴兰' , '1992-03-01' , '女')
,('07' , '郑竹' , '1989-07-01' , '女')
,('08' , '王菊' , '1990-01-20' , '女');
查询 student 表中的数据
select * from student;
创建课程表course
create table course(c_id varchar(10),c_name varchar(10),t_id varchar(10)) engine=InnoDB default charset utf8;
insert into course values('01' , '语文' , '02'),
('02' , '数学' , '01'),
('03' , '英语' , '03');
查询 course 表中的数据
select * from course;
创建教师表teacher
create table teacher(t_id varchar(10),t_name varchar(10)) engine=InnoDB default charset utf8;
insert into teacher values('01' , '张三'),('02' , '李四'),('03' , '王五');
查看 teacher 表中的数据
select * from teacher;
创建学生成绩表stu_sco
create table stu_sco(s_id varchar(10),c_id varchar(10),score decimal(18,1)) engine=InnoDB default charset utf8;
insert into stu_sco values ('01' , '01' , 80), ('01' , '02' , 90), ('01' , '03' , 99), ('02' , '01' , 70), ('02' , '02' , 60), ('02' , '03' , 80), ('03' , '01' , 80), ('03' , '02' , 80), ('03' , '03' , 80), ('04' , '01' , 50), ('04' , '02' , 30), ('04' , '03' , 20), ('05' , '01' , 76), ('05' , '02' , 87), ('06' , '01' , 31), ('06' , '03' , 34), ('07' , '02' , 89), ('07' , '03' , 98);
查看 stu_sco 表中的数据
select * from stu_sco;
效果图
接下来就是对sql的操作;
完成如下查询语句
1、查询"01"课程比"02"课程成绩高的学生信息及课程分数
SELECT a.*, b.score AS sc1, c.score AS sc2
FROM student a
JOIN stu_sco b
ON a.s_id = b.s_id
AND b.c_id = 1
JOIN stu_sco c
ON a.s_id = c.s_id
AND c.c_id = 2
WHERE b.score > c.score;
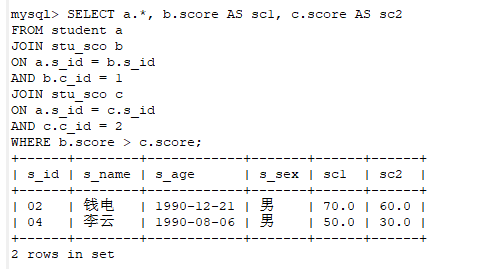
sql解析:给student表起个别名 a ,给stu_sco表起个别名b,给stu_sco表起个别名c 。注意:b表和c表本质上是同一张表,名字不同而已。然后把这三张表用JOIN连接起来,很显然我们要的不是三张表的全部数据,所以我们要在ON后面加上我们想要过滤的条件。Where后面在加上限制条件,就能得到我们想要的数据。

MySQL中 join的用法:join具有 连接的作用,即当两个或者两个以上的表有关系时,需要用join来连接这些相关的表,来处理或分析数据。
举个例子,我用teacher表course表进行连接

执行select * from teacher JOIN course;之后,等到得新表为
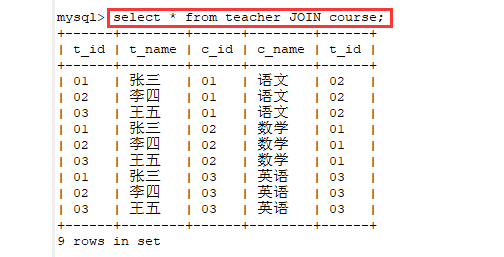
course表和teacher表一一匹配,得出一个新表
新表的列名是两个表列名加起来的,可能会产生相同的列名,如t_id
先用表course中的一行数据和表teacher中的每一行数据不断的拼接,产生新的行
再用表course的第二行去和表teacher中的每一行数据拼接,以此类推
表chourse是3行,表teacher是2=3行,所以按照上面的规律会产成3*3 = 9行的新的表
一般我们join后的表,并不是我们想要的,这时,可以用 ON 来加一些条件:
例如:teacher join course on teacher.t_id = course.t_id ,on后面就是我们加的条件,我们想要teacher.t_id这一列数据和course.t_id这一列的数据相等的数据,这里注意一下,join后的表列名是有重复的,所以ON后面的条件语句中我们要加上原来的表名。
select * from teacher join course on teacher.t_id = course.t_id;

2、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
SELECT student.s_id AS 学生编号, student.s_name AS 学生姓名, AVG(score) AS 平均成绩
FROM student
JOIN stu_sco ON student.s_id = stu_sco.s_id
GROUP BY student.s_id, student.s_name
HAVING 平均成绩 >= 60;

sql解析:从student表和stu_sco表中查询出学生编号,学生姓名,学生平均成绩,并且学生平均成绩要大于60

MySQL中 GROUP BY的用法:
1、当聚集函数和非聚集函数出现在一起时,需要将非聚集函数进行group by
2、当只做聚集函数查询时候,就不需要进行分组了。
MySQL中的聚合函数用来对已有数据进行汇总,如求和、平均值、最大值、最小值等。
count(col): 表示求指定列的总行数
max(col): 表示求指定列的最大值
min(col): 表示求指定列的最小值
sum(col): 表示求指定列的和
avg(col): 表示求指定列的平均值
简单的说,就是先看select 后面的字段,看他要查询那些字段。

其中数据表中有的字段叫非聚集函数,比如上面的student.s_name和student.s_id;这两个字段是student表中有的字段

而数据表中没有的字段叫聚集函数,比如平均成绩是通过聚合函数AVG(score)出来的
比如张三的各科成绩的score为语文:100,数学:98
AVG(score)之后就是99,要区别开:score是非聚集函数,但是AVG(score)是聚集函数。
对于上面的sql,我们就要用
GROUP BY student.s_id, student.s_name
对这两个非聚集函数分组,如果不用GROUP BY分组,就会出现下面的错误

MySQL中 HAVING的用法:
having一般和group by 配合使用。
误区:不要错误的认为having和group by 必须配合使用。
例如:没有group by也能用having

对于非聚集函数,having和where的用法是一样的

但是,如果select后面没有那个字段,但是数据表中有那个字段,此时只能用where(大家可以仔细看看两张截图中sql语句的区别)

对于聚集函数,只能用having

3、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
SELECT student.s_id AS 学生编号, student.s_name AS 学生姓名, COUNT(c_id) AS 选课总数
, SUM(score) AS 总成绩
FROM student
JOIN stu_sco ON student.s_id = stu_sco.s_id
GROUP BY student.s_id, student.s_name;

4、查询"李"姓老师的数量
SELECT COUNT(*) AS 李姓老师的数量
FROM teacher
WHERE t_name LIKE '李%';

MySQL LIKE 语法:
LIKE运算符用于WHERE表达式中,以搜索匹配字段中的指定内容,语法如下:
WHERE column LIKE 参数
WHERE column NOT LIKE 参数
在LIKE全面加上NOT运算符时,表示与LIKE相反的意思,即选择行不包含参数的数据记录
LIKE通常与通配符%一起使用,而不加通配符%的LIKE语法,表示精确匹配,其实际效果等同于 = 等于运算符
MySQL中 %的用法:
%在sql语句中表示通配符,在模糊查询中用到 如查询姓名以 李开头的 就写成 like ‘李%’ 如 姓名以 李结尾的 写成 like ‘%李’。 姓名中包含 李的 写成 like '%李%'
5、查询学过"张三"老师授课的同学的信息
SELECT *
FROM student
WHERE s_id IN (
SELECT s_id
FROM stu_sco
WHERE c_id IN (
SELECT c_id
FROM course
WHERE t_id IN (
SELECT t_id
FROM teacher
WHERE t_name = '张三'
)
)
);
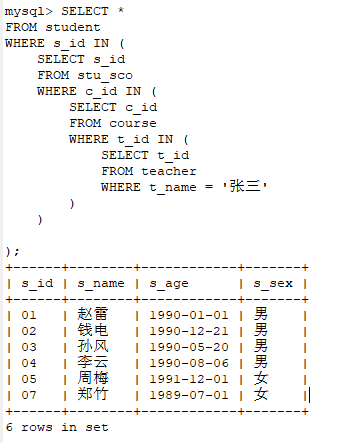
sql解析:查询student表中s_id的范围在 ( 查询stu_sco表中c_id的范围在 ( 查询teacher表中的t_id限制条件是t_name=’张三' ) )中的数据

详细信息如下
MySQL中 IN 的用法:
in常用于where表达式中,其作用是查询某个范围内的数据。
例如:查询student表中,s_id的值的范围是01,02,03的数据

PS: not in与in作用相反
例如:查询student表中,s_id的值的范围不是01,02,03的数据

6、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
SELECT *
FROM student
WHERE s_id IN (
SELECT a.s_id
FROM (
SELECT *
FROM stu_sco
WHERE c_id = '01'
) a
JOIN (
SELECT *
FROM stu_sco
WHERE c_id = '02'
) b
ON a.s_id = b.s_id
);

sql解析:查询学生表中的全部信息,限制条件是s_id在(查询stu_sco表中s_id为两个stu_sco表的数据,其中a的c_id为01,b的c_id为02并且两个表中的s_id要相等)范围内的数据

7、查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
SELECT student.*
FROM student, stu_sco sc1
WHERE student.s_id = sc1.s_id
AND sc1.c_id = '01'
AND student.s_id NOT IN (
SELECT s_id
FROM stu_sco sc2
WHERE sc2.c_id = '02'
);

sql解析:根据student表和stu_sco表来查询student表中的所有数据,限制条件是student表中的s_id和stu_sco表中的s_id相等,并且stu_sco表中的c_id等于01,和学生表中的s_id不在(根据stu_sco表查询s_id,限制条件是c_id不等于02)范围内。
8、查询没有学全所有课程的学生信息
SELECT student.*
FROM student
JOIN stu_sco ON student.s_id = stu_sco.s_id
GROUP BY student.s_id, student.s_name, student.s_age, student.s_sex
HAVING COUNT(stu_sco.c_id) < (
SELECT COUNT(DISTINCT c_id)
FROM course
);

sql解析:从student表中查询student的全部信息,把student表和stu_sco表做关联,关联条件是student.s_id = stu_sco.id,把字段进行分组,限制条件是stu_sco.c_id的数据量小于从course表中查询出来的c_id的数量。
MySQL中 DISTINCT 的用法:
DISTINCT 关键字是去重的,如果查询的是单个字段的就是去掉单个字段中重复的数据,如果查询的是多个字段,那么去重的是多个字段中完全相同的数据。
9、查询至少有一门课与学号为"01"的同学所学相同的同学的信息
SELECT student.*
FROM student
WHERE s_id IN (
SELECT DISTINCT s_id
FROM stu_sco
WHERE c_id IN (
SELECT c_id
FROM stu_sco
WHERE s_id = '01'
)
AND s_id <> '01'
);

sql解析:从学生表查询学生信息,限制条件是s_id在(从stu_sco中查询s_id,并且s_不等于 '01' ,限制条件是c_id在(从stu_sco表中查询c_id,限制条件是s_id = '01')范围内)范围内
MySQL中 <> 的用法:
!=,<> 两者都是不等于的意思,!= 是以前sql标准,<> 是现在使用的sql标准,推荐使用 <>。
10、查询和"01"号的同学学习的课程完全相同的其他同学的信息
SELECT student.*
FROM student
WHERE s_id IN (
SELECT s_id
FROM stu_sco
WHERE s_id <> '01'
GROUP BY s_id
HAVING COUNT(1) = (
SELECT COUNT(c_id)
FROM stu_sco
WHERE s_id = '01'
)
);

sql解析:从student表中查询student全部信息,限制条件是s_id在(从stu_sco表中查询s_id,限制条件是s_id不等于 '01' 并且用s_id做分组,统计s_id中每个s_id的数量等于从stu_sco表中查询c_id的数量,限制条件是s_id等于 '01')范围内
(未完,待补充)
mysql练习案例(实操)的更多相关文章
- Spark详解(07-1) - SparkStreaming案例实操
Spark详解(07-1) - SparkStreaming案例实操 环境准备 pom文件 <dependencies> <dependency> &l ...
- 号外号外:9月13号《Speed-BI云平台案例实操--十分钟做报表》开讲了
引言:如何快速分析纷繁复杂的数据?如何快速做出老板满意的报表?如何快速将Speed-BI云平台运用到实际场景中? 本课程将通过各行各业案例背景,将Speed-BI云平台运用到实际场景中 ...
- 新硬盘挂载-fdisk+mount案例实操
新硬盘挂载-fdisk+mount案例实操 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 现在很多服务器都支持热插拔了,当有新的硬盘插入到服务器上我们需要将其分区,格式化,然后挂载 ...
- Kafka集群优化篇-调整broker的堆内存(heap)案例实操
Kafka集群优化篇-调整broker的堆内存(heap)案例实操 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看kafka集群的broker的堆内存使用情况 1>. ...
- Python相关分析—一个金融场景的案例实操
哲学告诉我们:世界是一个普遍联系的有机整体,现象之间客观上存在着某种有机联系,一种现象的发展变化,必然受与之关联的其他现象发展变化的制约与影响,在统计学中,这种依存关系可以分为相关关系和回归函数关系两 ...
- Hive中的数据类型以及案例实操
@ 目录 基本数据类型 集合数据类型 案例实操 基本数据类型 对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它 ...
- 【Spark】Day01-入门、模块组成、4种运行模式详解及配置、案例实操(spark分析过程)
一.概述 1.概念 基于内存的大数据分析计算引擎 2.特点 快速.通用.可融合性 3.Spark内置模块[腾讯8000台spark集群] Spark运行在集群管理器(Cluster Manager)上 ...
- Azkaban(二)【WorkFlow案例实操】
目录 1.使用步骤 2.案例: 1.hello word 2.作业依赖[dependsOn配置作业的依赖关系] 3.内嵌工作流 4.全局配置 [在开头通过config进行配置,后续可以通过${属性名} ...
- yum install mysql-community-server yum方式安装mysql(社区版实操)
前言:rpm方式或者这种yum安装时比较简单的方式,但是不推荐,但是确实很着急的话,可以采用这种安装这种方式不利于后续对mysql的管理,如果是多实例或者是复杂的一些架构的话,还是推荐利用源码包编译方 ...
- 在CentOS7.6上安装自动化运维工具Ansible以及playbook案例实操
前言 Ansible是一款优秀的自动化IT运维工具,具有远程安装.远程部署应用.远程管理能力,支持Windows.Linux.Unix.macOS和大型机等多种操作系统. 下面就以CentOS 7.6 ...
随机推荐
- iphone拍照的历史顽固问题-鬼影
iphone11 系列的鬼影问题 近期苹果 iPhone 11 系列的手机又出现了新问题,其中有不少网友表示,自己在用手机拍照后,图片中莫名出现了"鬼影"的现象,这次的" ...
- C++之函数的分文件编写
从黑马程序员的c++课里学到的函数的分文件编写 函数的分文件编写 作用:让代码结构更加清晰 函数分文件编写一般有4个步骤 1,创建后缀名为.h的头文件 2,创建后缀名为.cpp的源文件 3,在头文件中 ...
- locust与jmeter测试过程及结果对比
JMeter和Locust都是强大的性能测试工具,各自拥有自己的优势和专注领域.JMeter提供了全面的功能和基于GUI的界面,适用于复杂的场景和非技术人员.相比之下,Locust采用了以代码为中心的 ...
- IIC总线学习笔记
IIC(Inter-Integrated Circuit)其实是IICBus简称,所以中文应该叫集成电路总线,它是一种串行通信总线,使用多主从架构,由飞利浦公司在1980年代为了让主板.嵌入式系统或手 ...
- 使用gulp.js打包layuiAdmin
安装nvm 在nvm目录下,找到settings.txt,追加以下两行加速nvm(淘宝镜像)node_mirror: https://npm.taobao.org/mirrors/node/npm_m ...
- Typescript: 当出现错误时,不编译文件成js文件
在tsconfg.json文件中添加如下选项 "noEmitOnError": true, /* Disable emitting files if any type checki ...
- Print, printf, println的区别
print 非格式,打印变量的值,不换行 printf 支持格式化输出,不换行 println 非格式,打印变量的值 ,换行
- Uncaught TypeError: Failed to set the 'currentTime' property on 'HTMLMediaElement': The provided double value is non-finite.
musicSeekTo: function(value){this.audio.currentTime = this.audio.duration*value; }, musicVoiceSeekTo ...
- 不想引入mq?试试debezium
有句话叫做"如无必要,勿增实体". 在一些小型项目当中,没有引入消息中间件,也不想引入,但有一些业务逻辑想要解耦异步,那怎么办呢? 我们的web项目,单独内网部署,由于大数据背景, ...
- 数仓备份经验分享丨详解roach备份原理及问题处理套路
本文分享自华为云社区<GaussDB(DWS) 备份问题定位思路>,作者: yd_216390446. 前言 在数据库系统中,故障分为事务内部故障.系统故障.介质(磁盘)故障.对于事务内部 ...