文心一言 VS 讯飞星火 VS chatgpt (77)-- 算法导论7.3 2题
二、如果用go语言,在 RANDOMIZED-QUICKSORT 的运行过程中,在最坏情况下,随机数生成器 RANDOM 被调用了多少次?在最好情况下呢?以θ符号的形式给出你的答案?
文心一言:
在 RANDOMIZED-QUICKSORT 的运行过程中,最坏情况下,随机数生成器 RANDOM 的调用次数为 O(n)。这是因为在最坏情况下,每次分区操作都会将数组分成大小相等的两部分,因此每次都需要从剩下的 n-1 个元素中随机选择一个元素作为主元。这样,每次分区操作都需要调用 RANDOM 函数,总共需要进行 n 次分区操作,因此 RANDOM 的调用次数为 O(n)。
在最好情况下,RANDOM 的调用次数为 O(log n)。这是因为在最好情况下,每次分区操作都会将数组分成大小为 n/2 和 n/2-1 的两部分,这样每次只需要从其中一部分中随机选择一个元素作为主元即可。这样,每次分区操作只需要调用 RANDOM 函数一次,总共需要进行 log(n) 次分区操作,因此 RANDOM 的调用次数为 O(log n)。
讯飞星火:
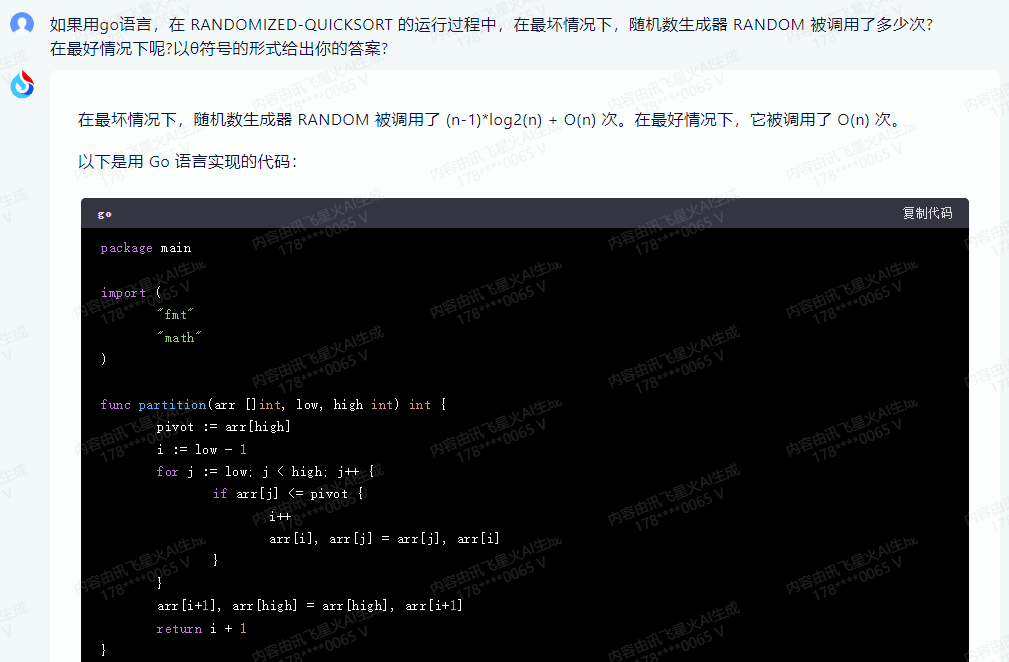
在最坏情况下,随机数生成器 RANDOM 被调用了 (n-1)*log2(n) + O(n) 次。在最好情况下,它被调用了 O(n) 次。
以下是用 Go 语言实现的代码:
package main
import (
"fmt"
"math"
)
func partition(arr []int, low, high int) int {
pivot := arr[high]
i := low - 1
for j := low; j < high; j++ {
if arr[j] <= pivot {
i++
arr[i], arr[j] = arr[j], arr[i]
}
}
arr[i+1], arr[high] = arr[high], arr[i+1]
return i + 1
}
func quickSort(arr []int, low, high int) {
if low < high {
pi := partition(arr, low, high)
quickSort(arr, low, pi-1)
quickSort(arr, pi+1, high)
}
}
func randomizedQuickSort(arr []int, n int) {
randomizedPartition(arr, 0, n-1)
quickSort(arr, 0, n-1)
}
func randomizedPartition(arr []int, low, high int) {
rand.Seed(time.Now().UnixNano())
pivotIndex := rand.Intn(high-low+1) + low
arr[pivotIndex], arr[high] = arr[high], arr[pivotIndex]
pivotIndex = partition(arr, low, high)
arr[pivotIndex], arr[high] = arr[high], arr[pivotIndex]
}
func main() {
arr := []int{3, 8, 2, 5, 1, 4, 7, 6}
n := len(arr)
randomizedQuickSort(arr, n)
fmt.Println("Sorted array:", arr)
}
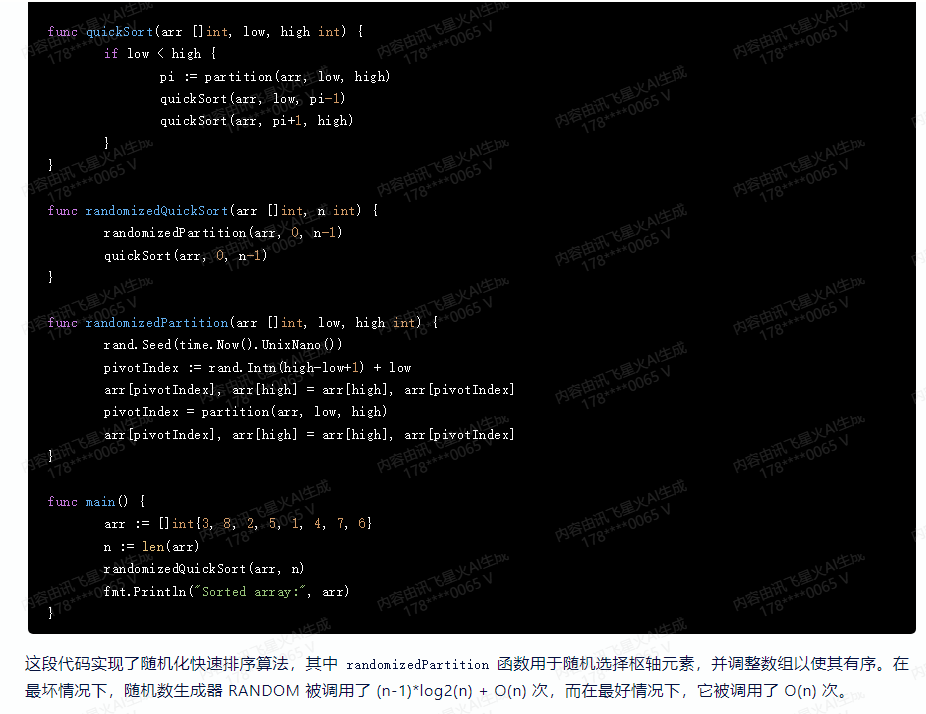
这段代码实现了随机化快速排序算法,其中 randomizedPartition 函数用于随机选择枢轴元素,并调整数组以使其有序。在最坏情况下,随机数生成器 RANDOM 被调用了 (n-1)*log2(n) + O(n) 次,而在最好情况下,它被调用了 O(n) 次。
360智脑:
在 RANDOMIZED-QUICKSORT 中,最坏情况下,每次递归调用 quicksort() 函数时都需要调用 RANDOM 生成一个随机数。因此,在最坏情况下,random() 被调用了 n! 次,其中 n 是待排序数组的大小。
以θ符号表示,最坏情况下,random() 被调用的次数为:θ(n!)。
在最好情况下,每次递归调用 quicksort() 函数时会使用数组中的一个元素作为随机数,此时 random() 被调用的次数为 n 次。
以θ符号表示,最好情况下,random() 被调用的次数为:θ(n^2)。

chatglm:
在最坏情况下,随机数生成器 RANDOM 可能会被调用 n 次,其中 n 是待排序数组的长度。这是因为在随机选择基准值时,有可能每次选择的基准值都不同,因此需要多次调用 RANDOM 函数来生成随机数。
在最好情况下,随机数生成器 RANDOM 可能会被调用 1 次或者 2 次。这是因为在随机选择基准值时,有可能第一次选择的基准值就是排序数组中的最小值或最大值,这样就不需要再次调用 RANDOM 函数了。如果第一次选择的基准值不是最小值或最大值,那么需要再次调用 RANDOM 函数来生成一个新的随机数。
因此,最坏情况下,随机数生成器 RANDOM 可能会被调用 n 次,最好情况下可能被调用 1 或 2 次。答案可以表示为:
最坏情况:O(n)
最好情况:O(1) 或 O(2)

通义千问:
在最坏情况下,随机数生成器RANDOM被调用了nlogn次,其中n为待排序数组的大小。在最好情况下,随机数生成器RANDOM被调用了O(1)次。
这是因为在最坏情况下,每次递归调用QUICKSORT都会将数组分成两份,其中一份的大小为n/2,另一份的大小为1。由于我们将较小的一份作为基准值,所以我们需要对较大的一份进行递归调用。这个过程会一直持续到每个子数组的大小为1,此时我们就可以直接将它们按照随机数排序。因此,总共需要进行nlogn次递归调用。
在最好情况下,每次递归调用QUICKSORT都会将数组分成两份,其中一份的大小为1,另一份的大小为n-1。由于我们将较大的一份作为基准值,所以我们只需要对较小的一份进行递归调用。由于每个子数组的大小为1,所以我们只需要对它们进行一次排序,即可得到有序数组。因此,总共需要进行O(1)次递归调用。

天工:
在最坏情况下,随机数生成器 RANDOM 会被调用 $O(\log n)$ 次,其中 $n$ 是要排序的元素数量。
在最好情况下,随机数生成器 RANDOM 会被调用 $O(1)$ 次。
因此,随机数生成器 RANDOM 在最坏情况下的平均运行时间复杂度为 $O(\log n)$,在最好情况下的平均运行时间复杂度为 $O(1)$。
chatgpt:
在随机化快速排序(RANDOMIZED-QUICKSORT)中,随机数生成器 RANDOM 在每次选择划分元素时被调用。
在最坏情况下,随机数生成器 RANDOM 被调用的次数等于递归调用的次数。当划分中选择的划分元素总是使得数组分割得非常不均衡时,最坏情况发生。
对于长度为 n 的数组,在最坏情况下,递归调用 RANDOM 的次数可以表示为递归树的高度 h,它是数组长度的对数级别。
因此,在最坏情况下,RANDOM 被调用的次数为 Θ(log n)。
在最好情况下,随机数生成器 RANDOM 仅被调用一次。当每次都能选择一个恰好平衡分割的划分元素时,最好情况发生。
因此,在最好情况下,RANDOM 被调用的次数为 Θ(1)。
综上所述:
在最坏情况下,随机数生成器 RANDOM 被调用 Θ(log n) 次。
在最好情况下,随机数生成器 RANDOM 被调用 Θ(1) 次。
总结

文心一言 VS 讯飞星火 VS chatgpt (77)-- 算法导论7.3 2题的更多相关文章
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- 【个人首测】百度文心一言 VS ChatGPT GPT-4
昨天我写了一篇文章GPT-4牛是牛,但这几天先别急,文中我测试了用GPT-4回答ChatGPT 3.5 和 Notion AI的问题,大家期待的图片输入也没有出现. 昨天下午百度发布了文心一言,对标C ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- 获取了文心一言的内测及与其ChatGPT、GPT-4 对比结果
百度在3月16日召开了关于文心一言(知识增强大语言模型)的发布会,但是会上并没现场展示demo.如果要测试的文心一言 也要获取邀请码,才能进行测试的. 我这边通过预约得到了邀请码,大概是在3月17日晚 ...
- 百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
目录 中国版ChatGPT上线发布 强大中文理解能力 智能文学创作.商业文案创作 图片.视频智能生成 中国生成式AI三大产业机会 新型云计算公司 行业模型精调公司 应用服务提供商 总结 获取文心一言邀 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- 基于讯飞语音API应用开发之——离线词典构建
最近实习在做一个跟语音相关的项目,就在度娘上搜索了很多关于语音的API,顺藤摸瓜找到了科大讯飞,虽然度娘自家也有语音识别.语义理解这块,但感觉应该不是很好用,毕竟之前用过百度地图的API,有问题也找不 ...
- android用讯飞实现TTS语音合成 实现中文版
Android系统从1.6版本开始就支持TTS(Text-To-Speech),即语音合成.但是android系统默认的TTS引擎:Pic TTS不支持中文.所以我们得安装自己的TTS引擎和语音包. ...
- android讯飞语音开发常遇到的问题
场景:android项目中共使用了3个语音组件:在线语音听写.离线语音合成.离线语音识别 11208:遇到这个错误,授权应用失败,先检查装机量(3台测试权限),以及appid的申请时间(35天期限), ...
- 初探机器学习之使用讯飞TTS服务实现在线语音合成
最近在调研使用各个云平台提供的AI服务,有个语音合成的需求因此就使用了一下科大讯飞的TTS服务,也用.NET Core写了一个小示例,下面就是这个小示例及其相关背景知识的介绍. 一.什么是语音合成(T ...
随机推荐
- 2020-11-17:java中,吞吐量优先和响应时间优先的回收器是哪些?
福哥答案2020-11-17:对于吞吐量优先的场景,就只有一种选择,就是使用 PS 组合(Parallel Scavenge+Parallel Old ).对于响应时间优先的场景,在 JDK1.8 的 ...
- 2021-06-30:给定长度为m的字符串aim,以及一个长度为n的字符串str ,问能否在str中找到一个长度为m的连续子串, 使得这个子串刚好由aim的m个字符组成,顺序无所谓, 返回任意满足条件
2021-06-30:给定长度为m的字符串aim,以及一个长度为n的字符串str ,问能否在str中找到一个长度为m的连续子串, 使得这个子串刚好由aim的m个字符组成,顺序无所谓, 返回任意满足条件 ...
- windows10 docker desktop与本机数据拷贝
目录 前景提示 一.构建环境 二.安装测试需要的nginx 三. docker文件拷贝到windows本地 总结 前景提示 发现只有docker关于docker拷贝linux内部文件的命令,但是,对于 ...
- 如何借助Kafka持久化存储K8S事件数据?
大家应该对 Kubernetes Events 并不陌生,特别是当你使用 kubectl describe 命令或 Event API 资源来了解集群中的故障时. $ kubectl get even ...
- Spring boot+vue打包、上传宝塔面板并配置https
终于把网站搞完了,也终于能够通过域名访问了,这次就简单回顾一下这么多时间的经历,总结一下. 项目地址穆音博客,本文发布原地址在Spring boot+vue打包.上传宝塔面板并配置https 我的开发 ...
- 荣登国家级榜单!ShowMeBug创始人李亚飞入选「科创中国·青年创业榜」
近日,中国科协召开2022"科创中国"年度会议,会上发布了2021"科创中国"系列榜单.其中,ShowMeBug 创始人&CEO李亚飞入选2021年科创 ...
- Python自动化测试面试题精选(一)
Python自动化测试面试题精选 今天由勇哥给你介绍一些Python自动化测试中常见的面试题,涵盖了Python基础.测试框架.测试工具.测试方法等方面的内容,希望能够帮助你提升自己的水平和信心. 项 ...
- Hive执行计划之只有map阶段SQL性能分析和解读
目录 目录 概述 1.不带函数操作的select-from-where型简单SQL 1.1执行示例 1.2 运行逻辑分析 1.3 伪代码解释 2.带普通函数和运行操作符的普通型SQL执行计划解读 2. ...
- HStore表全了解:实时入库与高效查询利器
摘要:本文章将从使用者角度介绍HStore概念以及使用. 本文分享自华为云社区<GaussDB(DWS)HStore表讲解>,作者:大威天龙:- . HStore表简介 面对实时入库和实时 ...
- 从2PC和容错共识算法讨论zookeeper中的Create请求
最近在读<数据密集型应用系统设计>,其中谈到了zookeeper对容错共识算法的应用.这让我想到之前参考的zookeeper学习资料中,误将容错共识算法写成了2PC(两阶段提交协议),所以 ...