Http 编码格式简介
Http 格式简介
Http 是用于在客户端和服务端之间进行通信的一种消息格式,一般由以下几个部分组成:
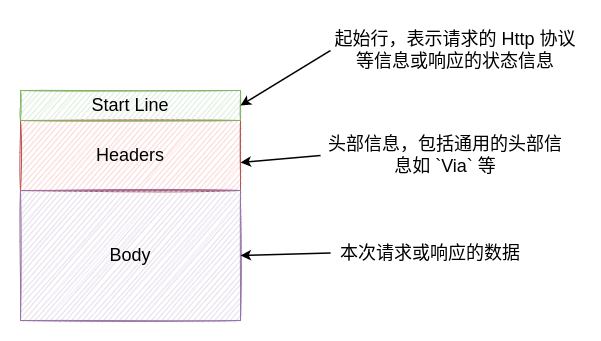
起始行:这部分在 Http 响应中也被称为状态行,针对不同的 Http 类型,其中包含的内容也不一致
request总共包括三个元素:Http 请求方式、请求目标和 Http 版本- Http 请求方式:即本次请求的需要执行的动作,如:
GET、POST、PUT等 - 请求目标:即需要到将请求发送到 “何处”,这里可以是一个绝对路径,或者是一个 URL
- Http 版本:定义当前 Http 请求的协议版本,如 Http/1.1、Http/2 等
- Http 请求方式:即本次请求的需要执行的动作,如:
response的起始行同样包括三个元素:协议版本、状态码和状态文本- 协议版本:及当前 Http 的版本,如 Http/1.1
- 状态码:表示对之前请求的处理情况,如 404 表示请求的 URL 不存在,具体的状态码可以查看 Http 响应码
- 状态文本:用于帮助理解响应的文本信息
头部信息:一些关于本次 Http 消息的附加消息,如:本次消息体数据的编码格式、消息体数据的长度等。具体的结构是通过 ":" 分隔的不区分大小写的格式,最终这些头部信息将会组成一行
一般存在以下几种头部信息:
- 通用头部信息:适用于整个 Http 消息的头部信息
- 请求头信息:如:
user-agent表示是何处发出的请求、accept-language等 - 响应头信息:提供有关服务器响应的相关信息,如:
accept-range等 - 表现层头信息:描述消息数据的原始格式和应用编码等信息,如
content-type等
数据主体(Body):这一部分表示本次请求或响应带有的实际数据,针对请求和响应,这部分内容也不一致:
- 请求的数据主体:一般只有使用
POST方式请求时才会带有这部分的数据,
- 请求的数据主体:一般只有使用
Http 编码
头部信息的编码
按照 规范 ,头部的字符应当都是 ASCII 格式的字符串,对于非 ASCII 格式的字符,需要转换成为 % + "对应字符编码的十六进制" 的形式
比如说,如果需要下载一个包含中文名的文件(如 “数据导出.xlsx”),那么在对应的响应头部信息中关于这个文件的描述应该转换成为如下的形式:
Content-Disposition: attachment; filename=%E6%95%B0%E6%8D%AE%E5%AF%BC%E5%87%BA.xlsx
请求和响应数据主体的编码
按照规范,如果没有在头部信息指定编码的格式,如 Content-Type:application/json;charset=utf8 中的 charset 即为指定的数据主体的编码格式,如果没有指在头部指定这个编码,那么默认将会使用 ISO-8859-1 作为数据主体的编码格式,具体可以参见:Http 1.1 规范 3.7.1
特别地,如果是使用 Servlet 容器处理请求时,针对 XML 格式的响应默认会使用 UTF-8 编码格式
GET 请求的默认编码
GET 请求一般不会携带数据体部分,因此主要的处理就是请求的 URL 的编码处理(特别是请求参数的编码),这部分编码整个 URL 的字符都使用 US-ASCII 字符,对于不是 ASCII 字符的参数,要求在发送请求时自动将这个字符转换成 % + “字符的十六进制编码” 的格式,一般我们在浏览器内输入带有中文参数的 URL 时,浏览器都会自动将其进行转码的处理,因此该请求能被正常处理
对于 “字符的十六进制编码”,由于现有的大部分应用都推荐使用 UTF-8 作为默认的编码格式,因此直接将字符转为对应的 UTF-8 编码的二进制并转换为对应的十六进制在大部分的应用上都是可行的。另外,由于 ISO--8859-1 和 ASCII 编码的 0x20 到 0x7e 一致,因此它们经常互换使用
POST 请求的默认编码
对于请求的 URL 部分编码和 GET 的编码格式一致,但由于一般 POST 请求会携带一个数据主体部分,因此这部分的编码需要特殊指定,一般会在请求的头部信息 Content-Type 中指定数据体的编码格式
如果没有在 Content-Type 中指定编码格式,那么服务端应当按照 ISO-8859-1 的编码格式对数据体参数进行编码处理。但是这种情况有个例外,就是当 POST 请求的类型为 application/x-www-form-urlencoded(即表单提交)的情况下,服务端应当按照 US-ASCII 的格式对数据体部分进行对应的编码处理
Tomcat 对编码格式的处理
针对 GET 请求的编码处理
按照前文提到的规范,如果没有指定对 URL 的编码,那么将默认使用 ISO-8859-1 的编码格式对 URL 进行解码(包括请求参数等 '%' 后接着的部分),对于 Tomcat 服务器来讲,可以在对应的 server.xml 配置文件中配置 URLEncoding 来指定对应的 URL 编码格式,如下所示:
<Connector port="8090" URIEncoding="UTF-8"/>
对于 Spring Boot 的项目来讲,由于它已经默认内嵌了 Tomcat 作为默认的 web 服务器,并且默认 URL 的编码格式为 UTF-8,如果希望改变对应的编码格式,可以在 application.yml 配置文件中做如下的配置:
server:
tomcat:
uri-encoding: UTF-8 # 设置 Tomcat 的 URL 编码格式为 UTF-8
针对 POST 请求的编码处理
对于 POST 请求来讲,与 GET 请求的最大区别在于它一般会包含一个数据主体部分,其余部分的编码处理和 GET 请求一致。对于数据主体部分的编码,一般由发送请求的客户端在头部信息中指定编码格式。如果发送请求的客户端没有指定编码格式,那么将会默认使用 US-ASCII 的格式处理数据主体的内容
除此之外,Servlet 规范要求将 application/x-www-form-urlencoded 的 % 编码格式在默认情况下需要转换为 ISO-8859-1 的格式,这与现代的浏览器默认使用 UTF-8 的编码格式不兼容。然而,Servlet 规范要求 Servlet 容器对于 application/x-www-form-urlencoded 编码格式的 % 序列能够转换为任意配置的编码格式,因此,可以通过将请求字符编码设置为 UTF-8 格式来实现对 x-www-form-urlencoded 格式的编码处理,为了达到这一目的,可以通过添加对应的 Filter 来实现将数据主体的 % 编码转换为对应的 UTF-8 编码的字符:
import org.springframework.stereotype.Component;
import javax.servlet.*;
import java.io.IOException;
/**
* @author lxh
*/
@Component
public class BodyCharsetFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
request.setCharacterEncoding("UTF-8"); // 设置数据主体的编码格式为 UTF-8(针对 x-www-form-urlencoded 默认格式)
chain.doFilter(request, response); // 过滤链的后续处理
}
}
参考:
[1] https://cwiki.apache.org/confluence/display/TOMCAT/Character+Encoding
[2] https://www.w3.org/Protocols/rfc2616/rfc2616
Http 编码格式简介的更多相关文章
- 编码格式简介:ASCII码、ANSI、GBK、GB2312、GB18030和Unicode、UTF-8,BOM头
编码格式简介:ASCII码.ANSI.GBK.GB2312.GB18030和Unicode.UTF-8,BOM头 二进制: 只有0和1. 十进制.十六进制.八进制: 计算机其实挺笨的,它只认识0101 ...
- 【miscellaneous】编码格式简介(ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE)
转发:http://blog.jobbole.com/30526/ 来源:潜行者m 的博客 编码一直是让新手头疼的问题,特别是 GBK.GB2312.UTF-8 这三个比较常见的网页编码的区别,更是让 ...
- 编码格式简介(ANSI、GBK、GB2312、UTF-8、UTF-16、GB18030和 UNICODE)
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物,他们把这称为”字节”.再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态 ...
- Python编程Day7——字符编码、字符与字节、文件操作
一.字符编码 重点 ***** 1. 什么是字符编码:将人识别的字符转换计算机能识别的01,转换的规则就是字符编码表2. 常用的编码表:ascii.unicode.GBK.Shift_JIS.Euc- ...
- day03-课堂笔记-大纲
字典: # 字典循环: dic.keys() | dic.values() | dic.items()for k, v in dic.items(): print(k, v) # ...
- python中的内容编码
一.python编码简介 1)编码格式简介 python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ASCII),ASCII(American Standard Code for In ...
- html5快速入门(一)—— html简介
前言: 1.HTML5的发展非常迅速,可以说已经是前端开发人员的标配,在电商类型的APP中更是运用广泛,这个系列的文章是本人自己整理,尽量将开发中不常用到的剔除,将经常使用的拿出来,使需要的朋友能够真 ...
- Servlet简介与Servlet和HttpServlet运行的流程
1.Servlet [1] Servlet简介 > Server + let > 意为:运行在服务器端的小程序. > Ser ...
- Python编码格式的指定方式
参考自: http://python.jobbole.com/85852/, 原文探究的更深,有兴趣的可以去看看. 简介来讲就是使用一种特殊的注释来声明编码格式,如何判断这种格式也用了很简单粗暴有效的 ...
- python学习笔记系列----(一)python简介
一个月前,就按下决心要系统的学习下python了,虽然之前有学习过java,学习过c++,也能较为熟练的使用java做自动化测试看懂c++里的业务逻辑,但是实际上有那么多的东西自己还是不清楚,今天下定 ...
随机推荐
- 聊一聊 TLS/SSL
哈喽大家好,我是咸鱼 当我们在上网冲浪的时候,会在浏览器界面顶部看到一个小锁标志,或者网址以 "https://" 开头 这意味着我们正在使用 TLS/SSL 协议进行安全通信.虽 ...
- CF1364B
题目简化和分析: 这题没啥好说的,找其绝对值最大,也就是找到每一个山峰山谷. 这样不仅满足选择的个数最少,并且值最大. 正确性证明: 若 \(a\le b\le c\) \(|a-b|+|b-c|=( ...
- 使用go语言开发hive导出工具
前言 新版 hive 提供了 beeline 工具,可以执行SQL并导出数据,不过操作还是有点复杂的,团队里有些同学不会Linux的基本操作,所以我花了亿点点时间写了个交互式的命令行工具方便使用. 效 ...
- 高性能日志脱敏组件:已支持 log4j2 和 logback 插件
项目介绍 日志脱敏是常见的安全需求.普通的基于工具类方法的方式,对代码的入侵性太强,编写起来又特别麻烦. sensitive提供基于注解的方式,并且内置了常见的脱敏方式,便于开发. 同时支持 logb ...
- Telegram 正式引入国产小程序技术
Telegram 宣布为其开发者提供了一项"能够在 App 中运行迷你应用"的新功能( 迷你应用即 Mini App,下文中以"小程序"代替). 在一篇博客文章 ...
- CSP 初赛复习
想要做一些不需要思考也算不得摆烂的事,但发现很难找到符合上述要求的学习内容. 突然想到还剩两天就 CSP 初赛了.虽然在 LN 想过不了初赛纯属搞笑,但为了不让自己的分数太难看还是简单复习一下. 没有 ...
- 苹果电脑开不了机,mac时间机器备份加速,以及识别不到u盘的方法
平淡无奇的一天,上班后,我按照正常流程,揭开我亲爱的mac的盖子.屏幕没有如昨天一样照亮我的脸庞,擦,电用完了吗? 我充上电,半小时后,电池都热了,依然开不了机.打售后电话,售后姐姐亲切的指导各种我使 ...
- Transformers 中原生支持的量化方案概述
本文旨在对 transformers 支持的各种量化方案及其优缺点作一个清晰的概述,以助于读者进行方案选择. 目前,量化模型有两个主要的用途: 在较小的设备上进行大模型推理 对量化模型进行适配器微调 ...
- Java 21增强对Emoji表情符号的处理了
现一个 Java 21 中有意思的东西! 在java.Lang.Character类中增加了用于确定字符是否为 Emoji 表情符号的 API,主要包含下面六个新的静态方法: public stati ...
- 构建满足流批数据质量监控用火山引擎DataLeap
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 面对今日头条.抖音等不同产品线的复杂数据质量场景,火山引擎 DataLeap 数据质量平台如何满足多样的需求?本文 ...