【LLM训练系列】从零开始训练大模型之Phi2-mini-Chinese项目解读
一、前言
本文主要是在复现和实践Phi2-mini-Chinese后,简要分析下Phi2-mini-Chinese这个项目,做一个学习实战总结。
原文发布于知乎:https://zhuanlan.zhihu.com/p/718307193,转载请注明出数。
Phi2-mini-Chinese简介
Phi2-Chinese-0.2B 从0开始训练自己的Phi2中文小模型,支持接入langchain加载本地知识库做检索增强生成RAG。Training your own Phi2 small chat model from scratch.
项目开始时期:2023年12月22日
地址:https://github.com/charent/Phi2-mini-Chinese
流程步骤
- 数据处理
- Tokenizer训练
- 预训练
- SFT
- DPO
数据处理的步骤略去。一般是使用开源数据集。
Tokenizer训练
就是使用tokenizers库用BPE训练,没啥好说的。
预训练代码
import os, platform, time
from typing import Optional
import numpy as np
import pandas as pd
from dataclasses import dataclass,field
from datasets import load_dataset, Dataset
import torch
from transformers.trainer_callback import TrainerControl, TrainerState
from transformers import PreTrainedTokenizerFast, DataCollatorForLanguageModeling, PhiConfig, PhiForCausalLM, Trainer, TrainingArguments, TrainerCallback
# 预训练数据(单纯的文本数据)
TRAIN_FILES = ['./data/wiki_chunk_320_2.2M.parquet',]
EVAL_FILE = './data/pretrain_eval_400_1w.parquet'
@dataclass
class PretrainArguments:
tokenizer_dir: str = './model_save/tokenizer/'
model_save_dir: str = './model_save/pre/'
logs_dir: str = './logs/'
train_files: list[str] = field(default_factory=lambda: TRAIN_FILES)
eval_file: str = EVAL_FILE
max_seq_len: int = 512
attn_implementation: str = 'eager' if platform.system() == 'Windows' else attn_implementation
pretrain_args = PretrainArguments()
# 加载训练好的tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained(pretrain_args.tokenizer_dir)
# 词表大小修正
vocab_size = len(tokenizer)
if vocab_size % 64 != 0:
vocab_size = (vocab_size // 64 + 1) * 64
# 如果词表大小小于 65535 用uint16存储,节省磁盘空间,否则用uint32存储
map_dtype = np.uint16 if vocab_size < 65535 else np.uint32
def token_to_id(samples: dict[str, list]) -> dict:
batch_txt = samples['text']
outputs = tokenizer(batch_txt, truncation=False, padding=False, return_attention_mask=False)
input_ids = [np.array(item, dtype=map_dtype) for item in outputs["input_ids"]]
return {"input_ids": input_ids}
# 加载数据集
def get_maped_dataset(files: str|list[str]) -> Dataset:
dataset = load_dataset(path='parquet', data_files=files, split='train', cache_dir='.cache')
maped_dataset = dataset.map(token_to_id, batched=True, batch_size=1_0000, remove_columns=dataset.column_names)
return maped_dataset
train_dataset = get_maped_dataset(pretrain_args.train_files)
eval_dataset = get_maped_dataset(pretrain_args.eval_file)
# 定义data_collator。`mlm=False`表示要训练CLM模型,`mlm=True`表示要训练MLM模型
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
phi_config = PhiConfig(
vocab_size=vocab_size,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
hidden_size=960,
num_attention_heads=16,
num_hidden_layers=24,
max_position_embeddings=512,
intermediate_size=4096,
attn_implementation=pretrain_args.attn_implementation,
)
model = PhiForCausalLM(phi_config)
# 定义训练参数
my_trainer_callback = MyTrainerCallback() # cuda cache回调函数
args = TrainingArguments(
output_dir=pretrain_args.model_save_dir, per_device_train_batch_size=4,
gradient_accumulation_steps=32, num_train_epochs=4, weight_decay=0.1,
warmup_steps=1000, learning_rate=5e-4, evaluation_strategy='steps',
eval_steps=2000, save_steps=2000, save_strategy='steps', save_total_limit=3,
report_to='tensorboard', optim="adafactor", bf16=True, logging_steps=5,
log_level='info', logging_first_step=True,
)
trainer = Trainer(model=model, tokenizer=tokenizer,args=args,
data_collator=data_collator, train_dataset=train_dataset,
eval_dataset=eval_dataset, callbacks=[my_trainer_callback],
)
trainer.train()
trainer.save_model(pretrain_args.model_save_dir)
这个代码和只要是使用Transformers库的Trainer基本差别不大,大相径庭。
主要是,tokenizer和CausalLM模型的差别。
PhiConfig, PhiForCausalLM 变成:
from transformers import LlamaConfig as PhiConfig
from transformers import LlamaForCausalLM as PhiForCausalLM
或:
from transformers import Qwen2Config as PhiConfig
from transformers import Qwen2ForCausalLM as PhiForCausalLM
就很随意的变成了其他模型的简单预训练了 。
关于训练数据构造,其中,DataCollatorForLanguageModeling:
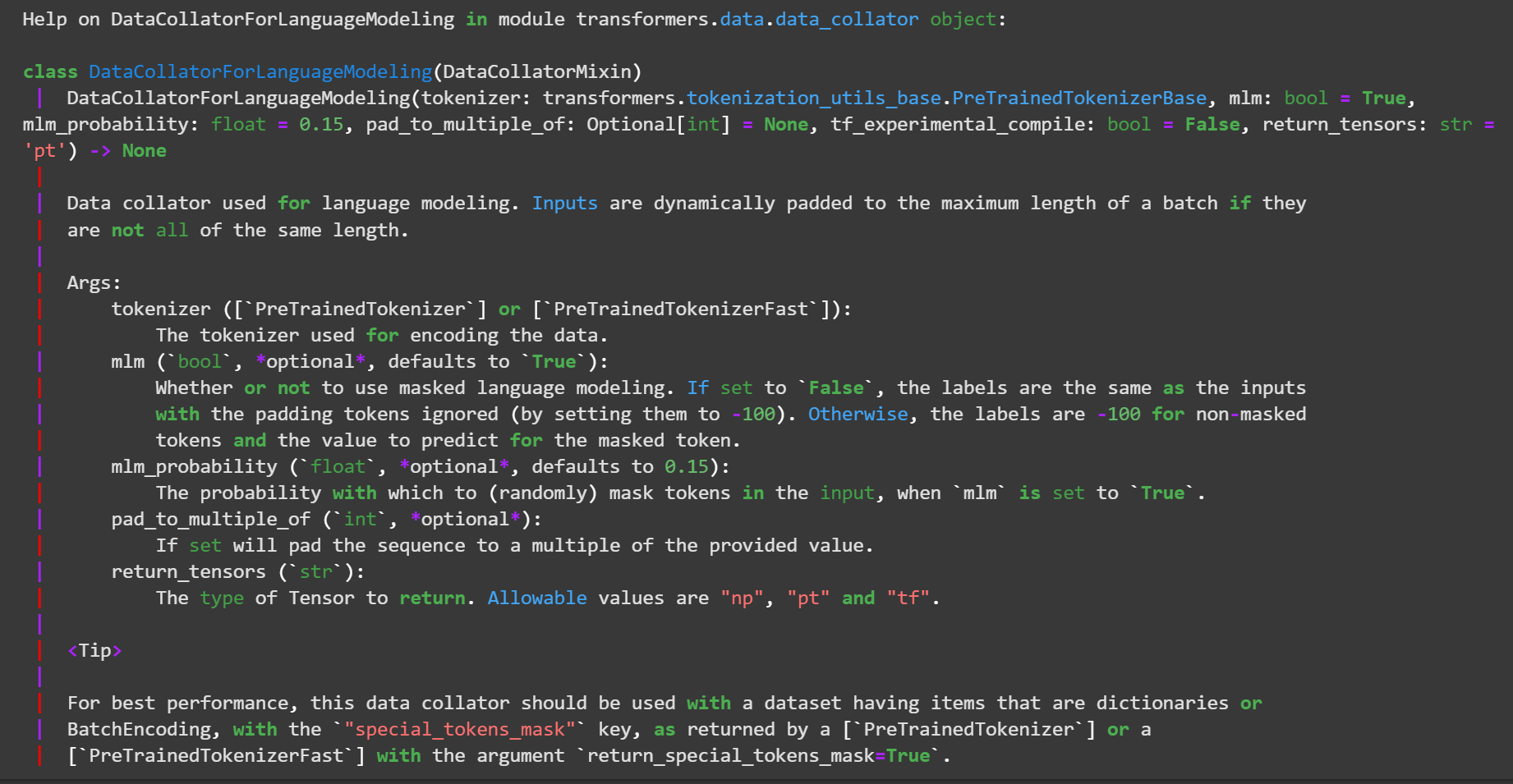
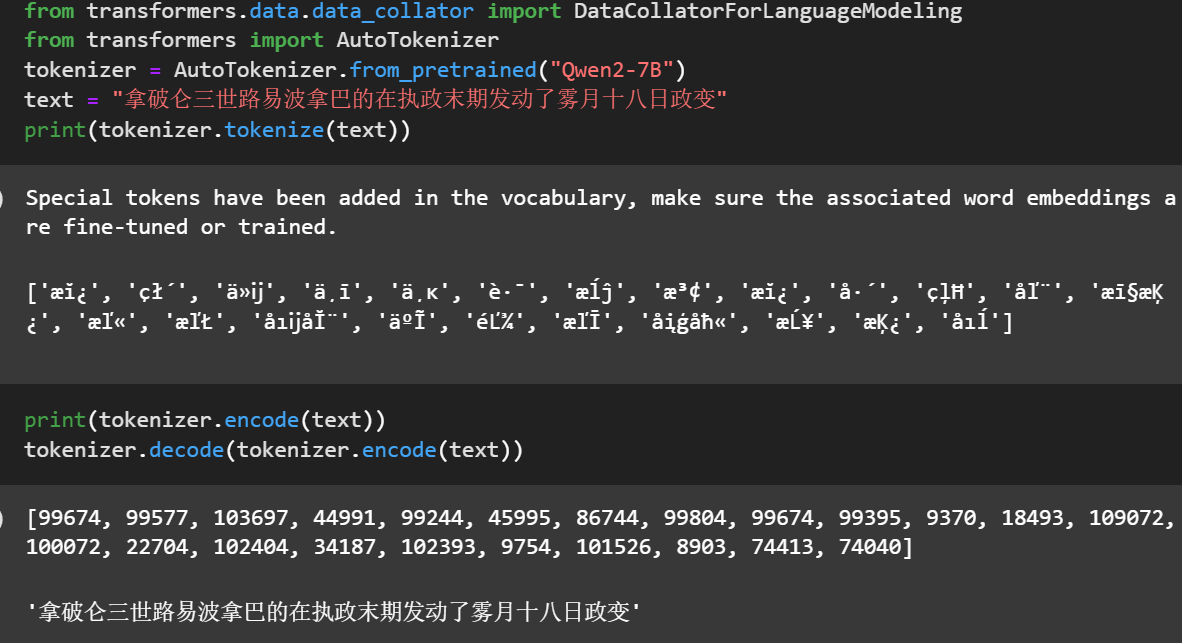
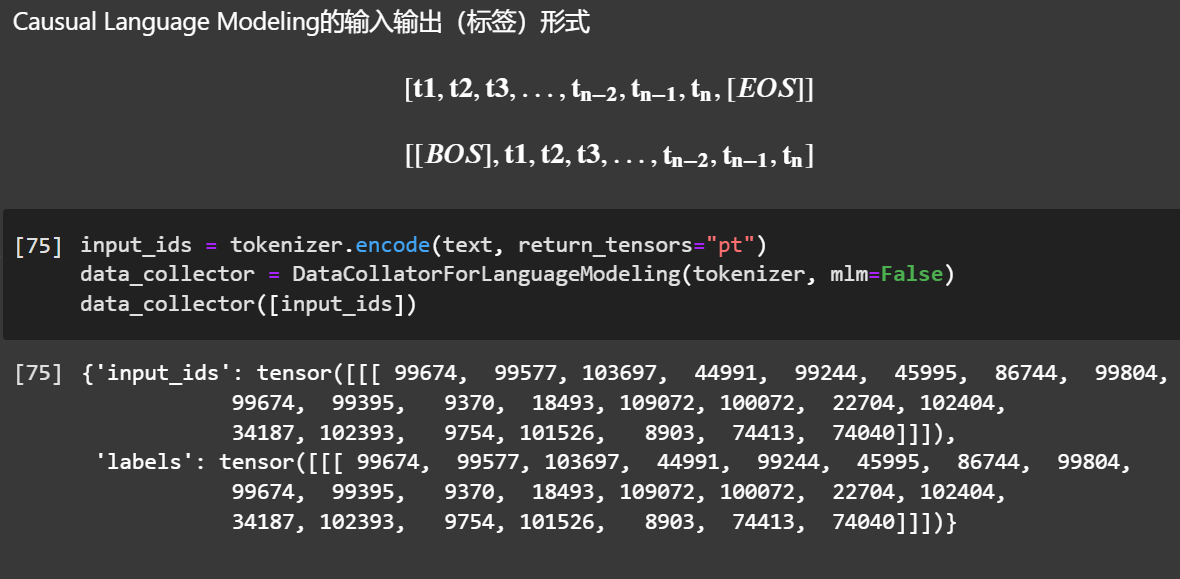
注: get_maped_datasetget_maped_dataset的load_dataset没有加num_proc,导致加载速度慢,加以设置为核心数)
这部分代码和我之前写一个篇基于transformers库训练GPT2大差不差:
https://zhuanlan.zhihu.com/p/685851459
注: get_maped_datasetget_maped_dataset的load_dataset没有加num_proc,导致加载速度慢,加以设置为核心数)
SFT代码
基本和预训练一致,唯一的不同就是,设置了output的标签
import time
import pandas as pd
import numpy as np
import torch
from datasets import load_dataset
from transformers import PreTrainedTokenizerFast, PhiForCausalLM, TrainingArguments, Trainer, TrainerCallback
from trl import DataCollatorForCompletionOnlyLM
# 1. 定义训练数据,tokenizer,预训练模型的路径及最大长度
sft_file = './data/sft_train_data.parquet'
tokenizer_dir = './model_save/tokenizer/'
sft_from_checkpoint_file = './model_save/pre/'
model_save_dir = './model_save/sft/'
max_seq_len = 512
# 2. 加载训练数据集
dataset = load_dataset(path='parquet', data_files=sft_file, split='train', cache_dir='.cache')
tokenizer = PreTrainedTokenizerFast.from_pretrained(tokenizer_dir)
print(f"vicab size: {len(tokenizer)}")
# ## 2.1 定义sft data_collator的指令字符
# 也可以手动将`instruction_template_ids`和`response_template_ids`添加到input_ids中的,因为如果是byte level tokenizer可能将`:`和后面的字符合并,导致找不到`instruction_template_ids`和`response_template_ids`。
# 也可以像下文一样通过在`'#'`和`':'`前后手动加`'\n'`解决
# %%
instruction_template = "##提问:"
response_template = "##回答:"
map_dtype = np.uint16 if len(tokenizer) < 65535 else np.uint32
def batched_formatting_prompts_func(example: list[dict]) -> list[str]:
batch_txt = []
for i in range(len(example['instruction'])):
text = f"{instruction_template}\n{example['instruction'][i]}\n{response_template}\n{example['output'][i]}[EOS]"
batch_txt.append(text)
outputs = tokenizer(batch_txt, return_attention_mask=False)
input_ids = [np.array(item, dtype=map_dtype) for item in outputs["input_ids"]]
return {"input_ids": input_ids}
dataset = dataset.map(batched_formatting_prompts_func, batched=True,
remove_columns=dataset.column_names).shuffle(23333)
# 2.2 定义data_collator
#
data_collator = DataCollatorForCompletionOnlyLM(
instruction_template=instruction_template,
response_template=response_template,
tokenizer=tokenizer,
mlm=False
)
empty_cuda_cahce = EmptyCudaCacheCallback() ## 定义训练过程中的回调函数
my_datasets = dataset.train_test_split(test_size=4096)
# 5. 定义训练参数
model = PhiForCausalLM.from_pretrained(sft_from_checkpoint_file)
args = TrainingArguments(
output_dir=model_save_dir, per_device_train_batch_size=8, gradient_accumulation_steps=8,
num_train_epochs=3, weight_decay=0.1, warmup_steps=1000, learning_rate=5e-5,
evaluation_strategy='steps', eval_steps=2000, save_steps=2000, save_total_limit=3,
report_to='tensorboard', optim="adafactor", bf16=True, logging_steps=10,
log_level='info', logging_first_step=True, group_by_length=True,
)
trainer = Trainer(
model=model, tokenizer=tokenizer, args=args,
data_collator=data_collator,
train_dataset=my_datasets['train'],
eval_dataset=my_datasets['test'],
callbacks=[empty_cuda_cahce],
)
trainer.train()
trainer.save_model(model_save_dir)
总之,虽然都是一套代码,但实际上一切的细节隐藏在:
DataCollatorForLanguageModeling、Trainer、tokenizer和CausalLM的实现中。
更底层的实在pytorch的实现中,不过一般不涉及框架内部的实现分析。
和huggingface的trl库的SFT example,唯一区别就是还是用的Trainer
https://huggingface.co/docs/trl/main/en/sft_trainer#train-on-completions-only
其中,DataCollatorForCompletionOnlyLM会为指令微调式的补全式训练,自动构造样本:
You can use the DataCollatorForCompletionOnlyLM to train your model on the generated prompts only. Note that this works only in the case when packing=False.
对于指令微调式的instruction data, 实例化一个datacollator,传入一个输response的template 和tokenizer。
内部可以进行response部分的token ids的拆分,并指定为预测标签。
下面是HuggingFace官方的使用DataCollatorForCompletionOnlyLM+FTTrainer,进行指令微调的例子:
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer, DataCollatorForCompletionOnlyLM
dataset = load_dataset("timdettmers/openassistant-guanaco", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
instruction_template = "### Human:"
response_template = "### Assistant:"
collator = DataCollatorForCompletionOnlyLM(instruction_template=instruction_template, response_template=response_template, tokenizer=tokenizer, mlm=False)
trainer = SFTTrainer(
model,
args=SFTConfig(
output_dir="/tmp",
dataset_text_field = "text",
),
train_dataset=dataset,
data_collator=collator,
)
trainer.train()
关于Trainer and SFTTrainer的区别,感觉区别不大
https://medium.com/@sujathamudadla1213/difference-between-trainer-class-and-sfttrainer-supervised-fine-tuning-trainer-in-hugging-face-d295344d73f7

DPO代码
import time
import pandas as pd
from typing import List, Optional, Dict
from dataclasses import dataclass, field
import torch
from trl import DPOTrainer
from transformers import PreTrainedTokenizerFast, PhiForCausalLM, TrainingArguments, TrainerCallback
from datasets import load_dataset
# 1. 定义sft模型路径及dpo数据
dpo_file = './data/dpo_train_data.json'
tokenizer_dir = './model_save/tokenizer/'
sft_from_checkpoint_file = './model_save/sft/'
model_save_dir = './model_save/dpo/'
max_seq_len = 320
# 2. 加载数据集
# 数据集token格式化
# DPO数据格式:[prompt模型输入,chosen正例, rejected负例]
# 将dpo数据集三列数据添加上`eos`token,`bos`可加可不加
def split_prompt_and_responses(samples: dict[str, str]) -> Dict[str, str]:
prompts, chosens, rejects = [], [], []
batch_size = len(samples['prompt'])
for i in range(batch_size):
# add an eos token for signal that end of sentence, using in generate.
prompts.append(f"[BOS]{samples['prompt'][i]}[EOS]")
chosens.append(f"[BOS]{samples['chosen'][i]}[EOS]")
rejects.append(f"[BOS]{samples['rejected'][i]}[EOS]")
return {'prompt': prompts, 'chosen': chosens, 'rejected':rejects,}
tokenizer = PreTrainedTokenizerFast.from_pretrained(tokenizer_dir)
dataset = load_dataset(path='json', data_files=dpo_file, split='train', cache_dir='.cache')
dataset = dataset.map(split_prompt_and_responses, batched=True,).shuffle(2333)
# 4. 加载模型
# `model`和`model_ref`开始时是同一个模型,只训练`model`的参数,`model_ref`参数保存不变
model = PhiForCausalLM.from_pretrained(sft_from_checkpoint_file)
model_ref = PhiForCausalLM.from_pretrained(sft_from_checkpoint_file)
# 5. 定义训练中的回调函数
# 清空cuda缓存,dpo要加载两个模型,显存占用较大,这能有效缓解低显存机器显存缓慢增长的问题
class EmptyCudaCacheCallback(TrainerCallback):
log_cnt = 0
def on_log(self, args, state, control, logs=None, **kwargs):
self.log_cnt += 1
if self.log_cnt % 5 == 0:
torch.cuda.empty_cache()
empty_cuda_cahce = EmptyCudaCacheCallback()
# 训练参数
args = TrainingArguments(
output_dir=model_save_dir, per_device_train_batch_size=2, gradient_accumulation_steps=16,
num_train_epochs=4, weight_decay=0.1, warmup_steps=1000, learning_rate=2e-5, save_steps=2000, save_total_limit=3, report_to='tensorboard', bf16=True, logging_steps=10, log_level='info',
logging_first_step=True, optim="adafactor", remove_unused_columns=False, group_by_length=True,
)
trainer = DPOTrainer(
model, model_ref, args=args, beta=0.1,
train_dataset=dataset,tokenizer=tokenizer, callbacks=[empty_cuda_cahce],
max_length=max_seq_len * 2 + 16, # 16 for eos bos
max_prompt_length=max_seq_len,
)
trainer.train()
trainer.save_model(model_save_dir)
碎碎念
深入学习
使用transformers的Traniner以及trl库的训练代码基本上都差不多,因为transformers和trl都封装地很好了。
如何要略微深入细节,建议阅读或debug如下仓库。这两个仓库都是基于pytorch实现的:
- https://github.com/DLLXW/baby-llama2-chinese/tree/main
- https://github.com/jzhang38/TinyLlama/blob/main/pretrain/tinyllama.py
改进
这个项目就是基于Phi2-mini-Chinese,主要就是把phi2换成了qwen,然后直接使用qwen的tokenizer
https://github.com/jiahe7ay/MINI_LLM/
我这边尝试使用了transformers库把qwen2的抽出来,用于训练。
其实,和直接用transformers的Qwen2LMModel没有区别。
感兴趣的可以替换任意主流模型,修改配置,其实也大差不差。
这些代码主要是用于学习用途。只要有点时间,有点卡,不费什么力就可以弄点数据复现走完整个流程。
不过,要训练出的效果还可以的小规模LLM也并不简单。
如果您需要引用本文,请参考:
LeonYi. (Aug. 25, 2024). 《【LLM训练系列】从零开始训练大模型之Phi2-mini-Chinese项目解读》.
@online{title={【LLM训练系列】从零开始训练大模型之Phi2-mini-Chinese项目解读},
author={LeonYi},
year={2024},
month={Sep},
url={https://www.cnblogs.com/justLittleStar/p/18379771},
}
【LLM训练系列】从零开始训练大模型之Phi2-mini-Chinese项目解读的更多相关文章
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- 一个使用fasttext训练的新闻文本分类器/模型
fastext是什么? Facebook AI Research Lab 发布的一个用于快速进行文本分类和单词表示的库.优点是很快,可以进行分钟级训练,这意味着你可以在几分钟时间内就训练好一个分类模型 ...
- 云原生的弹性 AI 训练系列之一:基于 AllReduce 的弹性分布式训练实践
引言 随着模型规模和数据量的不断增大,分布式训练已经成为了工业界主流的 AI 模型训练方式.基于 Kubernetes 的 Kubeflow 项目,能够很好地承载分布式训练的工作负载,业已成为了云原生 ...
- 云原生的弹性 AI 训练系列之二:PyTorch 1.9.0 弹性分布式训练的设计与实现
背景 机器学习工作负载与传统的工作负载相比,一个比较显著的特点是对 GPU 的需求旺盛.在之前的文章中介绍过(https://mp.weixin.qq.com/s/Nasm-cXLtJObjLwLQH ...
- PyTorch如何加速数据并行训练?分布式秘籍大揭秘
PyTorch 在学术圈里已经成为最为流行的深度学习框架,如何在使用 PyTorch 时实现高效的并行化? 在芯片性能提升有限的今天,分布式训练成为了应对超大规模数据集和模型的主要方法.本文将向你介绍 ...
- Optimum + ONNX Runtime: 更容易、更快地训练你的 Hugging Face 模型
介绍 基于语言.视觉和语音的 Transformer 模型越来越大,以支持终端用户复杂的多模态用例.增加模型大小直接影响训练这些模型所需的资源,并随着模型大小的增加而扩展它们.Hugging Face ...
- 将训练集构建成ImageNet模型
以下程序实现将训练集构建为ImageNet模型,训练集图片为56个民族 import java.io.File; import java.io.FileNotFoundException; impor ...
- 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(二)
前言 已完成数据预处理工作,具体参照: 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(一) 设置配置文件 新建目录face_faster_rcn ...
- 【实践】如何利用tensorflow的object_detection api开源框架训练基于自己数据集的模型(Windows10系统)
如何利用tensorflow的object_detection api开源框架训练基于自己数据集的模型(Windows10系统) 一.环境配置 1. Python3.7.x(注:我用的是3.7.3.安 ...
- keras系列︱Sequential与Model模型、keras基本结构功能(一)
引自:http://blog.csdn.net/sinat_26917383/article/details/72857454 中文文档:http://keras-cn.readthedocs.io/ ...
随机推荐
- EasyBPM进销存之物料管理
本文是EasyBPM平台实现进销存系列中的一篇,主要讲述物料的相关的管理. 在ERP系统中,"物料"一词有着广泛的含义,它是所有产品.半成品.在制品.原材料.配套件.协作件.易耗品 ...
- oeasy教您玩转vim - 87 - # 内容查找grep命令
内容查找 grep 回忆 上次我们尝试了一下各种在vi中执行外部程序 可以排序 可以改大小写 还可以用管道 直接对于缓冲buffer文件进行操作 还是很方便的 其实还有一个外部命令很重要 根据内容 ...
- AI时代你一定要知道的Agent概念
这两年,随着人工智能(AI)和计算能力的发展,AI应用的落地速度大大加快.以ChatGPT为代表的AI应用迅速火遍全球,成为打工人的常用工具.紧接着,多模态.AI Agent等各种高大尚的名词也逐渐进 ...
- 缓存框架 Caffeine 的可视化探索与实践
作者:vivo 互联网服务器团队- Wang Zhi Caffeine 作为一个高性能的缓存框架而被大量使用.本文基于Caffeine已有的基础进行定制化开发实现可视化功能. 一.背景 Caffei ...
- mybatisplus实现一次多表联查+分页查询
众所周知,mybatisplus非常好用,但是他不好用就不好用在不可以多表联查.在mybatisplusjoin中提供了联查的方法,那个参数我没看懂Orz 不过,历经千辛万苦,我通过xml终于写出来了 ...
- SEO初学者指南之什么是SEO
前言 Hi,大家好,我是听风.欢迎来到SEO基础入门指南.在这个博客中主要教大家SEO的基础知识,以谷歌SEO为主,重点放在实操方面. 虽然是基础入门教程,但我希望朋友们不要对"初学者&qu ...
- docker 部署redis 并在外部访问 docker命令
docker search redis //搜索redis版本 docker pull redis //拉取最新版本 docker run -d --name redis -p 自定义端口:6379 ...
- appium python 点击坐标 tap
appium python 点击坐标 tap 有时候定位元素的时候,你使出了十八班武艺还是定位不到,怎么办呢?(面试经常会问)那就拿出绝招:点元素所在位置的坐标 tap用法 1.tap是模拟手指点击, ...
- 【DataBase】SQL50 Training 50题训练
原文地址: https://blog.csdn.net/xiushuiguande/article/details/79476964 实验数据 CREATE DATABASE IF NOT EXIST ...
- "基础模型时代的机器人技术" —— Robotics in the Era of Foundation Models
翻译: 2023年是智能机器人规模化的重要一年!对于机器人领域之外的人来说,要传达事物变化的速度和程度是有些棘手的.与仅仅12个月前的情况相比,如今人工智能+机器人领域的大部分景观似乎完全不可识别.从 ...