【6】python生成数据曲线平滑处理——(Savitzky-Golay 滤波器、convolve滑动平均滤波)方法介绍,推荐玩强化学习的小伙伴收藏
相关文章:
Python xlwt数据保存到 Excel中以及xlrd读取excel文件画图

先上效果图:


由于高频某些点的波动导致高频曲线非常难看,为了降低噪声干扰,需要对曲线做平滑处理,让曲线过渡更平滑,可以看出经过平滑处理后更明显去除噪声且更加美观。
1.滑动平均滤波
滑动平均滤波法 (又称:递推平均滤波法),它把连续取N个采样值看成一个队列 ,队列的长度固定为N ,每次采样到一个新数据放入队尾,并扔掉原来队首的一次数据(先进先出原则) 。把队列中的N个数据进行算术平均运算,就可获得新的滤波结果。
优点: 对周期性干扰有良好的抑制作用,平滑度高,适用于高频振荡的系统。
缺点: 灵敏度低,对偶然出现的脉冲性干扰的抑制作用较差,不易消除由于脉冲干扰所引起的采样值偏差,不适用于脉冲干扰比较严重的场合,比较浪费RAM 。
效果如下:卷积核越大越平滑。
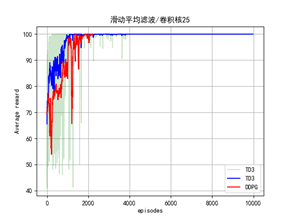
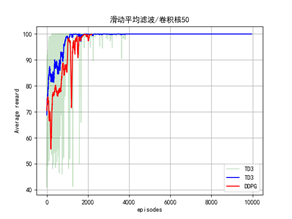

Numpy.convolve函数:(numpy.convolve函数官方文档)
numpy.convolve(data, kernel, mode=‘full’) # 返回a=data和kernel的离散线性卷积。
参数说明:data:(N,)输入的第一个一维数组
kernel:(M,)输入的第二个一维数组
和一维卷积参数类似,data就是被卷积数据,kernel是卷积核大小。
mode:{‘full’, ‘valid’, ‘same’}参数可选,该参数指定np.convolve函数如何处理边缘。
mode可能的三种取值情况:
- full’ 默认值,返回每一个卷积值,长度是N+M-1,在卷积的边缘处,信号不重叠,存在边际效应。
- ‘same’ 返回的数组长度为max(M, N),边际效应依旧存在。
- ‘valid’ 返回的数组长度为max(M,N)-min(M,N)+1,此时返回的是完全重叠的点。边缘的点无效。(推荐这种)
代码如下:
import xlwt
import random
import numpy as np
from scipy.signal import savgol_filter
import matplotlib.pyplot as plt
import xlrd
import scipy
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
x_data=[]
y_data=[]
x_data1=[]
y_data1=[]
x_data3=[]
x_data4=[]
data = xlrd.open_workbook('train_reward.xls')
table = data.sheets()[0]
data1 = xlrd.open_workbook('train_reward_2.xls')
table1 = data1.sheets()[0]
cap = table.col_values(1) #读取第二列数据
cap1 = table.col_values(0)#读取第一列数据
#print(cap) #打印出来检验是否正确读取
cap2 = table1.col_values(1) #读取第二列数据
cap3 = table1.col_values(0)#读取第一列数据
#print(cap) #打印出来检验是否正确读取
for i in range(1,9999):
y_data.append(cap[i])
# x_data.append(cap1[i]*50) #对第一列数据扩大50倍
x_data.append(cap1[i]) #对第一列数据扩大50倍
for i in range(1,2231):
y_data1.append(cap2[i])
# x_data.append(cap1[i]*50) #对第一列数据扩大50倍
x_data1.append(cap3[i]) #对第一列数据扩大50倍
#?平滑处理:
modes = ['full', 'same', 'valid'] #模式
# mode可能的三种取值情况:
# full’ 默认值,返回每一个卷积值,长度是N+M-1,在卷积的边缘处,信号不重叠,存在边际效应。
# ‘same’ 返回的数组长度为max(M, N),边际效应依旧存在。
# ‘valid’ 返回的数组长度为max(M,N)-min(M,N)+1,此时返回的是完全重叠的点。边缘的点无效。
def moving_average(interval, windowsize):
window = np.ones(int(windowsize)) / float(windowsize)
for m in modes:
re = np.convolve(interval, window, 'valid')
return re
for i in range(1,9975):
x_data3.append(i)
for i in range(1,2207):
x_data4.append(i)
plt.plot(x_data, y_data, 'g',label ="TD3",alpha=0.2)
y_av = moving_average(y_data, 25)
plt.plot(x_data3, y_av, 'b',label ="TD3")
y_av2 = moving_average(y_data1, 25)
plt.plot(x_data4, y_av2, 'red',label ="DDPG")
# plt.grid()网格线设置
plt.grid(True)
plt.title('滑动平均滤波/卷积核25')
plt.legend()#标签
plt.xlabel('episodes')
plt.ylabel('Average reward')
plt.show()
2. Savitzky-Golay 滤波器实现曲线平滑
对曲线进行平滑处理,通过Savitzky-Golay 滤波器,可以在scipy库里直接调用,不需要再定义函数。
代码语法:
python中Savitzky-Golay滤波器调用如下:
y_smooth = scipy.signal.savgol_filter(y,53,3)
# 亦或
y_smooth2 = savgol_filter(y, 99, 1, mode= 'nearest')
# 备注:
y:代表曲线点坐标(x,y)中的y值数组
window_length:窗口长度,该值需为正奇整数。例如:此处取值53
k值:polyorder为对窗口内的数据点进行k阶多项式拟合,k的值需要小于window_length。例如:此处取值3
mode:确定了要应用滤波器的填充信号的扩展类型。(This determines the type of extension to use for the padded signal to which the filter is applied. )
(1)window_length对曲线的平滑作用: window_length的值越小,曲线越贴近真实曲线;window_length值越大,平滑效果越厉害(备注:该值必须为正奇整数)。
(2)k值对曲线的平滑作用: k值越大,曲线越贴近真实曲线;k值越小,曲线平滑越厉害。另外,当k值较大时,受窗口长度限制,拟合会出现问题,高频曲线会变成直线。
- Savitzky-Golay平滑滤波是光谱预处理中的常用滤波方法,其核心思想:是对一定长度窗口内的数据点进行k阶多项式拟合,从而得到拟合后的结果。 对它进行离散化处理后,S-G 滤波其实是一种移动窗口的加权平均算法,但是其加权系数不是简单的常数窗口,而是通过在滑动窗口内对给定高阶多项式的最小二乘拟合得出。
- Savitzky-Golay平滑滤波被广泛地运用于数据流平滑除噪,是一种在时域内基于局域多项式最小二乘法拟合的滤波方法。这种滤波器的 最大特点:在滤除噪声的同时可以确保信号的形状、宽度不变
- 使用平滑滤波器对信号滤波时,实际上是拟合了信号中的低频成分,而将高频成分平滑出去了。 如果噪声在高频端,那么滤波的结果就是去除了噪声,反之,若噪声在低频段,那么滤波的结果就是留下了噪声。
效果如下:

代码如下:
import xlwt
import random
import numpy as np
from scipy.signal import savgol_filter
import matplotlib.pyplot as plt
import xlrd
import scipy
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
x_data=[]
y_data=[]
x_data1=[]
y_data1=[]
data = xlrd.open_workbook('train_reward.xls')
table = data.sheets()[0]
data1 = xlrd.open_workbook('train_reward_2.xls')
table1 = data1.sheets()[0]
cap = table.col_values(1) #读取第二列数据
cap1 = table.col_values(0)#读取第一列数据
#print(cap) #打印出来检验是否正确读取
cap2 = table1.col_values(1) #读取第二列数据
cap3 = table1.col_values(0)#读取第一列数据
#print(cap) #打印出来检验是否正确读取
for i in range(1,9999):
y_data.append(cap[i])
# x_data.append(cap1[i]*50) #对第一列数据扩大50倍
x_data.append(cap1[i]) #对第一列数据扩大50倍
for i in range(1,2321):
y_data1.append(cap2[i])
# x_data.append(cap1[i]*50) #对第一列数据扩大50倍
x_data1.append(cap3[i]) #对第一列数据扩大50倍
#?平滑处理:
tmp_smooth1 = scipy.signal.savgol_filter(y_data,25,3)
# tmp_smooth2 = scipy.signal.savgol_filter(y_data,63,4)
plt.semilogx(x_data,y_data,label = "TD3",alpha=0.2) #//增加透明度
plt.semilogx(x_data,tmp_smooth1,label = 'TD3-smooth',color = 'red')
# plt.semilogx(x_data,tmp_smooth2,label = 'mic'+str(1)+'拟合曲线-53',color = 'green')
tmp_smooth3 = scipy.signal.savgol_filter(y_data1,25,3)
#% window_length的值越小,曲线越贴近真实曲线;window_length值越大,平滑效果越厉害
#! k值推荐3-5k值越大,曲线越贴近真实曲线;k值越小,曲线平滑越厉害。另外,当k值较大时,受窗口长度限制,拟合会出现问题,高频曲线会变成直线
# tmp_smooth2 = scipy.signal.savgol_filter(y_data,63,4)
plt.semilogx(x_data1,y_data1,label = "DDPG",alpha=0.3) #//增加透明度
plt.semilogx(x_data1,tmp_smooth3,label = 'DDPG-smooth',color = 'blue')
# plt.plot(x_data, y_data,color="#006bac")
plt.title('Savitzky-Golay 滤波器25/3')
plt.legend()#标签
plt.xlabel('episodes')
plt.ylabel('Average reward')
plt.show()
参考链接:
python 数据、曲线平滑处理——方法总结(Savitzky-Golay 滤波器、make_interp_spline插值法和convolve滑动平均滤波)
【6】python生成数据曲线平滑处理——(Savitzky-Golay 滤波器、convolve滑动平均滤波)方法介绍,推荐玩强化学习的小伙伴收藏的更多相关文章
- [开发技巧]·Python极简实现滑动平均滤波(基于Numpy.convolve)
[开发技巧]·Python极简实现滑动平均滤波(基于Numpy.convolve) 1.滑动平均概念 滑动平均滤波法(又称递推平均滤波法),时把连续取N个采样值看成一个队列 ,队列的长度固定为N ...
- python生成数据后,快速导入数据库
1.使用python生成数据库文件内容 # coding=utf-8import randomimport time def create_user(): start = time.time() ...
- Python小数据保存,有多少中分类?不妨看看他们的类比与推荐方案...
小数据存储 我们在编写代码的时候,经常会涉及到数据存储的情况,如果是爬虫得到的大数据,我们会选择使用数据库,或者excel存储.但如果只是一些小数据,或者说关联性较强且存在存储后复用的数据,我们该如何 ...
- python基础——4(数字、字符串、列表类型的内置方法介绍)
目录 一.可变与不可变类型 二.数字类型 三.字符串类型 四.列表类型 一.可变与不可变类型 可变类型:值改变,但是id不变,证明就是在改变原值,是可变类型 不可变类型:值改变,id也跟着改变,证明产 ...
- Python大数据与机器学习之NumPy初体验
本文是Python大数据与机器学习系列文章中的第6篇,将介绍学习Python大数据与机器学习所必须的NumPy库. 通过本文系列文章您将能够学到的知识如下: 应用Python进行大数据与机器学习 应用 ...
- JavaScript 解析 Django Python 生成的 datetime 数据 时区问题解决
JavaScript 解析 Django/Python 生成的 datetime 数据 当Web后台使用Django时,后台生成的时间数据类型就是Python类型的. 项目需要将几个时间存储到数据库中 ...
- Python中数据的保存和读取
在科学计算的过程中,往往需要保存一些数据,也经常需要把保存的这些数据加载到程序中,在 Matlab 中我们可以用 save 和 lood 函数很方便的实现.类似的在 Python 中,我们可以用 nu ...
- python 生成18年写过的博客词云
文章链接:https://mp.weixin.qq.com/s/NmJjTEADV6zKdT--2DXq9Q 回看18年,最有成就的就是有了自己的 博客网站,坚持记录,写文章,累计写了36篇了,从一开 ...
- python爬虫+数据可视化项目(关注、持续更新)
python爬虫+数据可视化项目(一) 爬取目标:中国天气网(起始url:http://www.weather.com.cn/textFC/hb.shtml#) 爬取内容:全国实时温度最低的十个城市气 ...
- python调用数据返回字典dict数据的现象2
python调用数据返回字典dict数据的现象2 思考: 话题1连接:https://www.cnblogs.com/zwgbk/p/10248479.html在打印和添加时候加上内存地址id(),可 ...
随机推荐
- Hugging News #0918: Hub 加入分类整理功能、科普文本生成中的流式传输
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- VS Code的C/C++环境配置的傻瓜式教程(看这一篇就够了)
html: toc: true VS Code的C/C++环境配置的傻瓜式教程(看这一篇就够了) 写在前面的话 作者在学习使用vscode写C代码的时候,根据网上很多参差不齐的教程踩了不少的坑,很多教 ...
- MB21 预留
1.MB21创建预留 1.1MB21前台操作 输入物料等信息,保存即可 1.2调用BAPI:BAPI_RESERVATION_CREATE1 "----------------------- ...
- 在Windows上D盘上安装Docker
Reference https://www.willh.cn/articles/2022/07/13/1657676401964.html Docker默认安装在C盘: "C:\Progra ...
- Educational Codeforces Round 93 (Rated for Div. 2)
Educational Codeforces Round 93 (Rated for Div. 2) A. Bad Triangle input 3 7 4 6 11 11 15 18 20 4 10 ...
- Codeforces Round #681 (Div. 2, based on VK Cup 2019-2020 - Final) 个人题解(A - D)
1443A. Kids Seating 题意: 给你一个整数n,现在你需要从编号 \(1\) ~ $4 ⋅ n \(中选出\)n\(个编号使得这些编号之间\)g c d ≠ 1$ ,不能整除. 看了半 ...
- 版本升级 | v3.0.0卷起来了!多种特殊情况解析轻松拿捏!
在过往发行版的基础上,结合社区用户提供的大量反馈及研发小伙伴的积极探索,项目组对OpenSCA的解析引擎做了全方位的优化,v3.0.0版本正式发布啦~ 感谢所有用户的支持和信任~是很多人的一小步聚在一 ...
- kafka集群六、java操作kafka(没有密码验证)
系列导航 一.kafka搭建-单机版 二.kafka搭建-集群搭建 三.kafka集群增加密码验证 四.kafka集群权限增加ACL 五.kafka集群__consumer_offsets副本数修改 ...
- 响应式开发bootstrap
响应式开发原理 就是使用媒体查询针对不同宽度的设备进行布局和样式的设置,从而适配不同设备的目的. 平时我们响应式尺寸划分 超小屏幕(手机,小于768px):设置宽度为100% 小屏幕(平板,大于等于7 ...
- ElasticSearch 通过 Kibana 与 ElasticSearch-head 完成增删改查
本文为博主原创,未经允许不得转载: 1. 安装并配置 elasticSearch ,kibana, elasticsearch-head docker 安装 ElasticSearch 和 Kiba ...