重磅!KubeEdge单集群突破10万边缘节点|云原生边缘计算峰会前瞻
摘要:《KubeEdge单集群突破10万边缘节点 | 技术报告》将会在6月25日即将开展的云原生边缘计算峰会(KubeEdge Summit 2022)中进行应用解析。我们先来一睹为快吧!
近日, 云原生边缘计算KubeEdge社区开展了支持100000边缘节点大规模测试。在边缘计算行业应用的高速发展时期,作为CNCF唯一孵化级的云原生边缘计算项目,KubeEdge在智能交通、智慧城市、智慧园区、智慧能源、智慧工厂、智慧银行、智慧工地、CDN等行业发挥着全面的驱动作用。本次大规模测试,KubeEdge单集群突破10万边缘节点!
《KubeEdge单集群突破10万边缘节点 | 技术报告》也会在6月25日即将开展的云原生边缘计算峰会(KubeEdge Summit 2022)中进行应用解析。我们先来一睹为快吧!

摘要
随着KubeEdge在越来越多的企业以及组织大规模落地,KubeEdge可扩展性和大规模逐步成为社区用户新的关注点。因此,我们开展了KubeEdge的大规模测试工作,现在我们宣布Kubernetes + KubeEdge集群能够稳定支持100,000边缘节点同时在线,并且管理超过1,000,000的pod。在本篇文章中,我们将介绍测试使用的相关指标,如何开展的大规模测试以及我们如何实现大规模边缘节点接入。
背景介绍
随着5G网络、工业互联网、AI等领域的高速发展,边缘计算成为引领数字化发展的潮流。智慧城市、智慧交通、智慧医疗、智能制造等未来场景更多被人熟知,边缘计算也受到了空前的关注。Gartner里面明确提出,到2023年,网络边缘的智能设备数量可能是传统IT的20倍以上。到2028年,传感器、存储、计算和高级人工智能功能在边缘设备中的嵌入将稳步增长。由于物联网设备本身存在类型繁杂和数量众多的特点,物联网设备接入的数量级增加的同时,给我们的统一管理和运维带来了巨大的挑战。
与此同时,KubeEdge社区的用户也提出了大规模边缘节点和应用管理的诉求。基于KubeEdge的高速取消省界项目中,在全国的省界收费站拥有将近10万边缘节点,超过50万边缘应用接入,并且随着项目的演进,边缘节点和应用规模将进一步扩大。使用KubeEdge打造的车云协同管理平台,是汽车行业的首款“云、边、端”一体化架构,助力软件定义汽车实现软件快速升级迭代。在此平台中,每一辆汽车,均作为一个边缘节点接入,边缘节点的规模将达到数百万级别。
KubeEdge简介
KubeEdge是面向边缘计算场景、专为边云协同设计的业界首个云原生边缘计算框架,在 Kubernetes 原生的容器编排调度能力之上实现了边云之间的应用协同、资源协同、数据协同和设备协同等能力,完整打通了边缘计算中云、边、设备协同的场景。
KubeEdge架构主要包含云边端三部分,云上是统一的控制面,包含原生的Kubernetes管理组件,以及KubeEdge自研的CloudCore组件,负责监听云端资源的变化,提供可靠和高效的云边消息同步。边侧主要是EdgeCore组件,包含Edged、MetaManager、EdgeHub等模块,通过接收云端的消息,负责容器的生命周期管理。端侧主要是device mapper和eventBus,负责端侧设备的接入。
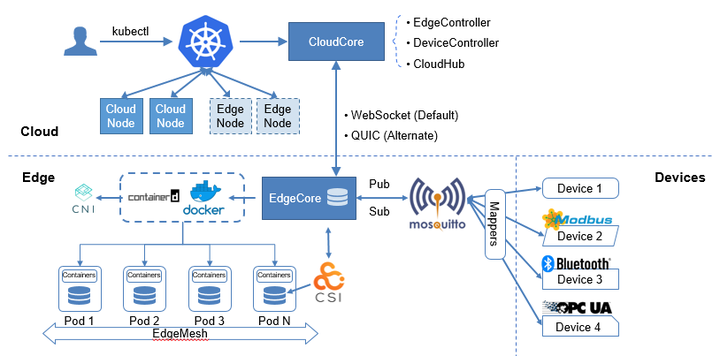
KubeEdge以Kubernetes管控面作为底座,通过将节点拉远的方式,扩展了边云之间的应用协同、资源协同、数据协同和设备协同等能力。 目前,Kubernetes社区官方支持的规模是5,000 个节点和150,000 个Pod,在边缘计算的场景,随着万物互联时代的到来,这种规模是远远不够的。大规模边缘设备的接入,对边缘计算平台的可扩展性和集中管理的需求将会增加,如何使用尽可能少的云端资源和集群,管理尽可能多的边缘设备,简化基础设施的管理和运维。KubeEdge在全面兼容Kubernetes原生能力的基础上,对云边消息通道和传输机制进行了优化,突破了原生Kubernetes的管理规模,支撑更大规模的边缘节点接入和管理。
SLIs/SLOs
可扩展性和性能是Kubernetes集群的重要特性,作为K8s集群的用户,期望在以上两方面有服务质量的保证。在进行Kubernetes + KubeEdge大规模性能测试前,我们需要定义如何衡量集群大规模场景下服务指标。Kubernetes社区定义了以下几种SLIs(Service Level Indicator)/SLOs(service-level objective)指标项,我们将使用这些指标来衡量集群服务质量。
1.API Call Latency

2.Pod Startup Latency

社区还定义了In-Cluster Network Programming Latency(Service更新或者其Ready Pod变化最终反映到Iptables/IPVS规则的时延),In-cluster network latency,DNS Programming Latency( Service更新或者其Ready Pod 反映到dns server的时延), DNS Latency等指标,这些指标当前还尚未量化。满足所有SLO 为大规模集群测试的目标,因此本报告主要针对Official状态SLIs/SLOs进行测试。
Kubernetes 可伸缩性维度和阈值
Kubernetes的可伸缩特性不单指节点规模,即Scalability != #nodes,实际上Kubernetes可伸缩性包含很多维度的测量标准,包含namespaces的数量,Pod的数量,service的数量,secrets/configmap的数量等。下图是Kubernetes社区定义的描述集群可扩展性的重要维度(尚在持续更新中):
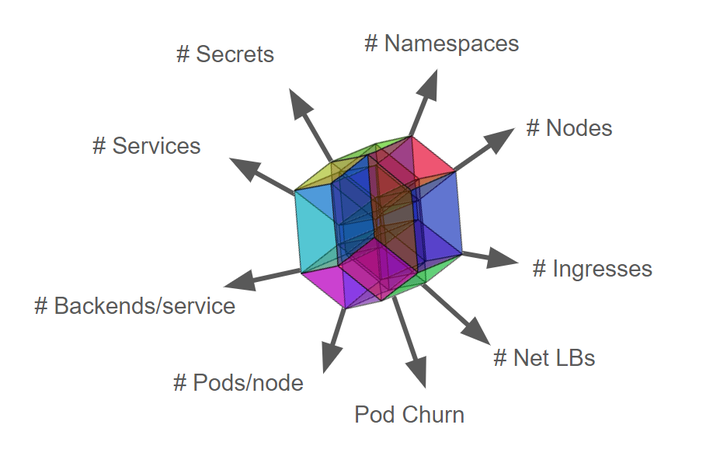
Kubernetes集群无限制扩展资源对象而且又满足SLIs/SLOs各项指标显然是不可能实现的,为此业界定义了Kubernetes多个维度资源上限。
- Pods/node 30
- Backends <= 50k & Services <= 10k & Backends/service <= 250
- Pod churn 20/s
- Secret & configmap/node 30
- Namespaces <= 10k & Pods <= 150k & Pods/namespace <= 3k
- …..
各个维度不是完全独立的,某个维度被拉伸相应的其他维度就要被压缩,可以根据使用场景进行调整。例如5k node 拉伸到10k node 其他维度的规格势必会受到影响。如果各种场景都进行测试分析工作量是非常巨大的,在本次测试中,我们会重点选取典型场景配置进行测试分析。在满足SLIs/SLOs的基础上,实现单集群支持100k边缘节点,1000k pod规模管理。
测试工具
ClusterLoader2
ClusterLoader2是一款开源Kubernetes集群负载测试工具,该工具能够针对Kubernetes 定义的SLIs/SLOs 指标进行测试,检验集群是否符合各项服务质量标准。此外Clusterloader2为集群问题定位和集群性能优化提供可视化数据。ClusterLoader2 最终会输出一份Kubernetes集群性能报告,展示一系列性能指标测试结果。
Clusterloader2性能指标:
- APIResponsivenessPrometheusSimple
- APIResponsivenessPrometheus
- CPUProfile
- EtcdMetrics
- MemoryProfile
- MetricsForE2E
- PodStartupLatency
- ResourceUsageSummary
- SchedulingMetrics
- SchedulingThroughput
- WaitForControlledPodsRunning
- WaitForRunningPods
Edgemark
Edgemark是类似于Kubemark的性能测试工具, 主要用于KubeEdge集群可扩展性测试中,用来模拟KubeEdge边缘节点,在有限资源的情况下构建超大规模Kubernetes+KubeEdge集群,目标是暴露只有在大规模集群情况下才会出现的集群管理面问题。Edgemark部署方式如下图:
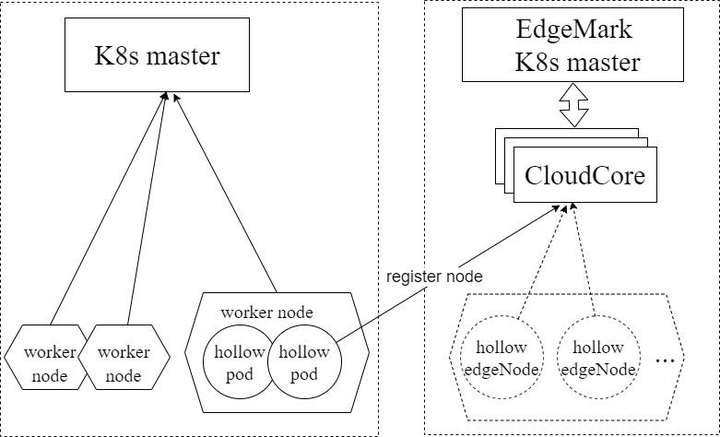
- k8s master --- Kubernetes物理集群主节点
- edgemark master --- Kubernetes模拟集群主节点
- CloudCore --- KubeEdge云端管理组件,负责边缘节点的接入
- hollow pod --- 在物理集群上启动的pod,通过在pod内启动edgemark向edgemark master注册成为一台虚拟边缘节点,edgemark master可以向该虚拟边缘节点上调度pod
- hollow edgeNode --- 模拟集群中可见的节点,为虚拟节点,由hollow pod注册获得
测试集群部署方案
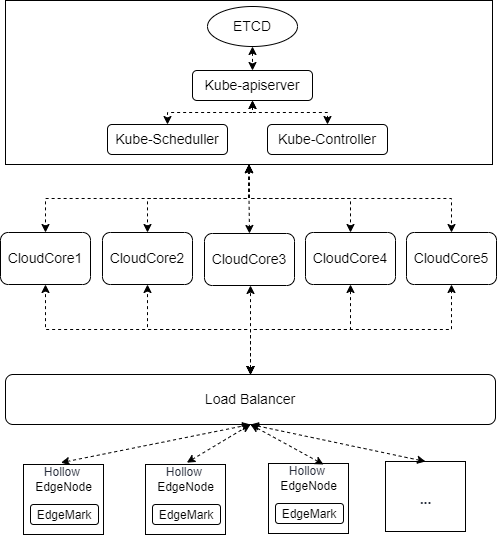
Kubernetes底座管理面采用单master进行部署,ETCD、Kube-apiserver、Kube-Scheduler、Kube-Controller均为单实例部署,KubeEdge管理面CloudCore采用5实例部署,通过master节点IP连接Kube-apiserver,南向通过Load Balancer对外暴漏服务,边缘节点通过Load Balancer轮询策略随机连接到某一个CloudCore实例。
测试环境信息
1、管理面OS版本
CentOS 7.9 64bit 3.10.0-1160.15.2.el7.x86_64
2、Kubernetes 版本
Major:"1", Minor:"23", GitVersion:"v1.23.4", GitCommit:"e6c093d87ea4cbb530a7b2ae91e54c0842d8308a", GitTreeState:"clean", BuildDate:"2022-02-16T12:38:05Z", GoVersion:"go1.17.7", Compiler:"gc", Platform:"linux/amd64"
3、KubeEdge版本
KubeEdge v1.11.0-alpha.0
4、Master节点配置
- CPU
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Platinum 8378A CPU @ 3.00GHz
Stepping: 6
CPU MHz: 2999.998
- MEMORY
Total online memory: 256G
- ETCD DISK
Type: SAS_SSD
Size: 300GB
5、CloudCore节点配置
- CPU
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Platinum 8378A CPU @ 3.00GHz
Stepping: 6
CPU MHz: 2999.998
- MEMORY
Total online memory: 48G
组件参数配置
1、kube-apiserver 参数
--max-requests-inflight=2000
--max-mutating-requests-inflight=1000
2、kube-controller-manager 参数
--kube-api-qps=100
--kube-api-burst=100
3、kube-scheduler 参数
--kube-api-qps=200
--kube-api-burst=400
4、CloudCore参数配置
apiVersion: cloudcore.config.kubeedge.io/v1alpha1
kind: CloudCore
kubeAPIConfig:
kubeConfig: ""
master: ""
qps: 60000
burst: 80000
modules:
cloudHub:
advertiseAddress:
- xx.xx.xx.xx
nodeLimit: 30000
tlsCAFile: /etc/kubeedge/ca/rootCA.crt
tlsCertFile: /etc/kubeedge/certs/server.crt
tlsPrivateKeyFile: /etc/kubeedge/certs/server.key
unixsocket:
address: unix:///var/lib/kubeedge/kubeedge.sock
enable: false
websocket:
address: 0.0.0.0
enable: true
port: 10000
cloudStream:
enable: false
deviceController:
enable: false
dynamicController:
enable: false
edgeController:
buffer:
configMapEvent: 102400
deletePod: 10240
endpointsEvent: 1
podEvent: 102400
queryConfigMap: 10240
queryEndpoints: 1
queryNode: 10240
queryPersistentVolume: 1
queryPersistentVolumeClaim: 1
querySecret: 10240
queryService: 1
queryVolumeAttachment: 1
ruleEndpointsEvent: 1
rulesEvent: 1
secretEvent: 1
serviceEvent: 10240
updateNode: 15240
updateNodeStatus: 30000
updatePodStatus: 102400
enable: true
load:
deletePodWorkers: 5000
queryConfigMapWorkers: 1000
queryEndpointsWorkers: 1
queryNodeWorkers: 5000
queryPersistentVolumeClaimWorkers: 1
queryPersistentVolumeWorkers: 1
querySecretWorkers: 1000
queryServiceWorkers: 1
queryVolumeAttachmentWorkers: 1
updateNodeStatusWorkers: 10000
updateNodeWorkers: 5000
updatePodStatusWorkers: 20000
ServiceAccountTokenWorkers: 10000
nodeUpdateFrequency: 60
router:
enable: false
syncController:
enable: true
Density测试
测试执行
在使用ClusterLoader2进行性能测试之前,我们需要自己通过配置文件定义性能测试策略, 本次测试我们使用官方的 Kubernetes density 测试用例,使用的配置文件如下链接所示:
https://github.com/kubernetes/perf-tests/blob/master/clusterloader2/testing/density/config.yaml
Kubernetes资源详细的配置如下表所示:
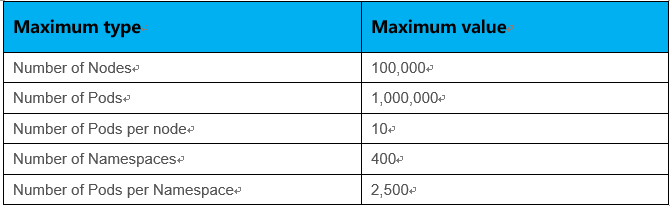
详细的测试方法和过程,可以参考
https://github.com/kubeedge/kubeedge/tree/master/build/edgemark
https://github.com/kubernetes/perf-tests/blob/master/clusterloader2/docs/GETTING_STARTED.md
测试结果
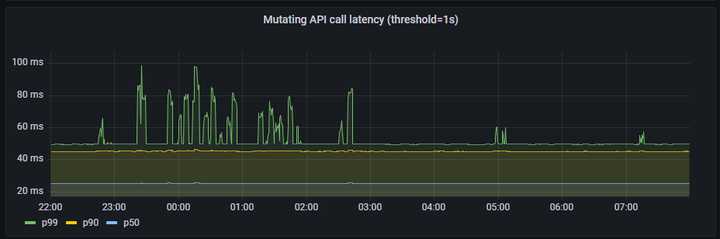
APIResponsivenessPrometheusSimple:
1、mutating API latency(threshold=1s):
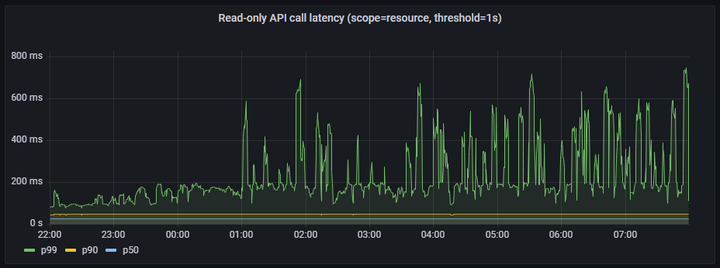
2、Read-only API call latency(scope=resource, threshold=1s)
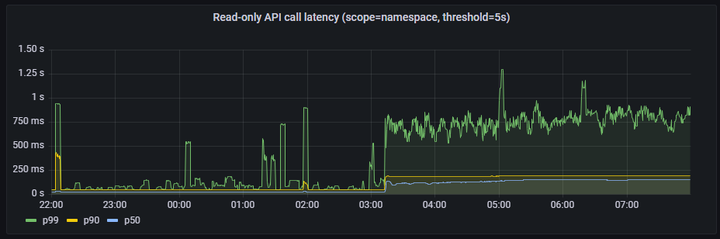
3、Read-only API call latency(scope=namespace, threshold=5s)
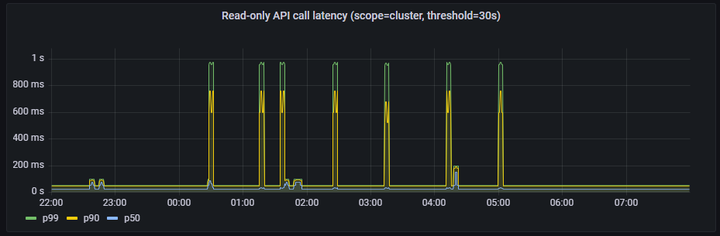
4、Read-only API call latency(scope=cluster, threshold=30s)
PodStartupLatency:
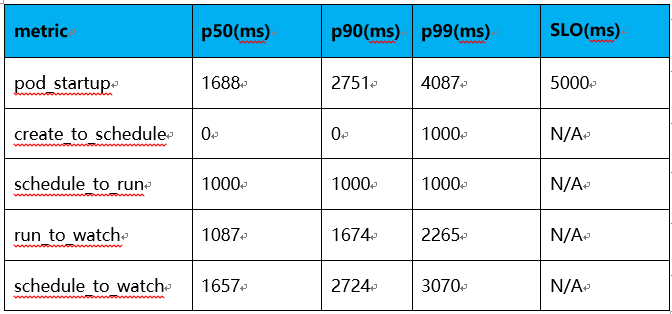
注:延迟时间理论上应该总是大于零的,因为kube-apiserver不支持RFC339NANO,导致时间戳精度只能达到秒级,故在延迟比较小的情况下,由于精度损失,ClusterLoader2统计到的某些数值为0。
结论及分析
在以上的测试结果中,API Call Latency和Pod Startup Latency均符合Kubernetes社区定义的SLIs/SLOs指标。因此,Kubernetes + KubeEdge集群能够稳定支持100,000边缘节点同时在线,并且管理超过1,000,000的pod。在实际的生产环境中,因为网络安全、分区管理等相关问题,边缘节点和云端的网络并不会一直保持联通,会根据运维等需要按需连通网络,因此根据实际的边缘节点的在离线比例,单集群可以管理边缘节点的规模可以同比例的放大。此外,在Kubernetes控制面叠加使用数据分片技术,将不同的资源存储到相应的etcd存储,可以很容易突破更大的规模。
KubeEdge如何实现大规模边缘节点接入
1)高效的云边消息通道
List-watch是Kubernetes组件内部统一的异步消息处理机制,list-watch由list和watch两部分组成。list通过调用资源的list API获取资源,可以获取资源的全量数据,基于HTTP短链接实现;watch通过调用资源的watch API监测资源变更事件,持续获取资源的增量变化数据,基于HTTP长链接和分块传输编码实现。在原生的Kubernetes中,每个node节点除了list-watch node本身、分配到本节点的pod以及全量的service元数据外,Kubelet 还必须watch(默认)运行的Pod使用数据卷挂载的 Secret 和 ConfigMap,在大规模的集群中,随着节点和pod规模的增加,list-watch的数量是非常大的,极大的增加了Kube-apiserver的负担。
KubeEdge采用双向多路复用的边云消息通道,支持websocket(默认)和quic协议,边缘侧EdgeCore主动发起和云端CloudCore连接,CloudCore list-watch Kubernetes资源的变化,并通过云边双向通道主动将元数据下发至边缘测。上行元数据,如边缘侧节点状态和应用状态,EdgeCore通过云边通道上传至CloudCore,CloudCore将接收到的元数据上报到kube-apiserver。
CloudCore统一负责上行和下行数据的汇聚处理,Kube-apiserver只有来自CloudCore的数个 list-watch请求,极大的降低了Kube-apiserver的负担,集群的性能得到了提高。
在同等节点和pod规模下,原生Kubernetes kube-apiserver的memory使用

Kubernetes + KubeEdge场景下,kube-apiserver的memory使用

2)可靠和增量的云边数据传输
在边缘网络拓扑复杂、网络通信质量低的场景下,云边通信面临着网络时延高、闪断闪连、频繁断连等问题。当云边网络恢复,边缘节点重新连接到云端时,边缘到云端会产生大量的全量List请求,从而对Kube-apiserver造成比较大的压力。在大规模场景下,将会给系统稳定性带来不小的挑战。KubeEdge采用基于增量数据的云边推送模式,云端会记录成功发送到边缘侧的元数据版本号,当云边网络中断重新连接时,云端会从记录的元数据版本号开始增量发送,可以解决边缘重连或者watch失败时的重新全量list引发的kube-apiserver压力问题,相比原生Kubernetes架构可以提升系统稳定性,保障在高时延、低质量网络环境下正常工作。
3)边缘极致轻量+云边消息优化
KubeEdge边缘侧EdgeCore对原生的kubelet进行了裁剪,去除了in-tree volume、cloud-provider等边缘场景下用不到的特性,压缩节点上报的状态信息,以及通过优化边缘代理软件资源占用,EdgeCore最低开销只需70MB内存,最小可支持百兆边缘设备。同时,通过WebSocket通道统一管理所有的云边连接,以及对云边的消息合并,数据压缩等,大幅减少云边的通信压力,减轻了对管理面的访问压力,保障在高时延高抖动下仍可正常工作。
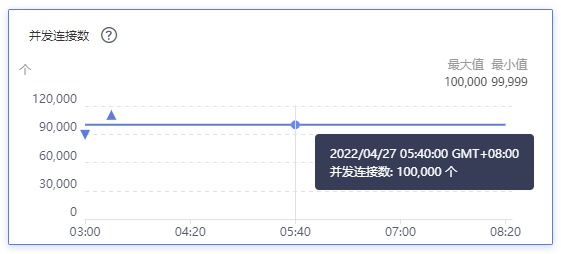
100,000边缘节点接入下,云端ELB连接数为100,000。
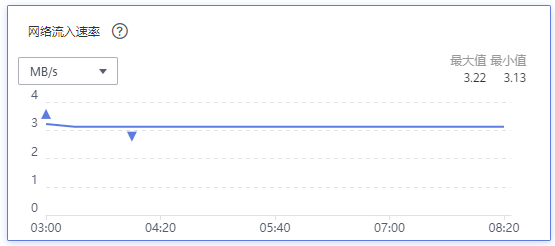
100,000边缘节点以及超过1,000,000 pod场景下,云端ELB网络流入速率约为3MB/s, 平均到每个边缘节点上行带宽约为0.25Kbps。
下一步计划
目前我们只是测试了大规模场景下节点和pod的场景,下一步我们将对边缘设备device、边云消息、边缘服务网格进行针对性测试。此外,针对边缘的一些特殊场景,如大规模节点网络中断重连、边缘网络高时延、闪断闪连等,我们需要引入新的 SLIs/SLOs来衡量集群的服务质量,并进行进一步的大规模测试。
2022年6月25日,CNCF KubeEdge社区首届云原生边缘计算峰会(KubEdge Summit 2022)将在北京/线上同步进行。本次峰会,是面向开发者的一场技术盛会,聚合行业伙伴、开发者、业界大咖、技术专家,聚焦边缘计算最为关切的话题,激发一体化的边端云协同解决效能,让边缘计算的应用实践触手可及。KubeEdge社区诚邀全球开发者、企业共话行业新机遇!

华为伙伴暨开发者大会2022火热来袭,重磅内容不容错过!
【精彩活动】
勇往直前·做全能开发者→12场技术直播前瞻,8大技术宝典高能输出,还有代码密室、知识竞赛等多轮神秘任务等你来挑战。即刻闯关,开启终极大奖!点击踏上全能开发者晋级之路吧!
【技术专题】
未来已来,2022技术探秘→华为各领域的前沿技术、重磅开源项目、创新的应用实践,站在智能世界的入口,探索未来如何照进现实,干货满满点击了解
重磅!KubeEdge单集群突破10万边缘节点|云原生边缘计算峰会前瞻的更多相关文章
- KubeEdge:下一代云原生边缘设备管理标准DMI的设计与实现
摘要:KubeEdge设备管理架构的设计实现,有效帮助用户处理设备数字孪生进程中遇到的场景. 本文分享自华为云社区<KubeEdge:下一代云原生边缘设备管理标准DMI的设计与实现>. 随 ...
- Synology群晖100TB万兆文件云服务器NAS存储池类别 RAID 6 (有数据保护)2021年7月29日 - Copy
Synology群晖100TB万兆文件云服务器NAS存储池类别 RAID 6 (有数据保护)2021年7月29日 - Copy https://www.autoahk.com/archives/367 ...
- 重磅!业界首个云原生批量计算项目Volcano正式晋级为CNCF孵化项目
摘要:4月7日,云原生计算基金会(CNCF)宣布,由华为云捐献的业界首个云原生批量计算项目Volcano正式晋级为CNCF孵化项目. 4月7日,云原生计算基金会(CNCF)宣布,由华为云捐献的业界首个 ...
- 第3届云原生技术实践峰会(CNBPS 2020)重磅开启,“原”力蓄势待发!
CNBPS 2020将在11月19-21日全新启动!作为国内最有影响力的云原生盛会之一,云原生技术实践峰会(CNBPS)至今已举办三届. 在2019年的CNBPS上,灵雀云CTO陈恺喊出"云 ...
- linux下突破10万高并发的nginx性能优化经验
一.这里的优化主要是指对nginx的配置优化,一般来说nginx配置文件中对优化比较有作用的主要有以下几项:1)nginx进程数,建议按照cpu数目来指定,一般跟cpu核数相同或为它的倍数.worke ...
- 突破10万高并发的nginx性能优化经验(含内核参数优化)
写的很好,推荐阅读. 转载:http://www.cnblogs.com/kevingrace/p/6094007.html 在日常的运维工作中,经常会用到nginx服务,也时常会碰到nginx因高并 ...
- 阿里云如何基于标准 K8s 打造边缘计算云原生基础设施
作者 | 黄玉奇(徙远) 阿里巴巴高级技术专家 关注"阿里巴巴云原生"公众号,回复关键词 1219 即可下载本文 PPT 及实操演示视频. 导读:伴随 5G.IoT 的发展,边缘 ...
- 云原生时代, Kubernetes 多集群架构初探
为什么我们需要多集群? 近年来,多集群架构已经成为“老生常谈”.我们喜欢高可用,喜欢异地多可用区,而多集群架构天生就具备了这样的能力.另一方面我们也希望通过多集群混合云来降低成本,利用到不同集群各自的 ...
- 从 lite-apiserver 看 SuperEdge 边缘节点自治
引言 在 SuperEdge 0.2.0版本中,lite-apiserver 进行了重大的架构升级和功能增强.本文将从 lite-apiserver 实现及其与其它 SuperEdge 组件协同的角度 ...
- SuperEdge 云边隧道新特性:从云端SSH运维边缘节点
背景 在边缘集群的场景下边缘节点分布在不同的区域,且边缘节点和云端之间是单向网络,边缘节点可以访问云端节点,云端节点无法直接访问边缘节点,给边缘节点的运维带来很大不便,如果可以从云端SSH登录到边缘节 ...
随机推荐
- centos服务器搭建https
一.环境 OS:CentOS Linux release 8.2.2004 (Core) 硬件:某外网云服务器虚拟机 二.安装命令 1.安装nginx yum install nginx 2.安装签发 ...
- 钉钉OA自定义审批流的创建和使用
前言 大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教. 钉钉作为一款办公软件,审批功能是它的核心功能 ...
- CF85B [Embassy Queue]
Problem 题目简述 有 \(n\) 个人分别在 \(c_i\) 的时刻来,他们都要在 \(k_1\),\(k_2\) 和 \(k_3\) 窗口干不同的事,当有后面一人也排在在同一窗口时,必须等待 ...
- 不可复制的PDF转成双层可复制PDF
有些PDF是通过扫描或者虚拟打印机生成的,这些PDF不可复制里边的内容 市面上的工具一般都是收费或者有水印,所以就萌生了自己搞一个的想法: 使用了以下三个开源库 PdfiumViewer PDF预览及 ...
- Centos7安装msf
文章来自:https://blog.csdn.net/weixin_44268918/article/details/129771330 1. 前言在日常使用中,模拟攻击以及测试的时候都是直接使用本地 ...
- 快速入门:构建您的第一个 .NET Aspire 应用程序
前言 云原生应用程序通常需要连接到各种服务,例如数据库.存储和缓存解决方案.消息传递提供商或其他 Web 服务..NET Aspire 旨在简化这些类型服务之间的连接和配置.在本快速入门中,您将了解如 ...
- JS逆向实战26——某店ua模拟登陆
声明 本文章中所有内容仅供学习交流,抓包内容.敏感网址.数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! 目标 目标网站 aHR0c ...
- Python输入一行字符,分别统计出其中大小写英文字母、空格、数字和其它字符的个数。
import string def SlowSnail(s): up = 0 low = 0 space = 0 digit = 0 others = 0 for c in s: if c.isupp ...
- 🔥🔥Java开发者的Python快速进修指南:迭代器(Iterator)与生成器
这一篇内容可能相对较少,但是迭代器在Java中是有用处的.因此,我想介绍一下Python中迭代器的使用方法.除了写法简单之外,Python的迭代器还有一个最大的不同之处,就是无法直接判断是否还有下一个 ...
- ML.NET 3.0 增强了深度学习和数据处理能力
.NET团队在 2023.11.28 在博客上正式发布了 ML.NET 3.0::https://devblogs.microsoft.com/dotnet/announcing-ml-net-3-0 ...