初识GaussDB(for Cassandra)
摘要:GaussDB(for Cassandra)是一款基于华为自主研发的计算存储分离架构的分布式云数据库服务。
- “local quorum查询某个分区键的条数,每次查询,条数都不一样。”
- “按这个分区键的token修复,直接瞬间修复结束。但是再查,还是每次查询条数不一致。”
- “之前遇到墓碑丢失的问题,单个token查询结果不一致,修复也解决不了”
- …..
不用再为数据不一致苦恼,因为强一致的Cassandra来了,DBA们不用加班改数据了。
GaussDB(for Cassandra)是一款基于华为自主研发的计算存储分离架构的分布式云数据库服务。是一个强一致性的系统,在华为云高性能、高可用、高可靠、高安全、可弹性伸缩的基础上,提供了一键部署、备份恢复、监控报警等服务能力。高度兼容开源Cassandra接口,并提供高读写性能,具有高性价比,适用于IoT、气象、互联网、游戏等领域。
本文将从架构、主要特性、竞争力、应用场景等方面进行介绍。
设计架构:
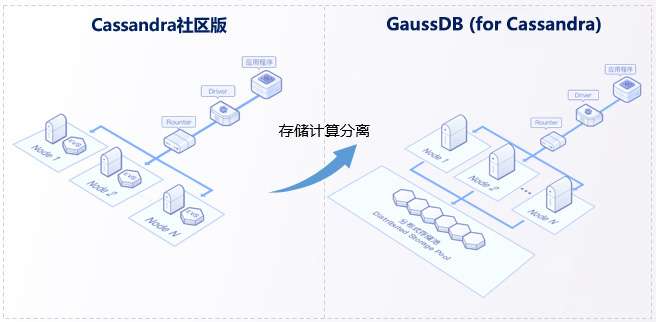
GaussDB(for Cassandra)基于计算存储分离架构,该架构基于华为内部强大且广泛使用的自研分布式存储系统DFV(数据功能虚拟化/Data Function Virtualisation),实现了一套Share Everything的云开源架构,充分发挥了云开源的弹性伸缩、资源共享的优势,高度兼容Cassandra协议,拥有超强写入性能,同时相比社区版具有分钟级计算扩容、秒级存储扩容、数据强一致等优势,性能更强更稳定,数据更可靠,扩容更敏捷,适用于IoT、实时推荐、金融反欺诈检测等场景。
GaussDB(for Cassandra)牛在哪?
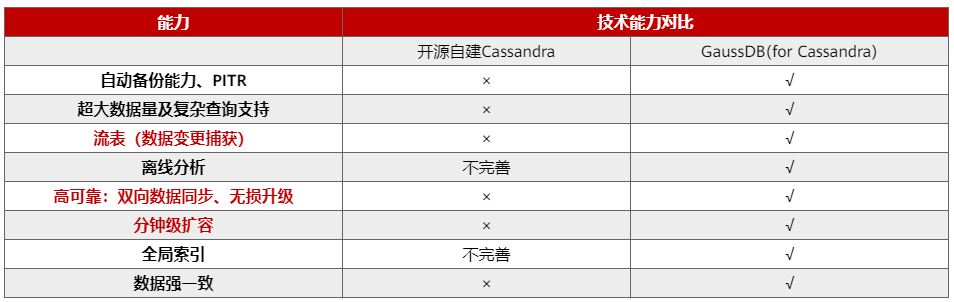
高可靠:数据强一致,提供企业级数据可靠性
开源Cassandra读写数据采用最终一致性,此处用读场景举例:如果读一致性要求为ONE,会立即返回离客户端最近的一份数据副本,那么这意味着第一次读取到的数据可能不是最新的数据。如果读一致性要求为QUORUM(即读取任一数据中心中quorum数量的节点的结果,返回合并后timestamp最新的结果),则内核会自动触发读修复,然后返回给客户端。假如此时有副本所在节点出现坏盘,在gc_graces的周期内没有完成数据修复,部分副本属于坏盘节点的业务数据,业务查询过程中发现数据会概率性不正确。
GaussDB(for Cassandra)采用存算分离架构,数据的副本在DFV存储平台保证,对计算节点来说数据单副本、数据强一致,查询只需要从协调节点直接到数据节点取数据即可完成,规避了数据不一致修复数据造成的人力成本、业务查询过程中发现数据会概率性不正确等问题。另外支持N-1个节点故障容忍,提供10倍以上的故障重构性能和备份恢复性能,保证数据的可靠性。
高扩展:秒级扩容,快速更神速
开源Cassandra采用一致性Hash算法对数据进行分区打散,整个环代表数据从负无穷到正无穷区间。集群中每个节点会有虚拟节点(Token)在环上,虚拟节点的数量可配置。黄圈代表节点1,蓝圈代表要扩容的节点2,2个Token之间组成整个数据的其中一段Range区间,扩容后加入了新的Token,会产生新的Range,这些Range中的一部分会归新节点2管理。那么就需要把数据从节点1迁移到新节点2上去。迁移是通过读取节点1上的数据写入到节点2上,迁移的速度可以通过配置参数调整,整体迁移的时间由数据量与迁移过程中的读写速率有关。
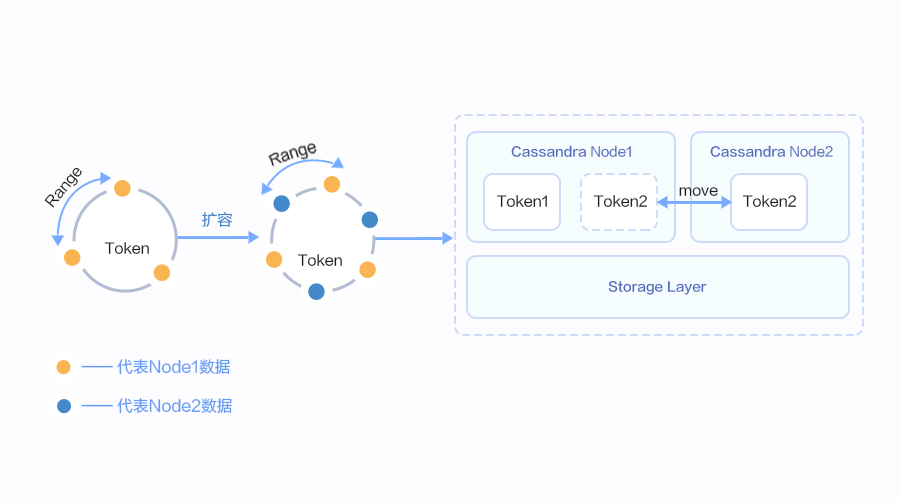
GaussDB(for Cassandra)把多副本策略下沉到共享存储,大幅提升弹性伸缩能力,如图右侧展示,新扩容的节点2只需要重新映射Token2到节点2,就可以完成,无需做数据的读取与写入的搬迁动作,实现分钟级计算扩容,相比开源扩容时间提升几十倍。随着业务的不断增长,Cassandra可以分钟级水平弹性资源扩展。在类似圣诞节等热门节日,提前1天进行弹性扩容,为业务高峰预留资源,业务高峰过后进行缩容,这些对业务无感知。计算节点可以通过文件系统控制集群在DFV中的数据使用量,扩容缩容磁盘时通过重新分配最大使用量,可实现秒级存储扩容,单实例支持海量数据存储。
高性能:超高写入,读性能数倍提升
高安全:构筑多层保护,为数据安全保驾护航
GaussDB(for Cassandra)通过VPC、子网、安全组、DDoS防护以及SSL安全访问等多层安全防护体系,帮助用户抵御网络攻击,让用户上云无忧。
为什么选择GaussDB(for Cassandra)?
适用多种场景
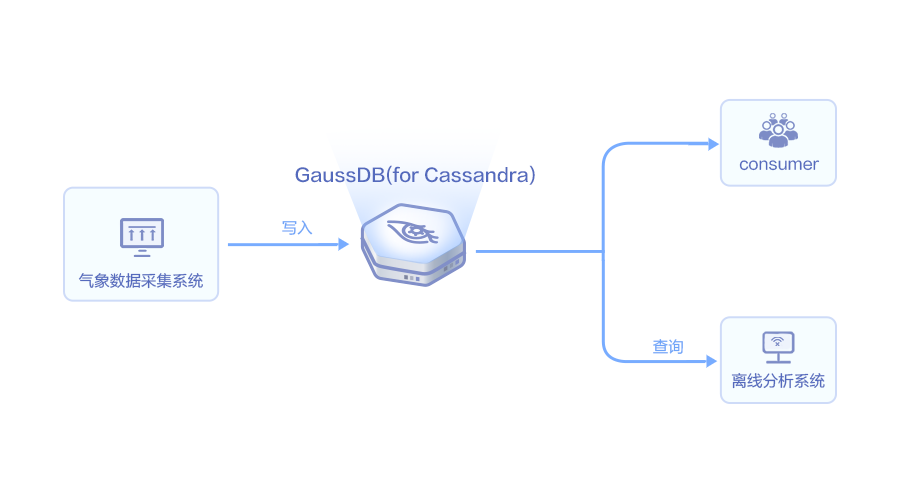
工业制造&气象业
随着科技进度,采集的气象数据指数增长,需要一种系统对地面、高空、海洋、重要天气报、闪电、环境监测等卫星、雷达采集的数据能够高性能写入、查询、在线、离线分析。
- 需要存储对地面、高空、海洋、重要天气报、闪电、环境监测等卫星、雷达等降雨量、湿度、温度等PB级数据量
- 支撑来自各气象采集点数据高并发写入到Cassandra,GaussDB(for Cassandra)集群性能高于自建2~3倍,更适合高并发写入读取
- GaussDB(for Cassandra)数据能够支撑实时在线分析,为气象算法、天气预报做到实时精准分析
- 访问数据库进行离线数据分析,GaussDB(for Cassandra)能将离线分析时效缩短到60%
互联网
GaussDB(for Cassandra)具备高并发写入性能和高可扩展性,保障集群高可用和业务连续稳定性,非常适用于写入规模量较大的互联网大数据场景,如记录大规模的用户行为数据等。
- 存放用户画像数据,能够完美解决特征:数据量大、可以应对数据结构Scheme频繁变更
- 查询性能要求高;比如要买一双鞋,搜索出的鞋子数据会根据用户画像的特征做一定的排序展示,那么要求查询用户特征表的查询性能非常高
- 推荐系统:根据用户最近浏览的数据做分析之后,推荐相关资源给用户
- 点赞系统:点赞计数系统
实时数据分析场景
GaussDB(for Cassandra)群组今天新来了一个成员,或者yutou今天发布一篇新文章,华为云数据库官方自动向该用户发出欢迎邮件。
昵称为yutou的同学今天发布了一组新照片,那么另外一个程序自动向yutou的好友发送通知。
原生不具备的数据变更捕获能力,GaussDB(for Cassandra)具有变更捕获能力,能对数据的变更做实时在线分析,提供秒级的实时推送动作做出相应处理;具有完善的离线分析解决方案,可以将离线分析时效缩短到60%,为商家争取更多的时间做出相应决策。
购买建议
GaussDB(for Cassandra)性能为开源2倍以上,存储空间仅需开源自建1/3,帮助客户节省成本,举例如下:开源自建8u32g * 3节点 数据量:90G(三副本),购买GaussDB(for Cassandra)可选择创建4u16g * 3节点 数据量:30G(DFV存储三副本)
本文分享自华为云社区《华为云数据库GaussDB(for Cassandra)揭秘第一期: 初识GaussDB(for Cassandra)》,原文作者:高斯Cassandra官方 。
初识GaussDB(for Cassandra)的更多相关文章
- 华为云数据库GaussDB(for Cassandra)揭秘第二期:内存异常增长的排查经历
摘要:华为云数据库GaussDB(for Cassandra) 是一款基于计算存储分离架构,兼容Cassandra生态的云原生NoSQL数据库:它依靠共享存储池实现了强一致,保证数据的安全可靠. 本文 ...
- RDS、DDS 和 GaussDB 理不清?看这一篇足够了!
当前,华为云提供的数据库服务主要包括三大类:关系型数据库服务,非关系型数据库服务以及数据库工具服务.如下图所示: 关系型数据库和非关系型数据库均可分为开源和自研两大类.其中,自研数据库统一为Gauss ...
- Mongo DB 初识
前言 2016年伊始,开始研究NoSql.看了couchdb,cloudant,cassandra,redis.却一直没有看过排行榜第一的mongo,实属不该.近期会花时间研究下mongo.本文是初识 ...
- cassandra vs mongo (1)存储引擎
摘要 在MongoDB 初识篇中谈到过Mongo 与 Cassandra的区别,这边再谈谈Mongo与Cassandra的存储引擎差别 概括 存储引擎: 类型 功能 应用 hash 增删改.随机读.顺 ...
- {MySQL数据库初识}一 数据库概述 二 MySQL介绍 三 MySQL的下载安装、简单应用及目录介绍 四 root用户密码设置及忘记密码的解决方案 五 修改字符集编码 六 初识sql语句
MySQL数据库初识 MySQL数据库 本节目录 一 数据库概述 二 MySQL介绍 三 MySQL的下载安装.简单应用及目录介绍 四 root用户密码设置及忘记密码的解决方案 五 修改字符集编码 六 ...
- 时间序列数据库(TSDB)初识与选择
时间序列数据库(TSDB)初识与选择 本文作者由 MageByte 团队的 「借来方向」编写,关注公众号 给你更多硬核技术 背景 这两年互联网行业掀着一股新风,总是听着各种高大上的新名词.大数据.人工 ...
- 时间序列数据库(TSDB)初识与选择(InfluxDB、OpenTSDB、Druid、Elasticsearch对比)
背景 这两年互联网行业掀着一股新风,总是听着各种高大上的新名词.大数据.人工智能.物联网.机器学习.商业智能.智能预警啊等等. 以前的系统,做数据可视化,信息管理,流程控制.现在业务已经不仅仅满足于这 ...
- 升级的华为云“GaussDB”还能战否?
摘要:芯片.操作系统.数据库是现代信息技术领域的三大核心基础,做数据库,不仅需要技术和投入,对华为这种做通讯起家的企业,更需要的是一种并非玩票性质的态度. GaussDB,不仅蕴含着华为对数学和科学的 ...
- Spark—初识spark
Spark--初识spark 一.Spark背景 1)MapReduce局限性 <1>仅支持Map和Reduce两种操作,提供给用户的只有这两种操作 <2>处理效率低效 Map ...
- Cassandra简介
在前面的一篇文章<图形数据库Neo4J简介>中,我们介绍了一种非常流行的图形数据库Neo4J的使用方法.而在本文中,我们将对另外一种类型的NoSQL数据库——Cassandra进行简单地介 ...
随机推荐
- 如何将Python程序打包并保护源代码
导言: 在某些情况下,我们可能希望将Python程序打包成可执行文件,以便用户无法查看程序的源代码.这种需求通常出现在商业软件.数据分析工具或其他需要保护知识产权的场景中.本文将介绍如何使用PyIns ...
- Godot - 通过C#实现类似Unity协程
参考博客Unity 协程原理探究与实现 Godot 3.1.2版本尚不支持C#版本的协程,仿照Unity的形式进行一个协程的尝试 但因为Godot的轮询函数为逐帧的_Process(float del ...
- Java线程安全详解
并发与多线程 blog:https://devonmusa.github.io 1 常见概念 1.1 操作系统线程运行状态 NEW RUNNABLE RUNNING BLOCKED 1.2 Java虚 ...
- 【Java集合】单列集合Collection常用方法详解
嗨~ 今天的你过得还好吗? 路途漫漫终有一归, 幸与不幸都有尽头. 在上篇文章中,我们简单介绍了下Java 集合家族中的成员,那么本篇文章,我们就来看看 Java在单列集合中,为我们提供的一些方法,以 ...
- centOS7 防火墙基本操作
一.防火墙的开启.关闭.禁用命令 (1)设置开机启用防火墙:systemctl enable firewalld.service (2)设置开机禁用防火墙:systemctl disable fire ...
- Python 利用pandas和matplotlib绘制柱状折线图
创建数据可视化图表:柱状图与折线图结合 在数据分析和展示中,经常需要将数据可视化呈现,以便更直观地理解数据背后的趋势和关联关系.本篇文章将介绍如何使用 Python 中的 Pandas 和 Matpl ...
- JavaScript高级程序设计笔记03 语言基础
语言基础 主要基于ES6. 一切都区分大小写.无论变量.函数名还是操作符 标识符 变量名.函数名.属性名.参数名 可由一个或多个字符组成: 第一个必须是字母._或者$: 其余的可以是字母._.$或者数 ...
- 搭建Samba服务器笔记全套
Top 目录 安装 端口与服务管理 其他常用命令 配置 全局配置 共享库配置 用户名密码认证库配置 Samba 登录用户配置 防火墙配置 设定安全的上下文关系 本地系统设置访问读写权限 Pdbedit ...
- Avalonia 实现跨平台的IM即时通讯、语音视频通话(源码,支持信创国产OS,统信、银河麒麟)
在 Avalonia 如火如荼的现在,之前使用CPF实现的简单IM,非常有必要基于 Avalonia 来实现了.Avalonia 在跨平台上的表现非常出色,对信创国产操作系统(像银河麒麟.统信UOS. ...
- 如何通过C++ 给PDF文档添加文字水印
因PDF文档具有较好的稳定性和兼容性,现在越来越多的合同.研究论文.报告等都采用PDF格式.为了进一步保护这些重要文档内容免受未经授权的复制或使用,我们可以添加水印以表明其状态.所有权或用途.针对工作 ...