【Hadoop离线基础总结】Sqoop数据迁移
目录
Sqoop介绍
概述
Sqoop是Apache开源提供过的一款Hadoop和关系数据库服务器之间传送数据的工具。从关系数据库到Hadoop的数据库存储系统(HDFS,HIVE,HBASE等)称为导入,从Hadoop的数据库存储系统到关系数据库称为导出。
Sqoop主要是通过MapReduce的InputFormat和OutputFormat来实现数据的输入和输出,底层执行的MapReduce任务只有Map阶段,没有Reduce阶段,也就是说只是单纯地将数据从一个地方抽取到另一个地方。版本
Sqoop有两个大版本:
Sqoop 1.x 不用安装,解压就能用

Sqoop 2.x 架构发生了变化,引入了一个服务端,可以通过代码提交sqoop的任务

一般情况下用Sqoop 1.x更多一些,只需要将命令写到脚本中,执行脚本即可
Sqoop安装及使用
Sqoop安装
1.下载并解压
下载地址:http://archive.cloudera.com/cdh5/cdh/5/
这里使用的是sqoop1的版本,并且要和hadoop版本相对应,都是5.14.0
将安装包上传到/export/softwares目录中
tar -zxvf sqoop-1.4.6-cdh5.14.0.tar.gz -C ../servers/解压
2.修改配置文件
cd /export/servers/sqoop-1.4.6-cdh5.14.0/conf/
cp sqoop-env-template.sh sqoop-env.shsqoop-env-template.sh是sqoop给的配置模板,所以最好复制一份出来
vim sqoop-env.sh
因为这里只用到Hadoop和Hive,所以只需要配置这两个的路径即可

3.加入额外的依赖包
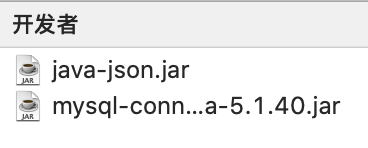
需要在Sqoop的lib目录下加入一个mysql的依赖包,一个java-json的依赖包,否则就会报错
4.验证启动
cd /export/servers/sqoop-1.4.6-cdh5.14.0
bin/sqoop-version

Sqoop数据导入
首先可以用命令行查看帮助
bin/sqoop helpAvailable commands:
可用命令: codegen Generate code to interact with database records
生成与数据库记录交互的代码 create-hive-table Import a table definition into Hive
将表定义导入到Hive中 eval Evaluate a SQL statement and display the results
计算一个SQL语句并显示结果 export Export an HDFS directory to a database table
将HDFS目录导出到数据库表 help List available commands
罗列出可用的命令 import Import a table from a database to HDFS
将一个表从数据库导入到HDFS import-all-tables Import tables from a database to HDFS
将一些表从数据库导入到HDFS import-mainframe Import datasets from a mainframe server to HDFS
从大型机服务器导入数据集到HDFS job Work with saved jobs
用保存的jobs继续工作 list-databases List available databases on a server
列出服务器上可用的数据库 list-tables List available tables in a database
列出数据库中可用的表 merge Merge results of incremental imports
增量导入的合并结果 metastore Run a standalone Sqoop metastore
运行一个独立的Sqoop metastore version Display version information
显示版本信息
1.列出本地主机所有的数据库,可以用
bin/sqoop listdabases --help查看帮助
2.bin/sqoop list-databases --connect jdbc:mysql://192.168.0.106:3306/ --username root --password 自己数据库的密码显示数据库
java.sql.SQLException: null, message from server: "Host ‘192.168.0.30’ is not allowed to connect to this MySQL server"
注意:如果出现这种异常,需要给自己连接的mysql授予远程连接权限
3.bin/sqoop list-tables --connect jdbc:mysql://192.168.0.106:3306/userdb --username root --password 123456显示数据库中的表
4.bin/sqoop import --connect jdbc:mysql://192.168.0.106:3306/userdb --username root --password 123456 --table emp --m 1将mysql数据库userdb中的emp表导入到hdfs中(--table指要选择哪个表,--m指MapTask的个数)

5.bin/sqoop import --connect jdbc:mysql://192.168.0.106:3306/userdb --username root --password 123456 --table emp --delete-target-dir --target-dir /sqoop/emp --m 1将emp表导入到hdfs指定文件夹(--delete-target-dir判断导出目录是否存在,如果存在就删除--target-dir指定导出目录)

6.bin/sqoop import --connect jdbc:mysql://192.168.0.106:3306/userdb --table emp --delete-target-dir --target-dir /sqoop/emp2 --username root --password 123456 --fields-terminated-by '\t' --m 1指定分隔符

导入关系表到Hive已有表中
1.想要将mysql中的表数据直接导入到Hive,必须先将Hive下lib目录中的一个jar包
hive-exec-1.1.0-cdh5.14.0.jar复制到sqoop的lib目录下cp /export/servers/hive-1.1.0-cdh5.14.0/lib/hive-exec-1.1.0-cdh5.14.0.jar /export/servers/sqoop-1.4.6-cdh5.14.0/lib/
2.然后现在hive中创建一个sqooptohive的数据库,并在其中创建一个用来存放数据的表
CREATE DATABASE sqooptohive;
USE sqooptohive;CREATE EXTERNAL TABLE emp_hive(
id INT,
name STRING,
deg STRING,
salary INT,
dept STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001';
3.
bin/sqoop import --connect jdbc:mysql://192.168.0.106:3306/userdb --table emp --delete-target-dir --target-dir /sqoop/emp2 --fields-terminated-by '\001' --username root --password 123456 --hive-import --hive-table sqooptohive.emp_hive --hive-overwrite --m 1从mysql向hive导入表数据(--hive-overwrite表示如果有重名的表,则覆盖掉)

遇到一个报错

原因是因为在/etc/profile中没有配置hive的环境变量,到/etc/profile/下添加两行

配置完成后一定记得source /etc/profile生效
导入关系表到Hive(自动创建Hive表)
bin/sqoop import --connect jdbc:mysql://192.168.0.106:3306/userdb --table emp-conn --username root -password 123456 --hive-import --hive-database sqooptohive --m 1

将关系表子集导入到HDFS中
bin/sqoop import --connect jdbc:mysql://192.168.0.106:3306/userdb --table emp_add --delete-target-dir --target-dir /sqoop/emp_add --username root --password 123456 --where "city='sec-bad'" --m 1

sql语句查找导入到HDFS
bin/sqoop import --connect jdbc:mysql://192.168.0.106:3306/userdb --delect-target-dir --target-dir /sqoop/emp_conn --username root --password 123456 --query 'select phon from emp_conn where 1=1 and $CONDITIONS' --m 1使用sql语句查询首先不能有--table,其次--query后面跟着的sql语句必须用单引号,必须要有where条件,没有筛选条件就用WHERE 1=1,后面必须跟一个$CONDITIONS字符串

两种增量导入方式
实际工作中,很少有需要将整张表的数据导入到Hive或者HDFS,一般只需要导入增量数据。增量导入是仅导入新添加的表中的行的技术。一般情况下,每个数据表都会有三个固定字段:create_time,update_time,is_delete。可以根据创建时间和更新时间来解决增量导入数据的需求
Sqoop也考虑到了这种情况,提供了三个参数来帮助实现增量导入:
--incremental <mode>--check-column <column name>--last value <last check column value>
1.第一种增量方式
需求:导入emp表当中id大于1202的所有数据
bin/sqoop import --connect jdbc:mysql://192.168.0.106:3306/userdb --table emp --target-dir /sqoop/increment --incremental append --check-column id --last-value 1202 --username root --password 123456 --m 1
增量导入的时候,一定不能加参数–delete-target-dir,否则会报错。--incremental有两种mode:append \ lastmodified。--check-column需要的值是用来做增量导入判断的列名(字段名)。--last-value是指定某一个值,用于标记增量导入的位置。

2.第二种增量方式
需求:导入emp表中创建时间在2020.3.7且is_delete=1的数据
bin/sqoop import --connect jdbc:mysql://192.168.0.106/userdb --table emp --target-dir /sqoop/increment2 --incremental append --where "create_time > '2020-3-7 00:00:00' and create_time < '2020-3-7 23:59:59' and is_delete = '1'" --check-column id --username root --password 123456 --m 1
本来想的有了where来查询就可以不用--check-column参数,没想到只要是增量导入就必须要有这个参数


3.思考一下如何解决减量数据的需求?
减量数据的删除是假删除,不是真删除,其实就是改变了数据的状态,数据的更新时间也会同步改变。所以解决减量数据实际上就涉及到了数据的变更问题,只要变更数据,update_time也会发生改变
更新数据的时候,就是要根据create_time和update_time一起来判断,只要符合其中任意一项就将数据导入到Hive或者HDFS上,那么就有可能出现两条id相同,create_time相同的数据,比如id create_time update_time
1 2020-1-3 12:12:12 2020-1-3 12:12:12
1 2020-1-3 12:12:12 2020-1-13 12:12:12
可以用group by id进行分组,将id相同的分到一组,取update_time最新的数据
Sqoop的数据导出
bin/sqoop export --connect jdbc:mysql://192.168.0.106:3306/userdb --table emp_out --export-dir /sqoop/emp --input-fields-terminated-by ',' --username root --password 123456

【Hadoop离线基础总结】Sqoop数据迁移的更多相关文章
- 【Hadoop离线基础总结】Sqoop常用命令及参数
目录 常用命令 常用公用参数 公用参数:数据库连接 公用参数:import 公用参数:export 公用参数:hive 常用命令&参数 从关系表导入--import 导出到关系表--expor ...
- 【Hadoop离线基础总结】Hue的简单介绍和安装部署
目录 Hue的简单介绍 概述 核心功能 安装部署 下载Hue的压缩包并上传到linux解压 编译安装启动 启动Hue进程 hue与其他框架的集成 Hue与Hadoop集成 Hue与Hive集成 Hue ...
- sqoop 数据迁移
sqoop 数据迁移 1 概述 sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具. 导入数据:MySQL,Oracle导入数据到Hadoop的HDFS.HIVE.H ...
- 【Hadoop离线基础总结】impala简单介绍及安装部署
目录 impala的简单介绍 概述 优点 缺点 impala和Hive的关系 impala如何和CDH一起工作 impala的架构及查询计划 impala/hive/spark 对比 impala的安 ...
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 【Hadoop离线基础总结】Hive调优手段
Hive调优手段 最常用的调优手段 Fetch抓取 MapJoin 分区裁剪 列裁剪 控制map个数以及reduce个数 JVM重用 数据压缩 Fetch的抓取 出现原因 Hive中对某些情况的查询不 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- sqoop数据迁移(基于Hadoop和关系数据库服务器之间传送数据)
1:sqoop的概述: (1):sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具.(2):导入数据:MySQL,Oracle导入数据到Hadoop的HDFS.HIV ...
- sqoop数据迁移
3.1 概述 sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具. 导入数据:MySQL,Oracle导入数据到Hadoop的HDFS.HIVE.HBASE等数据存储 ...
随机推荐
- stand up meeting 12-8
根据计划今天项目组成员和travis老师毕然同学进行了最后一次关于design和feature的确认meeting. 项目design和UI的改动较大,feature改动较小,需对UI进行重新整合,对 ...
- stand up meeting 12/23/2015
part 组员 工作 工作耗时/h 明日计划 工作耗时/h UI 冯晓云 基本完成单词本显示页面的设计和实现 4 完善页面切换 ...
- python调用小豆机器人实现自己的机器人!
大家好,人工智能是不是很酷呢? 今天我们用python调用小豆机器人实现自己的机器人(可以结合往期的语音识别更酷哦) 好,废话不多说直接上代码 import requests i=input(&quo ...
- Spring IoC getBean 方法详解
前言 本篇文章主要介绍 Spring IoC 容器 getBean() 方法. 下图是一个大致的流程图: 正文 首先定义一个简单的 POJO,如下: public class User { priva ...
- beanshell 常用的内置变量与函数
官方详细文档:https://github.com/beanshell/beanshell/wiki log:用来记录日志文件 log.info("jmeter"); vars - ...
- django-admin和manage.py用法
官网文档地址:django-admin和manage.py 金句: 所有的天赋,都来自于你对你喜欢的某种事物的模仿与学习,否则你就不会有这种天赋. 开篇话: 我们在Django开发过程中,命令行执行最 ...
- 1-JVM基础
1-JVM基础 java源码文件,通过javac 转换成class文件. 找到.java文件 词法分析器 tokens流 语法分析器 语义分析器 字节码生成器 转成.class文件 装载 根据全限定路 ...
- py安装教程
https://www.runoob.com/w3cnote/pycharm-windows-install.html
- Python快速编程入门,打牢基础必须知道的11个知识点 !
Python被誉为全世界高效的编程语言,同时也被称作是“胶水语言”,那它为何能如此受欢迎,下面我们就来说说Python入门学习的必备11个知识点,也就是它为何能够如此受欢迎的原因. Python 简介 ...
- ubuntu server 18.04 网络配置
从17.10开始放弃在/etc/network/interfaces里固定IP的配置 配置文件是:/etc/netplan/50-cloud-init.yaml .用缩进来表示层级关系 冒号之后要有个 ...