sqoop数据迁移(基于Hadoop和关系数据库服务器之间传送数据)
1:sqoop的概述:
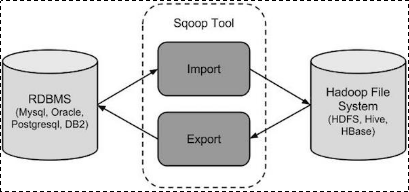
(1):sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具。
(2):导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
(3):导出数据:从Hadoop的文件系统中导出数据到关系数据库(4):工作机制:
将导入或导出命令翻译成mapreduce程序来实现;
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制;(5):Sqoop的原理:
Sqoop的原理其实就是将导入导出命令转化为mapreduce程序来执行,sqoop在接收到命令后,都要生成mapreduce程序;
使用sqoop的代码生成工具可以方便查看到sqoop所生成的java代码,并可在此基础之上进行深入定制开发;
2:sqoop安装:
安装sqoop的前提是已经具备java和hadoop的环境;
第一步:下载并解压,下载以后,上传到自己的虚拟机上面,过程省略,然后解压缩操作:
最新版下载地址:http://ftp.wayne.edu/apache/sqoop/1.4.6/
Sqoop的官方网址:http://sqoop.apache.org/
[root@master package]# tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /home/hadoop/
第二步:修改配置文件:
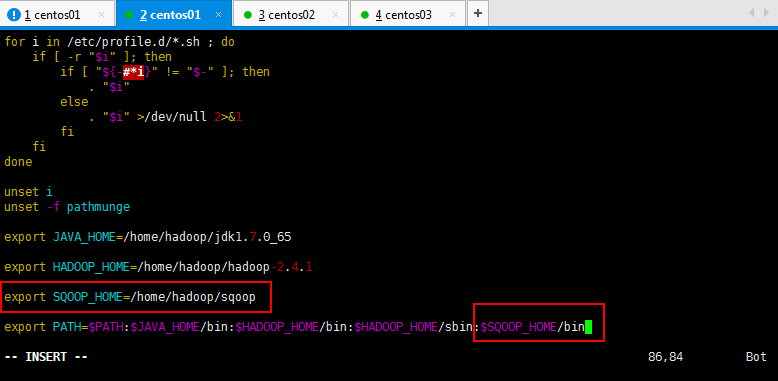
可以修改一下sqoop的名称,因为解压缩的太长了。然后你也可以配置sqoop的环境变量,这样可以方便访问;
[root@master hadoop]# mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
配置Sqoop的环境变量操作,如下所示:
[root@master hadoop]# vim /etc/profile
[root@master hadoop]# source /etc/profile
修改sqoop的配置文件名称如下所示:
[root@master hadoop]# cd $SQOOP_HOME/conf
[root@master conf]# ls
oraoop-site-template.xml sqoop-env-template.sh sqoop-site.xml
sqoop-env-template.cmd sqoop-site-template.xml
[root@master conf]# mv sqoop-env-template.sh sqoop-env.sh
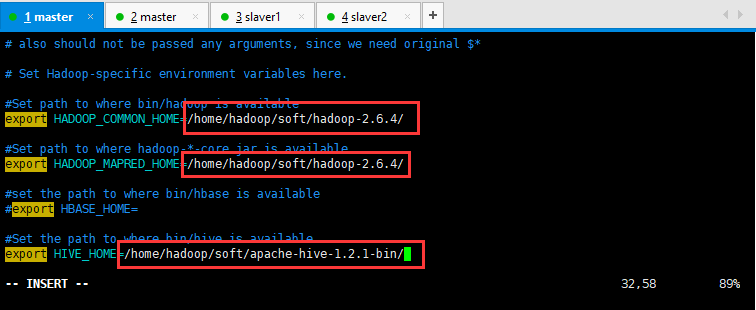
修改sqoop的配置文件如下所示,打开sqoop-env.sh并编辑下面几行(根据需求,可以修改hadoop,hive,hbase的配置文件):
第三步:加入mysql的jdbc驱动包(自己必须提前将mysql的jar包上传到虚拟机上面):
[root@master package]# cp mysql-connector-java-5.1.28.jar $SQOOP_HOME/lib/
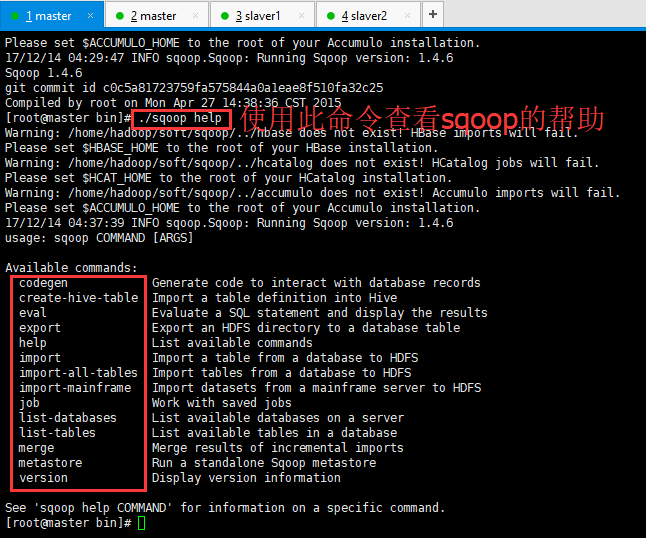
第四步:验证启动,如下所示(由于未配置$HBASE_HOME等等这些的配置,所以发出Warning,不是Error):
[root@master conf]# cd $SQOOP_HOME/bin
[root@master bin]# sqoop-version
Warning: /home/hadoop/soft/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/soft/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/soft/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
Sqoop 1.4.
git commit id c0c5a81723759fa575844a0a1eae8f510fa32c25
Compiled by root on Mon Apr :: CST
到这里,整个Sqoop安装工作完成。下面可以尽情的和Sqoop玩耍了。
3:Sqoop的数据导入:
“导入工具”导入单个表从RDBMS到HDFS。表中的每一行被视为HDFS的记录。所有记录都存储为文本文件的文本数据(或者Avro、sequence文件等二进制数据)
下面的语法用于将数据导入HDFS。
$ sqoop import (generic-args) (import-args)
导入表表数据到HDFS
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
$bin/sqoop import \
--connect jdbc:mysql://localhost:3306/test \ #指定主机名称和数据库
--username root \ #mysql的账号
--password root \ #mysql的密码
--table emp \ #导入的数据表
--m #多少个mapreduce跑,这里是一个mapreduce
或者使用下面的命令进行导入:
[root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --m 1
开始将mysql的数据导入到sqoop的时候出现下面的错误,贴一下,希望可以帮到看到的人:
[root@master sqoop]# bin/sqoop import \
> --connect jdbc:mysql://localhost:3306/test \
> --username root \
> --password 123456 \
> --table emp \
> --m
Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
// :: WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
// :: INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
// :: INFO tool.CodeGenTool: Beginning code generation
// :: INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT
// :: INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT
// :: INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop-2.4.
Note: /tmp/sqoop-root/compile/2df9072831c26203712cd4da683c50d9/emp.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
// :: INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/2df9072831c26203712cd4da683c50d9/emp.jar
// :: WARN manager.MySQLManager: It looks like you are importing from mysql.
// :: WARN manager.MySQLManager: This transfer can be faster! Use the --direct
// :: WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
// :: INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
// :: INFO mapreduce.ImportJobBase: Beginning import of emp
// :: INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
// :: INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
// :: INFO client.RMProxy: Connecting to ResourceManager at master/192.168.3.129:
// :: ERROR tool.ImportTool: Encountered IOException running import job: java.net.ConnectException: Call From master/192.168.3.129 to master: failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:)
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:)
at org.apache.sqoop.mapreduce.ImportJobBase.doSubmitJob(ImportJobBase.java:)
at org.apache.sqoop.mapreduce.ImportJobBase.runJob(ImportJobBase.java:)
at org.apache.sqoop.mapreduce.ImportJobBase.runImport(ImportJobBase.java:)
at org.apache.sqoop.manager.SqlManager.importTable(SqlManager.java:)
at org.apache.sqoop.manager.MySQLManager.importTable(MySQLManager.java:)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:)
at org.apache.sqoop.Sqoop.run(Sqoop.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.main(Sqoop.java:)
Caused by: java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:)
at org.apache.hadoop.ipc.Client$Connection.access$(Client.java:)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
... more [root@master sqoop]# service iptables status
iptables: Firewall is not running.
[root@master sqoop]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.3.129 master
192.168.3.130 slaver1
192.168.3.131 slaver2
192.168.3.132 slaver3
192.168.3.133 slaver4
192.168.3.134 slaver5
192.168.3.135 slaver6
192.168.3.136 slaver7 [root@master sqoop]# jps
Jps
[root@master sqoop]# sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --m 1
Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
// :: WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
// :: INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
// :: INFO tool.CodeGenTool: Beginning code generation
// :: INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT
// :: INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT
// :: INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop-2.4.
Note: /tmp/sqoop-root/compile/3748127f0b101bfa0fd892963bea25dd/emp.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
// :: INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/3748127f0b101bfa0fd892963bea25dd/emp.jar
// :: WARN manager.MySQLManager: It looks like you are importing from mysql.
// :: WARN manager.MySQLManager: This transfer can be faster! Use the --direct
// :: WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
// :: INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
// :: INFO mapreduce.ImportJobBase: Beginning import of emp
// :: INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
// :: INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
// :: INFO client.RMProxy: Connecting to ResourceManager at master/192.168.3.129:
// :: ERROR tool.ImportTool: Encountered IOException running import job: java.net.ConnectException: Call From master/192.168.3.129 to master: failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:)
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:)
at org.apache.sqoop.mapreduce.ImportJobBase.doSubmitJob(ImportJobBase.java:)
at org.apache.sqoop.mapreduce.ImportJobBase.runJob(ImportJobBase.java:)
at org.apache.sqoop.mapreduce.ImportJobBase.runImport(ImportJobBase.java:)
at org.apache.sqoop.manager.SqlManager.importTable(SqlManager.java:)
at org.apache.sqoop.manager.MySQLManager.importTable(MySQLManager.java:)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:)
at org.apache.sqoop.Sqoop.run(Sqoop.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.main(Sqoop.java:)
Caused by: java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:)
at org.apache.hadoop.ipc.Client$Connection.access$(Client.java:)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:)
at org.apache.hadoop.ipc.Client.call(Client.java:)
... more [root@master sqoop]#
出现上面错误的原因是因为你的集群没有开,start-dfs.sh和start-yarn.sh开启你的集群即可:
正常运行如下所示:
[root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --m 1
Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
// :: WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
// :: INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
// :: INFO tool.CodeGenTool: Beginning code generation
// :: INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT
// :: INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT
// :: INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop-2.4.
Note: /tmp/sqoop-root/compile/60ee51250c5c6b5f5598392e068ce2d0/emp.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
// :: INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/60ee51250c5c6b5f5598392e068ce2d0/emp.jar
// :: WARN manager.MySQLManager: It looks like you are importing from mysql.
// :: WARN manager.MySQLManager: This transfer can be faster! Use the --direct
// :: WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
// :: INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
// :: INFO mapreduce.ImportJobBase: Beginning import of emp
// :: INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
// :: INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
// :: INFO client.RMProxy: Connecting to ResourceManager at master/192.168.3.129:
// :: INFO db.DBInputFormat: Using read commited transaction isolation
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513306156301_0001
// :: INFO impl.YarnClientImpl: Submitted application application_1513306156301_0001
// :: INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1513306156301_0001/
// :: INFO mapreduce.Job: Running job: job_1513306156301_0001
// :: INFO mapreduce.Job: Job job_1513306156301_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1513306156301_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Other local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total vcore-seconds taken by all map tasks=
Total megabyte-seconds taken by all map tasks=
Map-Reduce Framework
Map input records=
Map output records=
Input split bytes=
Spilled Records=
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO mapreduce.ImportJobBase: Transferred bytes in 90.4093 seconds (0.5088 bytes/sec)
// :: INFO mapreduce.ImportJobBase: Retrieved records.
[root@master sqoop]#
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据,如下所示:
总之,遇到很多问题,当我我没有指定导入到的目录的时候,我去hdfs查看的时候竟然没有我导入的mysql数据表。郁闷。先记录一下。如果查看成功的话,数据表的数据和字段之间用逗号(,)表示。
4:导入关系表到HIVE:
bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --hive-import --m 1
5:导入到HDFS指定目录:
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。
以下是指定目标目录选项的Sqoop导入命令的语法。
--target-dir <new or exist directory in HDFS>
下面的命令是用来导入emp表数据到'/sqoop'目录。
bin/sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password \
--target-dir /sqoop \
--table emp \
--m [root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --target-dir /sqoop --table emp --m 1
如果你指定的目录存在的话,将会报如下的错误:
// :: ERROR tool.ImportTool: Encountered IOException running import job: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://master:9000/wordcount already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:)
at org.apache.sqoop.mapreduce.ImportJobBase.doSubmitJob(ImportJobBase.java:)
at org.apache.sqoop.mapreduce.ImportJobBase.runJob(ImportJobBase.java:)
at org.apache.sqoop.mapreduce.ImportJobBase.runImport(ImportJobBase.java:)
at org.apache.sqoop.manager.SqlManager.importTable(SqlManager.java:)
at org.apache.sqoop.manager.MySQLManager.importTable(MySQLManager.java:)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:)
at org.apache.sqoop.Sqoop.run(Sqoop.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.main(Sqoop.java:)
导入到指定的目录,如果成功的话,会显示出你的mysql数据表的数据,字段之间以逗号分隔。
使用如下的命令是用来验证 /sqoop 目录中 emp数据表导入的数据形式。它会用逗号,分隔emp数据表的数据和字段。
[root@master sqoop]# hadoop fs -cat /sqoop/part-m-
,zhangsan,,yi
,lisi,,er
,wangwu,,san
[root@master sqoop]#
6:导入表数据子集:
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
where子句的语法如下。
--where <condition>
#下面的命令用来导入emp表数据的子集。子集查询检索员工ID和地址,居住城市为:city;
#方式一
bin/sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password \
--where "city ='zhengzhou'" \
--target-dir /sqoop02 \
--table emp \
--m #方式二
[root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --where "city ='zhengzhou'" --target-dir /sqoop02 --table emp --m 1
7:sqoop的按需导入:
可以如上面演示使用命令用来验证数据从emp数据表导入/sqoop03 目录
它用逗号'\t'分隔 emp数据表数据和字段。
#sqoop按需导入
#方式一
bin/sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \ #mysql的账号
--password \ #mysql的密码
--target-dir /sqoop03 \ #指定存放的目录
--query 'select id,name,age,dept from emp WHERE id>0 and $CONDITIONS' \ #灵活的mysql语句,且必须加and $CONDITIONS'
--split-by id \ #按照那个字段做切片,id做切片
--fields-terminated-by '\t' \ #导入到我的文件系统中为'\t',默认为逗号。
--m #方式二
[root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --target-dir /sqoop03 --query 'select id,name,age,dept from emp WHERE id>0 and $CONDITIONS' --split-by id --fields-terminated-by '\t' --m 1
7:sqoop的增量导入,增量导入是仅导入新添加的表中的行的技术:
它需要添加‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入。
下面的语法用于Sqoop导入命令增量选项。
--incremental <mode>
--check-column <column name>
--last value <last check column value>
下面的命令用于在EMP表执行增量导入。 #方式一
bin/sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password \
--table emp \
--m \
--incremental append \ #追加导入
--check-column id \ #根据id字段来判断从哪里开始导入
--last-value 6 #根据id字段,从7开始导入 #方式二
[root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --m 1 --incremental append --check-column id --last-value 6
8:Sqoop的数据导出:
将数据从HDFS导出到RDBMS数据库,导出前,目标表必须存在于目标数据库中。默认操作是从将文件中的数据使用INSERT语句插入到表中,更新模式下,是生成UPDATE语句更新表数据;
以下是export命令语法。
$ sqoop export (generic-args) (export-args)
具体操作如下所示:
首先,数据是在HDFS 中"/sqoop"目录的part-m-00000文件中。
第一步:首先需要手动创建mysql中的目标表:
[root@master hadoop]# mysql -uroot -p123456 mysql> show databases; mysql> use test; mysql> CREATE TABLE `emp` (
-> `id` int() NOT NULL AUTO_INCREMENT,
-> `name` varchar() DEFAULT NULL,
-> `age` int() DEFAULT NULL,
-> `dept` varchar() DEFAULT NULL,
-> PRIMARY KEY (`id`)
-> ) ENGINE=MyISAM AUTO_INCREMENT= DEFAULT CHARSET=latin1;
如果不事先创建好数据表会报如下错误:
// :: ERROR manager.SqlManager: Error executing statement: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'test.emp' doesn't exist
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'test.emp' doesn't exist
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:)
at com.mysql.jdbc.Util.getInstance(Util.java:)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:)
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:)
at com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:)
at org.apache.sqoop.manager.SqlManager.execute(SqlManager.java:)
at org.apache.sqoop.manager.SqlManager.execute(SqlManager.java:)
at org.apache.sqoop.manager.SqlManager.getColumnInfoForRawQuery(SqlManager.java:)
at org.apache.sqoop.manager.SqlManager.getColumnTypesForRawQuery(SqlManager.java:)
at org.apache.sqoop.manager.SqlManager.getColumnTypes(SqlManager.java:)
at org.apache.sqoop.manager.ConnManager.getColumnTypes(ConnManager.java:)
at org.apache.sqoop.orm.ClassWriter.getColumnTypes(ClassWriter.java:)
at org.apache.sqoop.orm.ClassWriter.generate(ClassWriter.java:)
at org.apache.sqoop.tool.CodeGenTool.generateORM(CodeGenTool.java:)
at org.apache.sqoop.tool.ExportTool.exportTable(ExportTool.java:)
at org.apache.sqoop.tool.ExportTool.run(ExportTool.java:)
at org.apache.sqoop.Sqoop.run(Sqoop.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.main(Sqoop.java:)
第二步:然后执行导出命令(如果localhost不好使,可以换成ip试一下):
#方式一
bin/sqoop export \
--connect jdbc:mysql://192.168.3.129:3306/test \
--username root \
--password \
--table emp \ #导入的数据表
--export-dir /sqoop/ #导出的目录 #方式二
bin/sqoop export --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --export-dir /sqoop
第三步:验证表mysql命令行(或者使用图形化工具查看是否有数据导入):
mysql>select * from emp;
如果给定的数据存储成功,那么可以找到符合的数据。
待续......
sqoop数据迁移(基于Hadoop和关系数据库服务器之间传送数据)的更多相关文章
- 【大数据】基于Hadoop的HBase的安装(转)
https://note.youdao.com/share/?id=c27485373a08517f7ad2e7ec901cd8d5&type=note#/ 安装前先确认HBse和Hadoop ...
- rsync进行不同服务器之间的数据同步
2台服务器上都要安装rsync,sudo yum install rsync. 把远程的数据备份到本机: rsync -rP --rsh=ssh root@IP:/data/tmp /data/tmp ...
- 【Hadoop离线基础总结】Sqoop数据迁移
目录 Sqoop介绍 概述 版本 Sqoop安装及使用 Sqoop安装 Sqoop数据导入 导入关系表到Hive已有表中 导入关系表到Hive(自动创建Hive表) 将关系表子集导入到HDFS中 sq ...
- sqoop 数据迁移
sqoop 数据迁移 1 概述 sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具. 导入数据:MySQL,Oracle导入数据到Hadoop的HDFS.HIVE.H ...
- sqoop关系型数据迁移原理以及map端内存为何不会爆掉窥探
序:map客户端使用jdbc向数据库发送查询语句,将会拿到所有数据到map的客户端,安装jdbc的原理,数据全部缓存在内存中,但是内存没有出现爆掉情况,这是因为1.3以后,对jdbc进行了优化,改进j ...
- sqoop数据迁移
3.1 概述 sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具. 导入数据:MySQL,Oracle导入数据到Hadoop的HDFS.HIVE.HBASE等数据存储 ...
- sqoop1.4.6数据迁移
sqoop介绍 sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具. 导入数据:MySQL,Oracle导入数据到Hadoop的HDFS.HIVE.HBASE等数据存 ...
- 13_sqoop数据迁移概述
3. sqoop数据迁移 3.1 概述 sqoop是apache旗下一款“Hadoop体系和关系数据库服务器之间传送数据”的工具. 导入数据:MySQL,Oracle导入数据到Hadoop的HDFS. ...
- Sqoop -- 用于Hadoop与关系数据库间数据导入导出工作的工具
Sqoop是一款开源的工具,主要用于在Hadoop相关存储(HDFS.Hive.HBase)与传统关系数据库(MySql.Oracle等)间进行数据传递工作.Sqoop最早是作为Hadoop的一个第三 ...
随机推荐
- vue项目的骨架及常用组件介绍
vue项目基础结构 一个vue的项目,我觉得最小的子集其实就是{vue,vue-router,component},vue作为基础库,为我们提供双向绑定等功能.vue-router连接不同的" ...
- HDFS对象存储--Ozone架构设计
前言 如今做云存储的公司非常多,举2个比較典型的AWS的S3和阿里云.他们都提供了一个叫做对象存储的服务,就是目标数据是从Object中进行读写的,然后能够通过key来获取相应的Object,就是所谓 ...
- RecyclerView.Adapter优化了吗?
昨天写了一篇「还在用ListView?」讲的内容是RecyclerView的使用技巧以及一些经常使用的开源库.有朋友反馈"我已经在用recyclerview了",那么怎样让它更好用 ...
- JSP具体篇——response对象
response对象 response对象用于响应client请求,向客户输出信息. 他封装了JSP产生的响应,并发送到client以响应client请求. 1.重定向网页 使用response对象的 ...
- Android Library projetcts cannot be exported.
记一次比較无语的犯错,前几天我在紧急打包一个apk的时候.遇到了这样一个异常:Android Library projetcts cannot be exported. 异常提示截图例如以下: wat ...
- vue的组件和生命周期
Vue里组件的通信 通信:传参.控制.数据共享(A操控B做一个事件) 模式:父子组件间.非父子组件 父组件可以将一条数据传递给子组件,这条数据可以是动态的,父组件的数据更改的时候,子组件接收的也会变化 ...
- java读取请求中body数据
java读取请求中body数据 /** * 获取request中body数据 * * @author lifq * * 2017年2月24日 下午2:29:06 * @throws IOExcepti ...
- java集合框架(Collections Framework)
*/ .hljs { display: block; overflow-x: auto; padding: 0.5em; color: #333; background: #f8f8f8; } .hl ...
- 【python】字符串格式化
- iOS 通知的变化ios9-10,新功能展示
二.新功能展示 1 使用 /iOS通知新功能玩法 2. 全面 iOS10里的通知与推送详情 一.变化 四.Notification(通知) 自从Notification被引入之后,苹果就不断的 ...