第7章 PCA与梯度上升法


主成分分析法:主要作用是降维

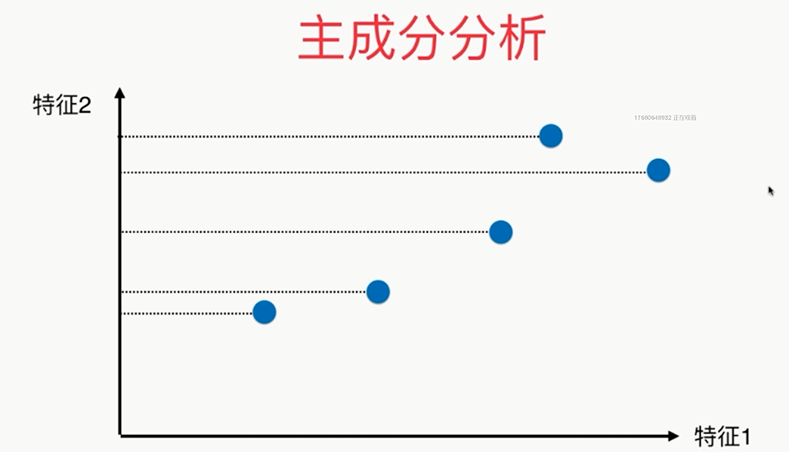

疑似右侧比较好?
第三种降维方式:
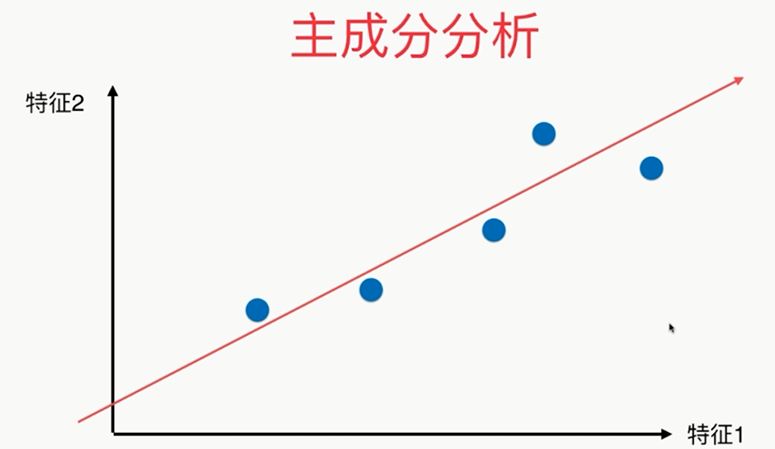
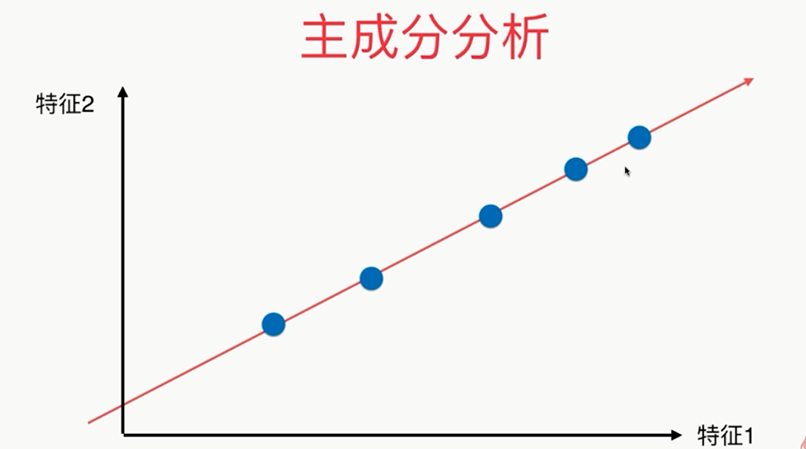
问题:?????

方差:描述样本整体分布的疏密的指标,方差越大,样本之间越稀疏;越小,越密集

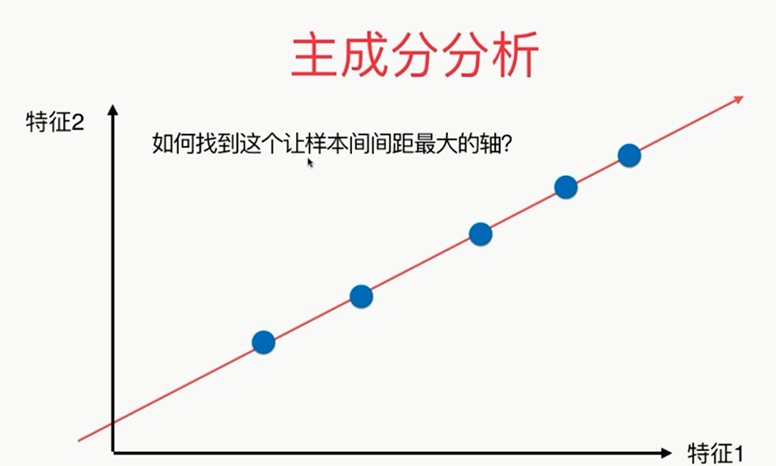
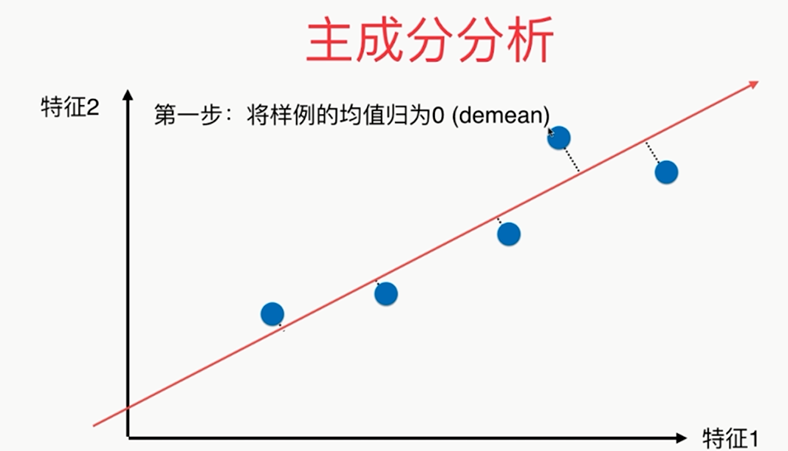
第一步:
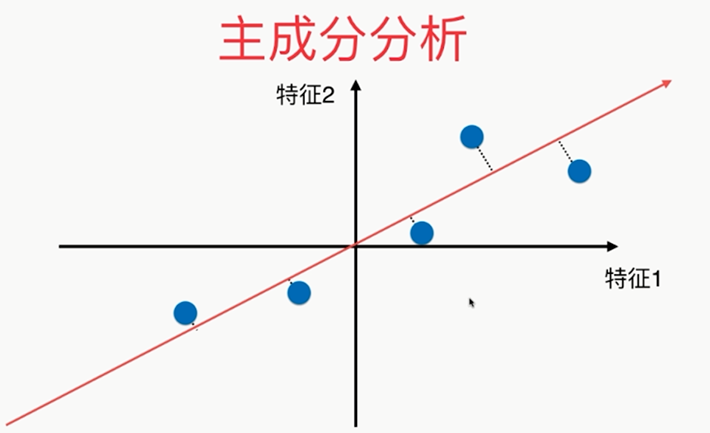
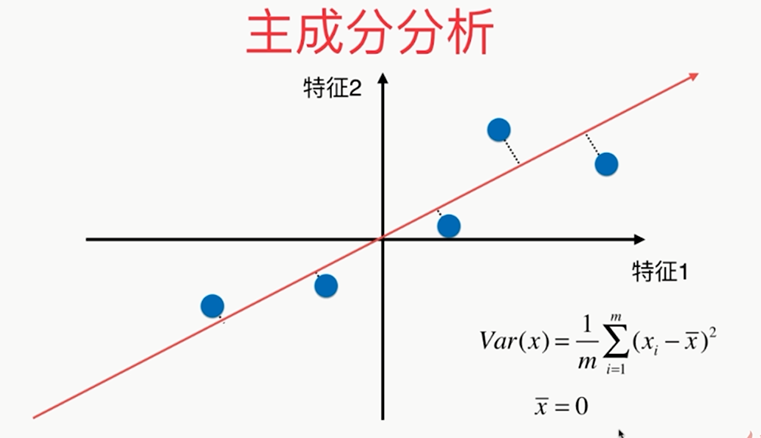

总结:



问题:????怎样使其最大
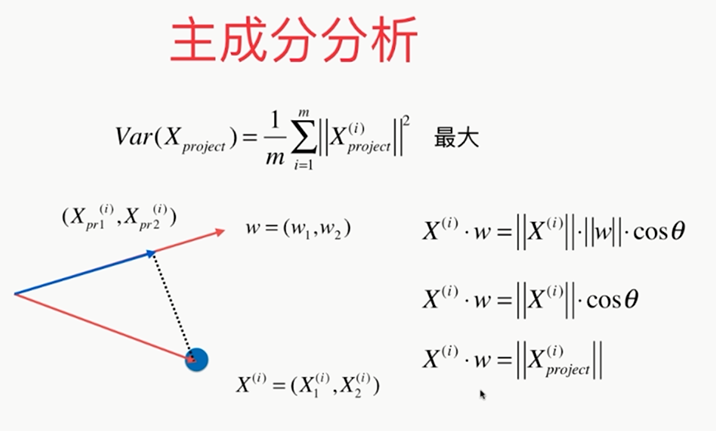
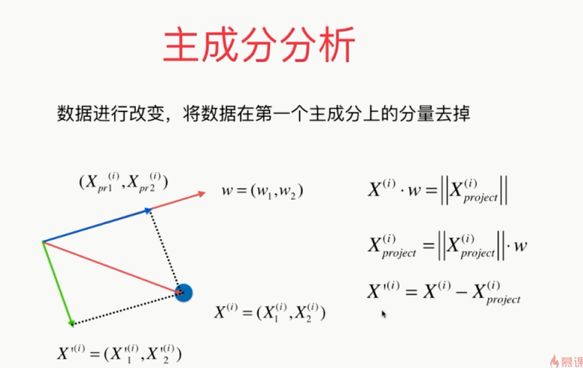
变换后:
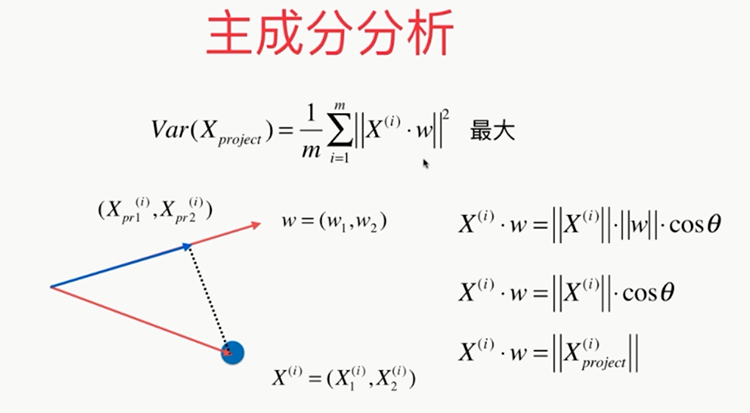


最后的问题:????
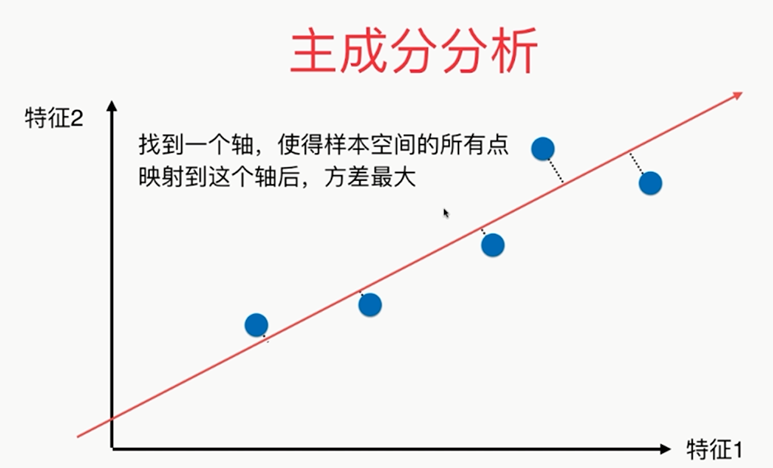
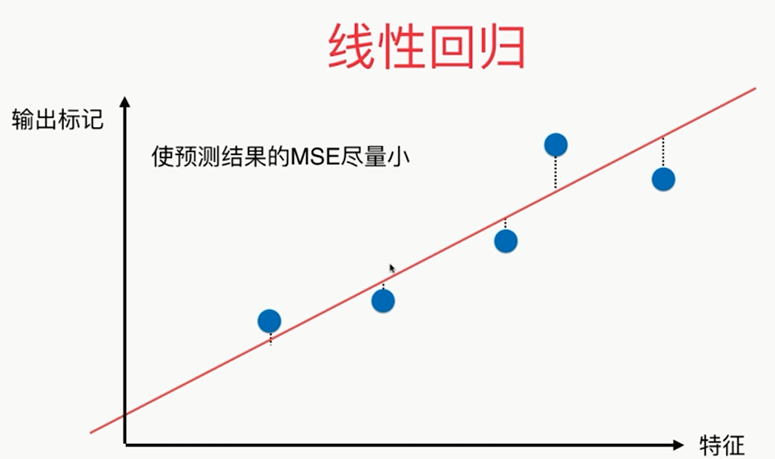
注意区别于线性回归
使用梯度上升法解决PCA问题:









import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets digits = datasets.load_digits() # 手写识别数据
X = digits.data
y = digits.target from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
# 使用K近邻
from sklearn.neighbors import KNeighborsClassifier
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train,y_train)
a1=knn_clf.score(X_test,y_test)
# print(a1)
# 使用PCA
from sklearn.decomposition import PCA
pca=PCA(n_components=2)
pca.fit(X_train)
X_train_reduction=pca.transform(X_train)
X_test_reduction=pca.transform(X_test)
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)
a2=knn_clf.score(X_test_reduction,y_test)
# print(a2) # print(pca.explained_variance_ratio_)
pca=PCA(n_components=X_train.shape[1])
pca.fit(X_train)
# print(pca.explained_variance_ratio_) plt.plot([i for i in range(X_train.shape[1])],
[np.sum(pca.explained_variance_ratio_[:i+1]) for i in range(X_train.shape[1])])
# plt.show() pca1=PCA(0.95) # 能解释95%以上的方差
pca1.fit(X_train)
print(pca.n_components_) from sklearn.decomposition import PCA
pca=PCA(0.95)
pca.fit(X_train)
X_train_reduction=pca.transform(X_train)
X_test_reduction=pca.transform(X_test)
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)
a3=knn_clf.score(X_test_reduction,y_test)
print(a3) pca=PCA(n_components=2)
pca.fit(X)
X_reduction=pca.transform(X)
for i in range(10):
plt.scatter(X_reduction[y==i,0],X_reduction[y==i,1],alpha=0.8)
plt.show()
scikit-learn中的PCA
第7章 PCA与梯度上升法的更多相关文章
- 机器学习(七) PCA与梯度上升法 (上)
一.什么是PCA 主成分分析 Principal Component Analysis 一个非监督学的学习算法 主要用于数据的降维 通过降维,可以发现更便于人类理解的特征 其他应用:可视化:去噪 第一 ...
- 机器学习(4)——PCA与梯度上升法
主成分分析(Principal Component Analysis) 一个非监督的机器学习算法 主要用于数据的降维 通过降维,可以发现更便于人类理解的特征 其他应用:可视化.去噪 通过映射,我们可以 ...
- 4.pca与梯度上升法
(一)什么是pca pca,也就是主成分分析法(principal component analysis),主要是用来对数据集进行降维处理.举个最简单的例子,我要根据姓名.年龄.头发的长度.身高.体重 ...
- 机器学习(七) PCA与梯度上升法 (下)
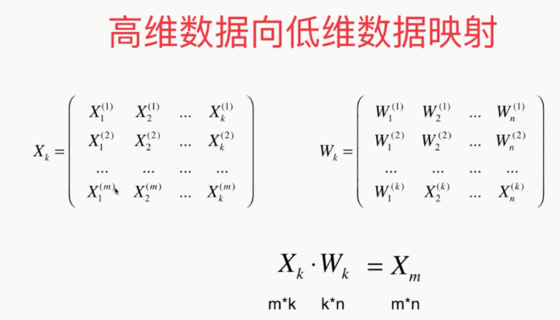
五.高维数据映射为低维数据 换一个坐标轴.在新的坐标轴里面表示原来高维的数据. 低维 反向 映射为高维数据 PCA.py import numpy as np class PCA: def __ini ...
- 机器学习:PCA(使用梯度上升法求解数据主成分 Ⅰ )
一.目标函数的梯度求解公式 PCA 降维的具体实现,转变为: 方案:梯度上升法优化效用函数,找到其最大值时对应的主成分 w : 效用函数中,向量 w 是变量: 在最终要求取降维后的数据集时,w 是参数 ...
- 《机器学习实战》学习笔记——第13章 PCA
1. 降维技术 1.1 降维的必要性 1. 多重共线性--预测变量之间相互关联.多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯.2. 高维空间本身具有稀疏性.一维正态分布有68%的值落于正负 ...
- 第四章 PCA降维
目录 1. PCA降维 PCA:主成分分析(Principe conponents Analysis) 2. 维度的概念 一般认为时间的一维,而空间的维度,众说纷纭.霍金认为空间是10维的. 3. 为 ...
- Python3入门机器学习经典算法与应用
<Python3入门机器学习经典算法与应用> 章节第1章 欢迎来到 Python3 玩转机器学习1-1 什么是机器学习1-2 课程涵盖的内容和理念1-3 课程所使用的主要技术栈第2章 机器 ...
- Python3入门机器学习经典算法与应用☝☝☝
Python3入门机器学习经典算法与应用 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 使用新版python3语言和流行的scikit-learn框架,算法与 ...
随机推荐
- 数论--HDU 1495 非常可乐
Description 大家一定觉的运动以后喝可乐是一件很惬意的事情,但是seeyou却不这么认为.因为每次当seeyou买了可乐以后,阿牛就要求和seeyou一起分享这一瓶可乐,而且一定要喝的和se ...
- 数学--数论--HDU 2674 沙雕题
WhereIsHeroFrom: Zty, what are you doing ? Zty: I want to calculate N!.. WhereIsHeroFrom: So easy! H ...
- 《C程序设计语言》 练习1-22
问题描述 练习1-22 编写一个程序,把较长的输入行“折”成短一些的两行或者多行,折行的位置在输入行的第N列之前的最后一个非空格之后.要保持程序能够智能地处理输入行很长以及在制定的列前没有空格或者制表 ...
- 模块_os模块
import os print(os.getcwd()) # 获取当前工作目录 print(os.listdir()) # 列表列出当前目录下的目录名和文件名 os.mkdir("tempd ...
- Web的Cookies,Session,Application
Cookies:客户端(浏览器)存储信息的地方 Session:服务器的内置对象,可以在这里存储信息.按用户区分,每个客户端有一个特定的SessionID.存储时间按分钟计. Application: ...
- Selenium + Python + Chrome 自动化测试 环境搭建
一.下载Python 相关的教程很多,此处不详细记录了,下面是官网下载地址: https://www.python.org/downloads/ 我使用的python版本为 Python 3.6.1 ...
- PAT数列排序
19考研结束了 .. 还有11天PAT甲 题目链接:http://lx.lanqiao.cn/problem.page?gpid=T52 题目大意:训练排序 解题思路: 方法一: 直接用C++里的so ...
- STL库中神奇函数nth_element
用法:nth_element(数组名,数组名+第k小元素,数组名+元素个数) 这个函数主要用来将数组元素中第k小的整数排出来并在数组中就位,随时调用. 例如: ]={,,,,},k ; cin> ...
- SpringMvc 你该知道如何在HandlerExceptionResolver中获取Model
在项目开发中,我们通常通过参数的形式注入Model对象,如: @RequestMapping("/demo") public String demo(Model model) { ...
- 2018-06-19 Javascript 基础2
js变量类型测试:typeof()->五种 (number,string,boolean,object,undefined): instanceof->检查某个对象是否是某个构造器产生的 ...