WAV格式解析
WAV为微软公司(Microsoft)开发的一种声音文件格式,它符合RIFF(Resource Interchange File Format)文件规范,用于保存Windows平台的音频信息资源,被Windows平台及其应用程序所广泛支持,
该格式也支持MSADPCM,CCITT A LAW等多种压缩运算法,支持多种音频数字,取样频率和声道,标准格式化的WAV文件和CD格式一样,也是44.1K的取样频率,16位量化数字,因此在声音文件质量和CD相差无几。
WAVE文件为了与RIFF保持一致,数据采用“chunk”来存储。
因此,如果想要在WAVE文件中补充一些新的信息,只需要在在新chunk中添加信息,而不需要改变整个文件。这也是设计IFF最初的目的。
对于一个基本的WAVE文件而言,最少包含以下三种Chunk:
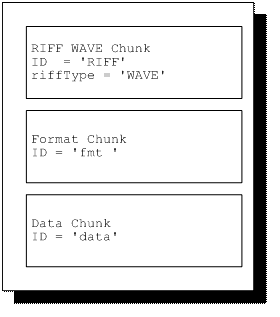
以上三个chunk 顺序固定,对于其它的chunk,顺序没有严格的限制。
具体格式如下:
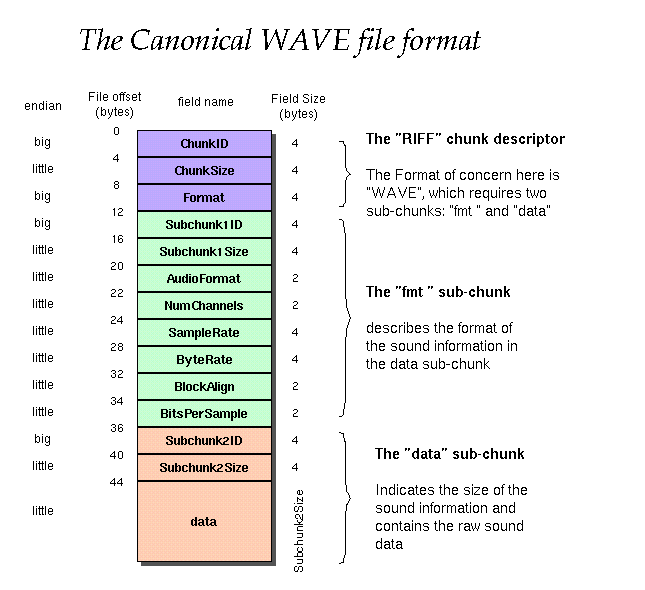
然而,所有基于压缩编码的WAV文件必须含有fact块。此外所有其它块都是可选的。fmt,Data及fact块均为RIFF块的子块。WAV文件的文件格式类型标识符为“WAVE”。

各个chunk中字段的意义如下:
RIFF chunk
| ID | big-endian | FOURCC 值为'R' 'I' 'F' 'F' |
| Size | little-endian | data字段中数据的字节数 |
| Data | big-endian | 包含其它的chunk |
Format chunk
| ID | big-endian | FOURCC 值为 'f' 'm' 't' ' ' | |
| Size | little-endian | 数据字段包含数据的大小。如无扩展块,则值为16;有扩展块,则值为 16 + 2字节扩展块长度 + 扩展块长度或者值为18(只有扩展块的长度为2字节,值为0) | |
| Data | little-endian | format_tag | 2字节,表示音频数据的格式。如值为1,表示使用PCM格式。 |
| little-endian | channels | 2字节,声道数。值为1则为单声道,为2则是双声道。 | |
| little-endian | samples_per_sec | 采样率,主要有22.05KHz,44.1kHz和48KHz。 | |
| little-endian | bytes_per sec | 音频的码率,每秒播放的字节数。samples_per_sec * channels * bits_per_sample / 8,可以估算出使用缓冲区的大小 | |
| little-endian | block_align | 数据块对齐单位,一次采样的大小,值为声道数 * 量化位数 / 8,在播放时需要一次处理多个该值大小的字节数据。 | |
| little-endian | bits_per_sample | 音频sample的量化位数,有16位,24位和32位等。 | |
| cbSize | 扩展区的长度 | ||
| 扩展格式块内容 | 22字节,具体介绍请看下面 | ||
其中 format_tag 可以取如下值:
| 格式代码 | 格式名称 | fmt 块长度 | fact 块 |
| 1(0x0001) | PCM/非压缩格式 | 16 | |
| 2(0x0002 | Microsoft ADPCM | 18 | √ |
| 3(0x0003) | IEEE float | 18 | √ |
| 6(0x0006) | ITU G.711 a-law | 18 | √ |
| 7(0x0007) | ITU G.711 μ-law | 18 | √ |
| 49(0x0031) | GSM 6.10 | 20 | √ |
| 64(0x0040) | ITU G.721 ADPCM | √ | |
| 65,534(0xFFFE) | 见子格式块中的编码格式 | 40 |
其中的扩展格式块:
当WAV文件使用的不是PCM编码方式是,就需要扩展格式块,它是在基本的Format chunk又添加一段数据。
该数据的前两个字节,表示的扩展块的长度。紧接其后的是扩展的数据区,含有扩展的格式信息,其具体的长度取决于压缩编码的类型。
当某种编码方式(如 ITU G.711 a-law)使扩展区的长度为0,扩展区的长度字段还必须保留,只是其值设置为0。
扩展区的各个字节的含义如下:
| Size | 扩展区的数据长度 ,可以为0或22 |
| valid_bits_per_sample | 有效的采样位数,最大值为采样字节数 * 8。可以使用更灵活的量化位数,通常音频sample的量化位数为8的倍数,但是使用了WAVE_FORMAT_EXTENSIBLE时,量化的位数有扩展区中的valid bits per sample来描述,可以小于Format chunk中制定的bits per sample |
| channle mask | 4字节,声道掩码 |
| sub format | 16字节,GUID,include the data format code,数据格式码。 |
在Format chunk中的format_tag设置为0xFFFE时,表示使用扩展区中的sub_format来决定音频的数据的编码方式。在以下几种情况下必须要使用WAVE_FORMAT_EXTENSIBLE
- PCM数据的量化位数大于16
- 音频的采样声道大于2
- 实际的量化位数不是8的倍数
- 存储顺序和播放顺序不一致,需要指定从声道顺序到声卡播放顺序的映射情况。
Fact chunk (可选)
| ID | FOURCC 值为 'f' 'a' 'c' 't' |
| Size | 数据域的长度,4(最小值为4) |
| Data | 每个声道的采样总数 4字节 |
Data chunk
| ID | FOURCC 值为'd' 'a' 't' 'a' |
| Size | 数据域的长度 |
| Data |
具体的音频数据存放在这里 |
Data块中存放的是音频的采样数据。每个sample按照采样的时间顺序写入,对于使用多个字节的sample,使用小端模式存放(低位字节存放在低地址,高位字节存放在高地址)。对于多声道的sample采用交叉存放的方式。例如:立体双声道的sample存储顺序为:声道1的第一个sample,声道2的第一个sample;声道1的第二个sample,声道2的第二个sample;依次类推....。对于PCM数据,有以下两种的存储方式:
- 单声道,量化位数为8,使用偏移二进制码
- 除上面之外的,使用补码方式存储。
描述WAVE文件的基本单元是“Sample”,一个Sample代表采样一次得到的数据。因此如果用44KHz采样,将在一秒中得到44000个Sample。
每个Sample可以用8位、24位,甚至32位表示(位数没有限制,只要是8的整数倍即可),位数越高,音频质量越好。
注意:8位代表无符号的数值,而16位或16位以上代表有符号的数值
每秒数据大小(字节)=采样率 * 声道数 * sample比特数 / 8
WAV格式解析的更多相关文章
- WAV格式文件无损合并&帧头数据体解析(python)(原创)
一,百度百科 WAV为微软公司(Microsoft)开发的一种声音文件格式,它符合RIFF(Resource Interchange File Format)文件规范,用于保存Windows平台的音频 ...
- (原创)speex与wav格式音频文件的互相转换(二)
之前写过了如何将speex与wav格式的音频互相转换,如果没有看过的请看一下连接 http://www.cnblogs.com/dongweiq/p/4515186.html 虽然自己实现了相关的压缩 ...
- PJSIP-PJMEDIA【使用pjmedia 播放wav格式的音乐】
应宝哥建议以及更好的交流学习,这篇开始使用中文,英语就先放一放吧! 要使用PJSIP中的PJMEDIA首先我们需要搭建好它所需要的环境. [环境搭建与调试] 1 在 工具 加入pjmedia所需要的包 ...
- 基于Linux ALSA音频驱动的wav文件解析及播放程序 2012
本设计思路:先打开一个普通wav音频文件,从定义的文件头前面的44个字节中,取出文件头的定义消息,置于一个文件头的结构体中.然后打开alsa音频驱动,从文件头结构体取出采样精度,声道数,采样频率三个重 ...
- 将PCM格式存储成WAV格式文件
将PCM格式存储成WAV格式文件 WAV比PCM多44个字节(在文件头位置多) 摘自:https://blog.csdn.net/u012173922/article/details/78849076 ...
- plist文件、NSUserDefault 对文件进行存储的类、json格式解析
========================== 文件操作 ========================== Δ一 .plist文件 .plist文件是一个属性字典数组的一个文件: .plis ...
- MySQL binlog的格式解析
我搜集到了一些资料,对理解代码比较有帮助. 在头文件中binlog_event.h中,有描述 class Log_event_header class Log_event_footer 参见[Myst ...
- JSON格式解析和libjson使用简介(关于cjson的使用示例)
JSON格式解析和libjson使用简介 在阅读本文之前,请先阅读下<Rss Reader实例开发之系统设计>一文. Rss Reader实例开发中,进行网络数据交换时主要使用到了两种数据 ...
- Android中使用speex将PCM录音格式转Wav格式
Android中使用speex将PCM录音格式转Wav格式 2013-09-17 17:24:00| 分类: android | 标签:android speex wav |举报|字号 订阅 ...
随机推荐
- Ubuntu16 nginx 配置 Let's Encrypt 免费ssl
每篇一句 Some of us get dipped in flat, some in satin, some in gloss. But every once in a while you find ...
- Spring的核心api和两种实例化方式
一.spring的核心api Spring有如下的核心api BeanFactory :这是一个工厂,用于生成任意bean.采取延迟加载,第一次getBean时才会初始化Bean Applicatio ...
- 后端——框架——容器框架——spring_core——《官网》阅读笔记——初篇
1.知识体系 spring-core的知识点大概分为以下几个部分 IOC容器 Bean的配置,XML方式和注解方式 Bean的管理,bean的生命周期,bean的作用域等等 与Bean相关联的接口和对 ...
- VS2017中使用C++语言编写delay函数实现延迟
秒级别的延时 //定义函数 void delay(int sec){ time_t start_time, cur_time; // 变量声明 time(&start_time); do { ...
- Apache POI详解
一 :简介 开发中经常会设计到excel的处理,如导出Excel,导入Excel到数据库中,操作Excel目前有两个框架,一个是apache 的poi, 另一个是 Java Excel Apache ...
- 使用Kubespray在ubuntu上自动部署K8s1.9.0集群
Kubespray 是 Kubernetes incubator 中的项目,目标是提供 Production Ready Kubernetes 部署方案,该项目基础是通过 Ansible Playbo ...
- 【JavaScript】关于eval("("+result+")")的认识
起因是做现项目时,参用很久之前一个项目的代码,少了一行eval("("+result+")"):控制台始终运行不出结果 大致意思是:eval方法是将json字符 ...
- 常见排序的Java实现
插入排序 1.原理:在有序数组中从后向前扫描找到要插入元素的位置,将元素插入进去. 2.步骤:插入元素和依次和前一个元素进行比较,若比前一个元素小就交换位置,否则结束循环. 3.代码: package ...
- float元素上-margin的用法
css标准,float元素上的负margin表示把下面的元素向对应方向移动,并且覆盖上一个元素(这里是指html中元素的声明顺序). 标准情况下我们用float 时候是这样的. -margin通俗点说 ...
- 修复GRUB引导故障!
故障原因:MBR中的GRUB引导程序遭到破坏,grub.conf文件丢失,引导配置有误 故障现象:系统引导停滞,显示“grub>”提示符 解决思路:若无MBR备份,进入急救模式,重新安装grub ...