Python 爬取 北京市政府首都之窗信件列表-[数据处理]
日期:2020.01.24
博客期:132
星期五
【代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明】
//博客总体说明
1、准备工作
2、爬取工作
3、数据处理(本期博客)
4、信息展示
好了今天是除夕,先给大家说句吉利话,“祝大家打代码代代顺利,码码成功”!我因为回家了,今天没做太多东西... ...呼~
登录虚拟机,启动hadoop和hive,准备做数据处理部分!
//建数据库的语句
create table govdata(
kind string,
asker string,
responser string,
asktime string,
responsetime string,
title string,
questionSupport int,
responseSupport string,
responseUnsupport string,
questiontext string,
responsetext string
) row format delimited
fields terminated by '\t';
处理如下:

之后通过文件导入数据(以"\t"为分隔符进行数据导入):
//从路径为"/data/edu3/govdata"的文件导入数据
load data local inpath '/data/edu3/govdata' into table govdata;
处理如下:

之后对应需求部分的处理正在进行
下面是对数据库的测试:

之后使用文件导入方式导入到mysql (因为是以\t为分隔符所以对应以下代码)
LOAD DATA INFILE
'E:\\课件\\3-2\\大数据\\大三寒假作业\\2020-01-23\\datas.txt'
INTO TABLE govdata
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
导入以后分别使用sql语句去建立三个需求的表:
CREATE table kinddata
As
(
select
kind as kind,
count(1) as num
from govdata
group by kind
order by num desc
); CREATE table yeardata
AS
(
select
SUBSTRING(asktime,1,4) as dt,
count(*) as num
from govdata
group by dt
)
; CREATE table responserdata
AS
(
select
gd.responser as responser,
count(*) as num
from govdata gd
group by responser
order by num desc
);
得到数据表(可以提供制作网页的数据):

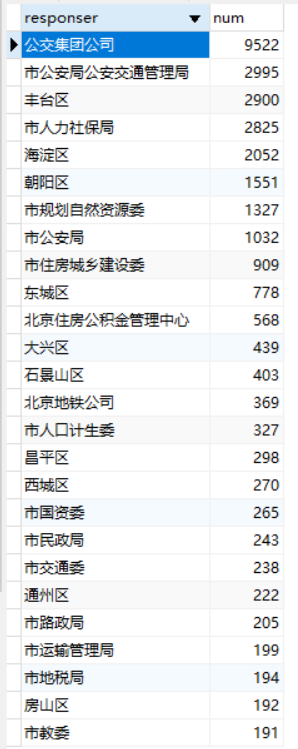

这分别对应的是每年的信件量,回答方对应的信件数,和不同类型的信件数
Python 爬取 北京市政府首都之窗信件列表-[数据处理]的更多相关文章
- Python 爬取 北京市政府首都之窗信件列表-[Scrapy框架](2020年寒假小目标04)
日期:2020.01.22 博客期:130 星期三 [代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明] //博客总体说明 1.准备工作(本期博客) 2.爬取工作 3.数据处理 4.信息展 ...
- Python 爬取 北京市政府首都之窗信件列表-[后续补充]
日期:2020.01.23 博客期:131 星期四 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] //博客总体说明 1.准备工作 2.爬取工作(本期博客) 3.数据处理 ...
- Python 爬取 北京市政府首都之窗信件列表-[信息展示]
日期:2020.01.25 博客期:133 星期六 [代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明] //博客总体说明 1.准备工作 2.爬取工作 3.数据处理 4.信息展示(本期博客 ...
- python爬取北京政府信件信息01
python爬取,找到目标地址,开始研究网页代码格式,于是就开始根据之前学的知识进行爬取,出师不利啊,一开始爬取就出现了个问题,这是之前是没有遇到过的,明明地址没问题,就是显示网页不存在,于是就在百度 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
随机推荐
- SPRING MICROSERVICES IN ACTION
What is microservice 背景 在微服务的概念成型之前,绝大部分基于WEB的应用都是使用单体的风格来进行构建的.在单体架构中,应用程序作为单个可部署的软件制品交付,所有的UI(用户接口 ...
- drat笔记
安装dart https://www.dartcn.com/install http://www.cndartlang.com/920.html 所有执行的方法都在main里面. main() {} ...
- 【PAT甲级】1081 Rational Sum (20 分)
题意: 输入一个正整数N(<=100),接着输入N个由两个整数和一个/组成的分数.输出N个分数的和. AAAAAccepted code: #define HAVE_STRUCT_TIMESPE ...
- Windows配置本地Hadoop运行环境
很多人喜欢用Windows本地开发Hadoop程序,这里是一个在Windows下配置Hadoop的教程. 首先去官网下载hadoop,这里需要下载一个工具winutils,这个工具是编译hadoop用 ...
- web渗透(转)
某天比较无聊,听一个朋友推荐httpscan这款工具,于是就下载下来试试. 首先对某学校网段开始进行测试. 1 python httpscan.py **.**.**.0/24 测试时发现有个比较 ...
- Windows 查看并关闭占用指定端口的程序
windows关闭端口的小工具: 链接:https://pan.baidu.com/s/1ZGL4cdSluy0lbi3tDERUvA 提取码:spxy 查看指定端口的使用情况 netstat -an ...
- 9000端口号被上一个ip地址占用,需要reboot才可以恢复正常ip端口问题
比如查看端口# lsof -i:9000 本机ip已经修改为192.168.0.50,而经过# lsof -i:9000查看到,端口是这样的,192.168.0.88:9000,显示的还是上一个ip的 ...
- keytool生成keystore
在密钥库中生成本地数字证书:需要提供身份.加密算法.有效期等信息:keytool指令如下,产生的本地证书后缀名为:*.keystore keytool -genkeypair -keyalg RSA ...
- 吴裕雄--天生自然Numpy库学习笔记:NumPy 字符串函数
这些函数在字符数组类(numpy.char)中定义. add() 对两个数组的逐个字符串元素进行连接 multiply() 返回按元素多重连接后的字符串 center() 居中字符串 capitali ...
- 单播反向路径转发uRPF
uRPF将数据包的源地址和存储在转发信息库(FIB)中的信息进行对照,以判定数据包的合法性.FIB是Cisco CEF技术中的一张表,包含从路由表中复制过来的转发信息,可以将其视为路由表的镜像,FIB ...