以KNN为例用sklearn进行数据分析和预测
准备
相关的库
相关的库包括:
- numpy
- pandas
- sklearn
带入代码如下:
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassfier as KNN
数据准备
数据是sklearn的乳腺癌数据。
from skleanr.datasets import load_breast_cancer
data=load_breast_caner()
data主要分为两部分:data和target,把这两部分,设置变量导入DataFrame中可查看基本形状。
X = data.data
y = data.target
sklearn的数据其形式比较固定,data的主要属性有:
data。数据,即变量的值,多行多列target。目标,即因变量的值,一般是一行DESCR。描述,可打印出,描述变量、目标features_names。X的列名target_names。Y的列名filename。数据文件所在位置(一般在\lib\site-packages\sklearn\datasets\data\目录下)
分数据集和测试集:
from sklearn.model_selection import train_test_split
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X, y, test_size=0.3)
注意:
- 0.3是指30%数据作为测试。每次运行不同,可通过
random_state控制 - 返回的结果固定,不可错
建立模型
clf = KNN(n_neighbors = 5)
clf=clf.fit(Xtrain,Ytrain)
clf就是训练好的模型,可调用接口查看进行预测和评分。常用是predict、score和kneighbors。三者分别用来预测、评分、求最近邻。
在选择训练集和测试集的时候,可能会存在以下问题。
- 选择测试集和训练集每次都是不同的,因此每次模型的效果都不同。
- 选择测试集和训练集有时会极大影响模型。——特别是当数据是有顺序的时候。
因此需要交叉验证,找到最好的参数,再次训练模型。
K折交叉验证
K折交叉验证的方法:
cvresult=CVS(clf,X,y,cv=5)
CVS的第一个参数是训练过的模型,参数cv是折数。
cvresult.mean() # 取得均值
cvresult.var() #取得方差
可利用方差,绘制出学习曲线:
score =[]
var_=[]
krange=range(1,21)
for i in krange:
clf=KNN(n_neighbors=i)
cvresult=CVS(clf,X,y,cv=5)
score.append(cvresult.mean())
var_.append(cvresult.var())
plt.plot(krange,score,color='k')
plt.plot(krange,np.array(score)+np.array(var_)*2,c='red',linestyle='--')
plt.plot(krange,np.array(score)-np.array(var_)*2,c='red',linestyle='--')
bestindex=score.index(max(score))
print(bestindex+1)
print(score[bestindex])
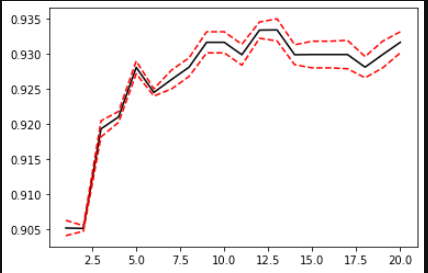
常用交叉验证
- K折。特别在回归模型,若数据有顺序,结果会很糟糕
- stratifiedKfold。常用
- shuffleSplit。常用
- GroupKFold。
但是如果把数据分为:训练数据、测试数据。训练数据又分出来一部分验证数据,那么真正用于训练的数据就更小了。
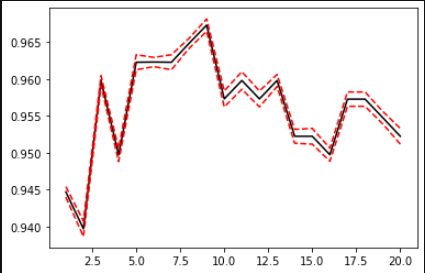
归一化
KNN是距离类的模型,因此需要归一化。也就是把数据减去最差值,处以极差:
\]
归一化要分训练集和测试集之后。(因为归一化时候用到的极值,很可能就是测试集的数据,这样事先就把数据透露给模型了)
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X_,y,
test_size=0.3,
random_state=420)
MMS=nms().fit(Xtrain) #MMS中,有Xtrain的min,和极差
Xtest_=MMS.transform(Xtest)
Xtrain_=MMS.transform(Xtrain) #分别对训练集、测试集进行归一化
这样再运行学习曲线的代码,得到的结果就要好一些:
以KNN为例用sklearn进行数据分析和预测的更多相关文章
- KNN算法基本原理与sklearn实现
''' KNN 近邻算法,有监督学习算法 用于分类和回归 思路: 1.在样本空间中查找 k 个最相似或者距离最近的样本 2.根据这 k 个最相似的样本对未知样本进行分类 步骤: 1.对数据进行预处理 ...
- 使用sklearn进行数据挖掘-房价预测(4)—数据预处理
在使用机器算法之前,我们先把数据做下预处理,先把特征和标签拆分出来 housing = strat_train_set.drop("median_house_value",axis ...
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- 使用sklearn进行数据挖掘-房价预测(1)
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(2)—划分测试集
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(5)—训练模型
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- C++并发与多线程学习笔记--单例设计模式、共享数据分析
设计模式 共享数据分析 call_once 设计模式 开发程序中的一些特殊写法,这些写法和常规写法不一样,但是程序灵活,维护起来方便,别人接管起来,阅读代码的时候都会很痛苦.用设计模式理念写出来的代码 ...
- python数据分析Titanic_Survived预测
import pandas as pd import matplotlib.pyplot as plt # matplotlib画图注释中文需要设置from matplotlib.font_manag ...
随机推荐
- webpack知识点散记
1.今天学习webpack ,刚开头就碰到了钉子,因为现在都是4+的版本,用以前的老命令不好使,如下例子及解决办法 不好用: webpack3的 打包文件 webpack a.js b.j ...
- springboot启动项目报错:ERROR:o.s.b.d.LoggingFailureAnalysisReporter解决办法
原因是引入了spring security的依赖,将spring security对应的依赖删除即可. 具体可参照: https://blog.csdn.net/qq_37887131/article ...
- Linux每日一练20200221
- windows driver 创建线程
VOID ThreadStart(_In_ PVOID StartContext) { PWCHAR str = (PWCHAR)StartContext; MySleep(10);//延时10ms ...
- Spring AOP 基本的使用
1. jar包 2.全局配置文件 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns=&q ...
- POJ_3122 经典二分题
Pie Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8594 Accepted: 3124 Special Jud ...
- hiho1482出勤记录II(string类字符串中查找字符串,库函数的应用)
string类中有很多好用的函数,这里介绍在string类字符串中查找字符串的函数. string类字符串中查找字符串一般可以用: 1.s.find(s1)函数,从前往后查找与目标字符串匹配的第一个位 ...
- 吴裕雄--天生自然JAVA SPRING框架开发学习笔记:Spring目录结构和基础JAR包介绍
可以通过网址 http://repo.spring.io/simple/libs-release-local/org/springframework/spring/ 下载名称为 springframe ...
- 2020PHP面试-网络篇
一.网络协议分层 OSI七层: 物理层.数据链路层.网络层.传输层.会话层.表示层.应用层. TCP/IP四(五)层 : 物理层(主要是光电信号的传输). 数据链路层(MAC地址.以太网协议).网络层 ...
- missing KW_END at ')' near '<EOF>'
case when 没写 end