Cassandra存储time series类型数据时的内部数据结构?
CREATE TABLE temperature (
weatherstation_id text,
event_time timestamp,
temperature text,
PRIMARY KEY (weatherstation_id,event_time));
INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES ('1234ABCD','2013-04-03 07:01:00','72F');
INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES ('1234ABCD','2013-04-03 07:02:00','73F');
INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES ('1234ABCD','2013-04-03 07:03:00','73F');
INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES ('1234ABCD','2013-04-03 07:04:00','74F');
weatherstation_id, event_time, temprature
'1234ABCD','2013-04-03 07:01:00','72F'
'1234ABCD','2013-04-03 07:02:00','73F'
'1234ABCD','2013-04-03 07:03:00','73F'
'1234ABCD','2013-04-03 07:04:00','74F'

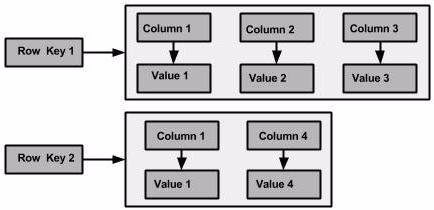
CREATE TABLE users (
user_name varchar PRIMARY KEY,
password varchar,
gender varchar,
session_token varchar,
state varchar,
birth_year bigint
);
CREATE TABLE emp (
empID int,
deptID int,
first_name varchar,
last_name varchar,
PRIMARY KEY (empID, deptID)
);
CREATE TABLE Cats (
block_id uuid,
breed text,
color text,
short_hair boolean,
PRIMARY KEY ((block_id, breed), color, short_hair)
);
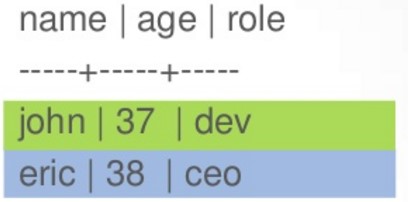
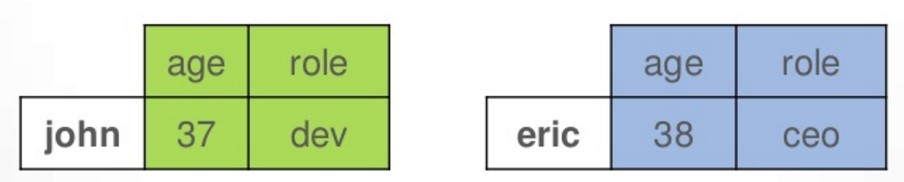
CreateTable employees(
name text PRIMARY KEY,
age int,
role text
);
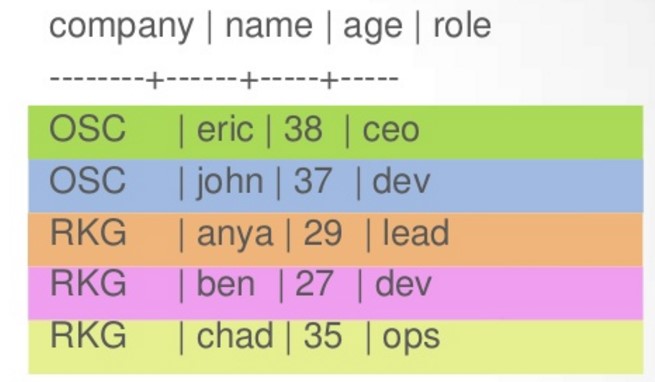
CreateTable employees(
company text,
name text,
age int,
role text,
PRIMARY KEY(company, name)
);

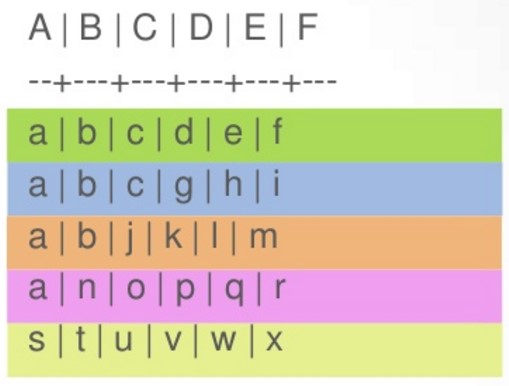
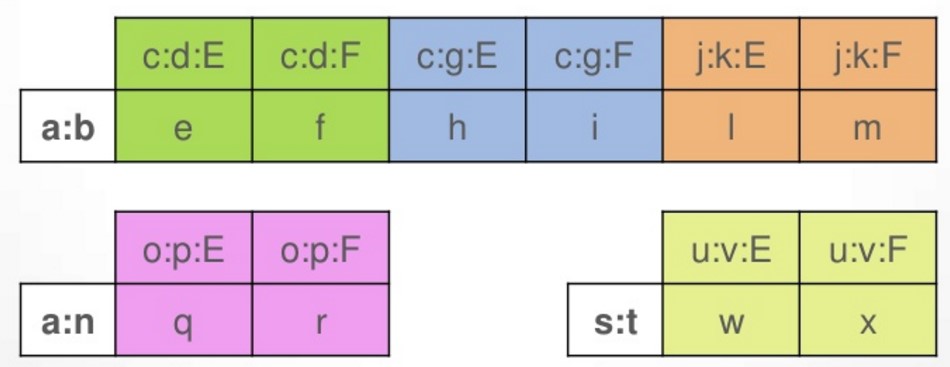
CreateTable example(
A text,
B text,
C text,
D text,
E text,
F text,
PrimaryKey((A,B),C,D)
)
weatherstation_id, event_time, temprature
'1234ABCD','2013-04-03 07:01:00','72F'
'1234ABCD','2013-04-03 07:02:00','73F'
'1234ABCD','2013-04-03 07:03:00','73F'
'1234ABCD','2013-04-03 07:04:00','74F'

Cassandra存储time series类型数据时的内部数据结构?的更多相关文章
- asp.net mvc视图中使用entitySet类型数据时提示出错
asp.net mvc5视图中使用entitySet类型数据时提示以下错误 检查了一下引用,发现已经引用了System.Data.Linq了,可是还是一直提示出错, 后来发现还需要在Views文件夹下 ...
- 关于.net 保存 decimal类型数据到SQLServer2012数据库时自动取整的问题
公司同事问我有没有遇到过decimal类型数据入库时,会自动取整的问题(比如12.3入库后值是12,12.8入库后值是13,入库后自动四舍五入自动取整): 之前就遇到过从数据去decimal类型数据时 ...
- .NET向WebService传值为decimal、double、int、DateTime等非string类型属性时,服务器端接收不到数据的问题
最近在做CRM项目时,使用C#调用SAP PI发布的WebService服务时遇到的问题: 向WebService传值为decimal.double.int.DateTime等非string类型数据时 ...
- 【Redis】redis各类型数据存储分析
一.简介和应用 Redis是一个由ANSI C语言编写,性能优秀.支持网络.可持久化的K-K内存数据库,并提供多种语言的API.它常用的类型主要是 String.List.Hash.Set.ZSet ...
- C#中的double类型数据向SQL sqerver 存储与读取问题
1.存储 由于double类型在SQLsever中并没有对应数据,试过对应float.real类型,发现小数位都存在四舍五入的现象,目前我使用的是decimal类型,用此类型时个人觉得小数位数应该比自 ...
- Java操作Redis存储对象类型数据
背景描述 关于JAVA去操作Redis时,如何存储一个对象的数据,大家是非常关心的问题,虽然官方提供了存储String,List,Set等等类型,但并不满足我们现在实际应用.存储一个对象是是 ...
- mysql那些事(2)时间类型数据如何存储
几乎每次数据库建模的时候,都会遇到时间类型数据存储的问题. mysql存储时间通常选择这四种类型:datetime.timestamp.int和bigint四种方式,到底使用什么类型,需要看具体的业务 ...
- Redis数据结构(一)-Redis的数据存储及String类型的实现
1 引言 Redis作为基于内存的非关系型的K-V数据库.因读写响应快速.原子操作.提供了多种数据类型String.List.Hash.Set.Sorted Set.在项目中有着广泛的使用,今天我们来 ...
- InnerException 消息是“反序列化对象 属于类型 *** 时出现错误。读取 XML 数据时,超出最大字符串内容长度配额 (8192)。(注意细节)
WEB站点在调用我们WCF服务的时候,只要传入的参数过长,就报如下错误: 格式化程序尝试对消息反序列化时引发异常: 尝试对参数 http://tempuri.org/ 进行反序列化时出错: formD ...
随机推荐
- iOS企业版APP分发上线流程和注意事项
0.准备 1]$299/year的企业级开发账号. 2]制作分发证书和描述文件,并下载安装到本机. 3]Xcode编译通过,真机测试通过的源码. 1.打包前配置 1]Xcode 打开项目,common ...
- Java模拟新浪微博登陆抓取数据
前言: 兄弟们来了来了,最近有人在问如何模拟新浪微博登陆抓取数据,我听后默默地抽了一口老烟,暗暗的对自己说,老汉是时候该你出场了,所以今天有时间就整理整理,浅谈一二. 首先: 要想登陆新浪微博需要 ...
- vue生命周期的介绍
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- mysqldump 使用说明
mysqldump 使用说明 A Database Backup Program mysqldump客户端是一款实用的mysql备份程序,可以对数据库的定义及数据表内容,进行备份生成相应的SQL语句. ...
- linux下php调试工具xdebug安装配置
xdebug简介 Xdebug是php的一款调试工具,是基于zend的一个扩展,可以用来跟踪,调试和分析PHP程序的运行状况.如变量,函数调试,性能监测,代码覆盖率等 xdebug安装 1.下载xde ...
- devexpress显示缓冲滚动条与实现类似QQ消息推送效果
1.一般在项目中处理大数据,或者查询大量数据时,耗时会很长,这个时候缓冲条是必不可少的.这里展示一个devexpress不错的缓冲条,如图所示: 使用到了控件splashScreenManager,运 ...
- LruCache原理解析
LruCache是一个泛型类,它内部采用LinkedHashMap,并以强引用的方式存储外界的缓存对象,提供get和put方法来完成缓存的获取和添加操作.当缓存满时,LruCache会移除较早的缓存对 ...
- angular.js学习笔记:实现商品价格计算实例
<!DOCTYPE html> <html lang="en" ng-app> <!-- ng-app:初始化的指令 也可以解析局部--> &l ...
- SpringMVC 集成velocity
前言 没有美工的时代自然少不了对应的模板视图开发,jsp时代我们用起来也很爽,物极必反,项目大了,数据模型复杂了jsp则无法胜任. 开发环境 idea2016.jdk1.8.tomcat8.0.35 ...
- ubuntu16.04下安装配置深度学习环境(一、cuda7.5的安装)
1.下载所需要的软件 cuda7.5下载(点击下载链接),cudnn4.0下载 2.安装NVIDIA驱动. 一般有两种方法:1)一种方法是利用"软件和更新"来安装,依次选择 系统设 ...