基于python的爬虫(一)
抓取网页
python核心库
urllib2
实现对静态网页的抓取,不得不说,“人生苦短,我用python”这句话还是有道理的,要是用java来写,这估计得20行代码
(对不住了博客园了,就拿你开刀吧)
def staticFetch():
url = "http://www.cnblogs.com/"
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read()
实现对动态网页的抓取,采用post请求,如果想用get方法,只需要把参数接在url后面,不需要data这个参数
def postFetch():
data = 'Keywords:爬虫'
url = "http://zzk.cnblogs.com/s/blogpost?Keywords=%E7%88%AC%E8%99%AB"
request = urllib2.Request(url, data)
response = urllib2.urlopen(request)
print response.read()
匹配数据
|
正则表达式 |
解释 |
案例(伪代码) |
|
.* |
贪婪模式,匹配除了换行符之外的所有字符 |
str = abcbc regex = a.*c return abcbc |
|
.*? |
非贪婪模式 |
str = abcbc regex = a.*c return abc |
|
(.*?) |
表示只要匹配这一部分 如果是匹配多个则返回的是一个元组类型 |
str = abcbc regex = a(.*)c return b |
|
more |
伪造浏览器请求
urllib2.HTTPError: HTTP Error 403: Forbidden
当你在运行python的时候出现这个错误,则该网址设置过了禁止爬虫访问,需要伪装一下http的请求头,加入如下代码再运行就ok了。
head={'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
urllib2.Request(url,headers=head)
网页乱码问题
看看爬下来的html是什么编码格式的
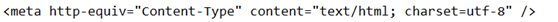
一般都是utf-8,也有gb2312和asic的,保证你的编码和网页的编码是同一种编码。
中文乱码
如果爬下来的网页打印的时候出现\xe6\x96\xb0\xe4\xba\xba这种信息,你可以用以下语句转换成字符串查看
','.join(str)
参考资料
//一个python爬虫从入门到放弃的好博客
http://cuiqingcai.com/1052.html
基于python的爬虫(一)的更多相关文章
- 基于python的爬虫项目
一.项目简介 1.1 项目博客地址 https://www.cnblogs.com/xsfa/p/12083913.html 1.2 项目完成的功能与特色 爬虫和拥有三个可视化数据分析 1.3 项目采 ...
- 基于python的爬虫流程图(精简版)
网址: https://www.processon.com/view/link/5e1148b8e4b07db4cfa9cf34 如果链接失效,请及时反馈(在评论区评论),博主会及时更新
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- 基于python的知乎开源爬虫 zhihu_oauth使用介绍
今天在无意之中发现了一个知乎的开源爬虫,是基于Python的,名字叫zhihu_oauth,看了一下在github上面star数还挺多的,貌似文档也挺详细的,于是就稍微研究了一下.发现果然很好用啊.就 ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- 基于python的知乎开源爬虫 zhihu
今天在无意之中发现了一个知乎的开源爬虫,是基于Python的,名字叫zhihu_oauth,看了一下在github上面star数还挺多的,貌似文档也挺详细的,于是就稍微研究了一下.发现果然很好用啊.就 ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- 基于python爬虫的github-exploitdb漏洞库监控与下载
基于python爬虫的github-exploitdb漏洞库监控与下载 offensive.py(爬取项目历史更新内容) #!/usr/bin/env python # -*- coding:utf- ...
- 基于python的pixiv爬虫
基于python的pixiv爬虫 1.目标 在和朋友吹逼过程中,聊到qq群机器人,突发奇想动手做一个p站每日推荐色图的色图机,遂学习爬虫. 目标: 批量下载首页推荐色图. 由于对qq机器人不熟,先利用 ...
随机推荐
- iOS 关于js与OC相互调用的那些事
最近项目上使用js调用OC,OC再次调用JS,再次在JS页面上面回显数据. 项目中使用的是WKWebview,加载网路的URL,其实就是使用WK加载出来的H5网页,在项目中用的是H5网页有个识别按钮, ...
- 【Flex】编辑器的缩放功能(绝对定位和相对定位)
一.横向的ide拖动缩放效果 <?xml version="1.0" encoding="utf-8"?> <s:WindowedApplic ...
- 【Electron】Electron开发入门(七):打开本地文件或者网页链接 and webview里操纵electron api
1.打开本地文件或者网页链接 // 打开系统本地文件 const {shell} = require('electron'); // Open a local file in the default ...
- poptest分享计划以及提供的服务
poptest分享计划以及提供的服务 POPTEST致力于测试开发工程师的培养,能让学员经过系统培训后从事自动化测试工作,包括功能自动化.性能自动化.接口自动化以及移动端系统的自动化测试等,由于移动端 ...
- 老李分享:《Linux Shell脚本攻略》 要点(五)
老李分享:<Linux Shell脚本攻略> 要点(五) //1.打包.解包 [root@localhost program_test]# tar -cf output.tar 11. ...
- Linux命令速查大全
常用基本命令 ls 显示文件或目录 -l 列出文件详细信息l(list) -a 列出当前目录下所有文件及目录,包括隐藏的a(all) mkdir 创建目录 -p 创建目录,若无父目录,则创建p(par ...
- iOS项目之模拟请求数据
如何在iOS开发中更好的做假数据? 当工期比较紧的时候,项目开发中会经常出现移动端等待后端接口数据的情形,不但耽误项目进度,更让人有种无奈的绝望.所以在开发中,我们常常自己做些假数据,以方便开发和UI ...
- UIDatePicker的使用
UIDatePicker的介绍 UIDatePicker这个类的对象让用户可以在多个车轮上选择日期和时间.iPhone手机上的‘时钟’应用程序中的时间与闹铃中便使用了该控件.使用这个控件时,如果你能配 ...
- Java中log4j的使用
前言 距离上一篇文章又过去好长时间了,这段时间一直忙于工作,已经从net彻底转向Java了.工作也慢慢的步入正轨了,自己独自完成了一个小项目,不过工作中遇到了一些问题,还是得到了同学和同事的帮助.本来 ...
- 事务隔离级别与传播机制,spring+mybatis+atomikos实现分布式事务管理
1.事务的定义:事务是指多个操作单元组成的合集,多个单元操作是整体不可分割的,要么都操作不成功,要么都成功.其必须遵循四个原则(ACID). 原子性(Atomicity):即事务是不可分割的最小工作单 ...