Breadth-first search 算法(Swift版)
在讲解Breadth-first search 算法之前,我们先简单介绍两种数据类型Graph和Queue。
Graph
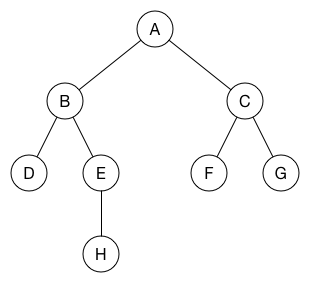
这就是一个图,它由两部分组成:
- 节点, 使用圆圈表示的部分
- 边, 使用线表示的地方,通常都是有方向的线
这种数据结构可以形象的表示一个网络,而在实际解决问题的时候,我们除了找到类似网络的模拟外,还需要考虑下边两点:
- 需要找到某条路径
- 需要找到到达某个节点的最短路径
而如何实现这个查找的过程就用到了算法。
在项目管理专业的工程方法中,存在一个有向连接图方法,根据这个图我们就可以划出邻接矩阵,然后再求出可达矩阵,缩减矩阵等等,说这些内容,是想表达在用代码模拟图的时候,可以使用矩阵的方式来描述,但本篇中采用的是另一种方式,我们使用数组保存某个节点的neighbor节点。
上边一段话会在下边的代码中进行展示:
Graph.swift
// MARK: - Edge
public class Edge: Equatable {
public var neighbor: Node
public init(neighbor: Node) {
self.neighbor = neighbor
}
}
public func == (lhs: Edge, rhs: Edge) -> Bool {
return lhs.neighbor == rhs.neighbor
}
// MARK: - Node
public class Node: CustomStringConvertible, Equatable {
public var neighbors: [Edge]
public private(set) var label: String
public var distance: Int?
public var visited: Bool
public init(label: String) {
self.label = label
neighbors = []
visited = false
}
public var description: String {
if let distance = distance {
return "Node(label: \(label), distance: \(distance))"
}
return "Node(label: \(label), distance: infinity)"
}
public var hasDistance: Bool {
return distance != nil
}
public func remove(edge: Edge) {
neighbors.remove(at: neighbors.index { $0 === edge }!)
}
}
public func == (lhs: Node, rhs: Node) -> Bool {
return lhs.label == rhs.label && lhs.neighbors == rhs.neighbors
}
// MARK: - Graph
public class Graph: CustomStringConvertible, Equatable {
public private(set) var nodes: [Node]
public init() {
self.nodes = []
}
public func addNode(_ label: String) -> Node {
let node = Node(label: label)
nodes.append(node)
return node
}
public func addEdge(_ source: Node, neighbor: Node) {
let edge = Edge(neighbor: neighbor)
source.neighbors.append(edge)
}
public var description: String {
var description = ""
for node in nodes {
if !node.neighbors.isEmpty {
description += "[node: \(node.label) edges: \(node.neighbors.map { $0.neighbor.label})]"
}
}
return description
}
public func findNodeWithLabel(_ label: String) -> Node {
return nodes.filter { $0.label == label }.first!
}
public func duplicate() -> Graph {
let duplicated = Graph()
for node in nodes {
_ = duplicated.addNode(node.label)
}
for node in nodes {
for edge in node.neighbors {
let source = duplicated.findNodeWithLabel(node.label)
let neighbour = duplicated.findNodeWithLabel(edge.neighbor.label)
duplicated.addEdge(source, neighbor: neighbour)
}
}
return duplicated
}
}
public func == (lhs: Graph, rhs: Graph) -> Bool {
return lhs.nodes == rhs.nodes
}
Queue
队列同样是一种数据结构,它遵循FIFO的原则,因为Swift没有现成的这个数据结构,因此我们手动实现一个。
值得指出的是,为了提高性能,我们针对在数组中读取数据做了优化。比如,当在数组中取出第一个值时,如果不做优化,那么这一步的消耗为O(n),我们采取的解决方法就是把该位置先置为nil,然后设置一个阈值,当达到阈值时,在对数组做进不去的处理。
这一部分的代码相当简单
Queue.swift
public struct Queue<T> {
fileprivate var array = [T?]()
fileprivate var head = 0
public init() {
}
public var isEmpty: Bool {
return count == 0
}
public var count: Int {
return array.count - head
}
public mutating func enqueue(_ element: T) {
array.append(element)
}
public mutating func dequeue() -> T? {
guard head < array.count, let element = array[head] else { return nil }
array[head] = nil
head += 1
let percentage = Double(head) / Double(array.count)
if array.count > 50 && percentage > 0.25 {
array.removeFirst(head)
head = 0
}
return element
}
public var front: T? {
if isEmpty {
return nil
} else {
return array[head]
}
}
}
Breadth-first search
其实这个算法的思想也很简单,我们已源点为中心,一层一层的往外查找,在遍历到某一层的某个节点时,如果该节点是我们要找的数据,那么就退出循环,如果没找到,那么就把该节点的neighbor节点加入到队列中,这就是该算法的核心原理。
打破循环的条件需要根据实际情况来设定。
//: Playground - noun: a place where people can play
import UIKit
import Foundation
var str = "Hello, playground"
func breadthFirstSearch(_ graph: Graph, source: Node) -> [String] {
/// 创建一个队列并把源Node放入这个队列中
var queue = Queue<Node>()
queue.enqueue(source)
/// 创建一个数组用于存放结果
var nodesResult = [source.label]
/// 设置Node的visited为true,因为我们会把这个当做一个开关
source.visited = true
/// 开始遍历
while let node = queue.dequeue() {
for edge in node.neighbors {
let neighborNode = edge.neighbor
if !neighborNode.visited {
queue.enqueue(neighborNode)
neighborNode.visited = true
nodesResult.append(neighborNode.label)
}
}
}
return nodesResult
}
let graph = Graph()
let nodeA = graph.addNode("a")
let nodeB = graph.addNode("b")
let nodeC = graph.addNode("c")
let nodeD = graph.addNode("d")
let nodeE = graph.addNode("e")
let nodeF = graph.addNode("f")
let nodeG = graph.addNode("g")
let nodeH = graph.addNode("h")
graph.addEdge(nodeA, neighbor: nodeB)
graph.addEdge(nodeA, neighbor: nodeC)
graph.addEdge(nodeB, neighbor: nodeD)
graph.addEdge(nodeB, neighbor: nodeE)
graph.addEdge(nodeC, neighbor: nodeF)
graph.addEdge(nodeC, neighbor: nodeG)
graph.addEdge(nodeE, neighbor: nodeH)
graph.addEdge(nodeE, neighbor: nodeF)
graph.addEdge(nodeF, neighbor: nodeG)
let nodesExplored = breadthFirstSearch(graph, source: nodeA)
print(nodesExplored)
总结
实现的代码不是重点,重要的是理解这些思想,在实际情况中能够得出解决的方法。当然跟实现的语言也没有关系。
使用playground时,command + 1可以看到Source文件夹,把单独的类放进去就可以加载进来了。上边的内容来自这个网站swift-algorithm-club
Breadth-first search 算法(Swift版)的更多相关文章
- Dijkstra算法(Swift版)
原理 我们知道,使用Breadth-first search算法能够找到到达某个目标的最短路径,但这个算法没考虑weight,因此我们再为每个edge添加了权重后,我们就需要使用Dijkstra算法来 ...
- 算法与数据结构(四) 图的物理存储结构与深搜、广搜(Swift版)
开门见山,本篇博客就介绍图相关的东西.图其实就是树结构的升级版.上篇博客我们聊了树的一种,在后边的博客中我们还会介绍其他类型的树,比如红黑树,B树等等,以及这些树结构的应用.本篇博客我们就讲图的存储结 ...
- 快速排序OC、Swift版源码
前言: 你要问我学学算法在工作当中有什么用,说实话,当达不到那个地步的时候,可能我们不能直接的感觉到它的用处!你就抱着这样一个心态,当一些APP中涉及到算法的时候我不想给其他人画界面!公司的项目也是暂 ...
- 广度优先搜索(Breadth First Search, BFS)
广度优先搜索(Breadth First Search, BFS) BFS算法实现的一般思路为: // BFS void BFS(int s){ queue<int> q; // 定义一个 ...
- 【数据结构与算法Python版学习笔记】图——词梯问题 广度优先搜索 BFS
词梯Word Ladder问题 要求是相邻两个单词之间差异只能是1个字母,如FOOL变SAGE: FOOL >> POOL >> POLL >> POLE > ...
- Swift版iOS游戏框架Sprite Kit基础教程下册
Swift版iOS游戏框架Sprite Kit基础教程下册 试读下载地址:http://pan.baidu.com/s/1qWBdV0C 介绍:本教程是国内唯一的Swift版的Spritekit教程. ...
- 从vector容器中查找一个子串:search()算法
如果要从vector容器中查找是否存在一个子串序列,就像从一个字符串中查找子串那样,次数find()与find_if()算法就不起作用了,需要采用search()算法:例子: #include &qu ...
- Swift版音乐播放器(简化版),swift音乐播放器
这几天闲着也是闲着,学习一下Swift的,于是到开源社区Download了个OC版的音乐播放器,练练手,在这里发扬开源精神, 希望对大家有帮助! 这个DEMO里,使用到了 AudioPlayer(对音 ...
- iOS可视化动态绘制八种排序过程(Swift版)
前面几篇博客都是关于排序的,在之前陆陆续续发布的博客中,我们先后介绍了冒泡排序.选择排序.插入排序.希尔排序.堆排序.归并排序以及快速排序.俗话说的好,做事儿要善始善终,本篇博客就算是对之前那几篇博客 ...
随机推荐
- java中属性,set get 以及如何学习类的一些用法
1,先来看一个例子 package com.tdq.java; public class Run { public static void main(String[]args){ Student st ...
- FPGA与数字信号处理
过去十几年,通信与多媒体技术的快速发展极大地扩展了数字信号处理(DSP)的应用范围.眼下正在发生的是,以更高的速度和更低的成本实现越来越复杂的算法,这是针对高级信息服更高带宽以及增强的多媒体处理能力等 ...
- Java面向对象 线程技术 -- 下篇
Java面向对象 线程技术 -- 下篇 知识概要: (1)线程间的通信 生产者 - 消费者 (2)生产者消费者案例优化 (3)守护线程 (4)停止线 ...
- 深刻理解反射(Reflection)
最近公司在搞自动化测试,由于版权问题,无法用 '录制脚本' 进行,也就没法用 VS 自带的 UITest 框架(蛋疼), 所以只能开源的 FlaUI 框架来搞了.其中不可避免的涉及到反射的应用,但自己 ...
- Echarts数据可视化parallel平行坐标系,开发全解+完美注释
全栈工程师开发手册 (作者:栾鹏) Echarts数据可视化开发代码注释全解 Echarts数据可视化开发参数配置全解 6大公共组件详解(点击进入): title详解. tooltip详解.toolb ...
- 【转载】CSS direction属性简介与实际应用
文章转载自 张鑫旭-鑫空间-鑫生活 http://www.zhangxinxu.com/wordpress/ 原文链接:http://www.zhangxinxu.com/wordpress/?p=5 ...
- Pycharm小技巧--使用正则进行查找和批量替换
分享一个Pycharm中使用正则的分组匹配来进行批量替换的小技巧 例如,我现在需要把HTML文件中的静态文件得到路径全部替换为django模板引用路径的格式 修改为类似这样的格式: {% static ...
- Volley图片加载并加入缓存处理(转自http://blog.csdn.net/viewhandkownhealth/article/details/50957024)
直接上代码 两种方式 ImageView 和NetworkImageView 如有问题或者好的建议.意见 欢迎大家加入技术群(群号: 387648673 ) 先自定义全局Application 获取 ...
- Single Number2
题目链接:http://oj.leetcode.com/problems/single-number-ii/ Given an array of integers, every element app ...
- 使用Git与Github创建自己的远程仓库
原因 早就想创建一个自己的远程仓库,方便发布到Nuget上,自己用也好,项目组用也好,都方便. 今天抽了个时间建了个仓库,随便记下溜方便后来的人. 流程 1,创建自己的GitHub仓库 首先需要到 G ...