python+NLTK 自然语言学习处理二:文本
在前面讲nltk安装的时候,我们下载了很多的文本。总共有9个文本。那么如何找到这些文本呢:
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
直接输入它们的名字就可以了
print text1
print text2
E:\python2.7.11\python.exe
E:/py_prj/NLTK_study/chapter1.py
<Text: Moby Dick
by Herman Melville 1851>
<Text: Sense and
Sensibility by Jane Austen 1811>
我们还可以对文本中的单词进行查找。
print text1.concordance('monstrous')
结果如下,找到了11个匹配的地方
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ... This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himmal
they might scout at Moby Dick as a monstrous fable , or still worse and more de
th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
None
如果我们想知道单词出现在文本的那些位置,比如是在文本开始处多些呢,还是在文本末尾开始多些。这里就用到dispersion_plot函数。Text4的名称为Inaugural Address Corpus,中文意思是就职演说的意思。因此在text4中有整理的美国总统就职演说的文本。从里面的文本来看有从1789年到2009年的总统就职演说
我们来看下citizens,democracy,freedom,duties,American出现的位置
print len(text4)
text4.dispersion_plot(["citizens","democracy","freedom","duties","American"])
E:\python2.7.11\python.exe E:/py_prj/NLTK_study/chapter1.py
145735
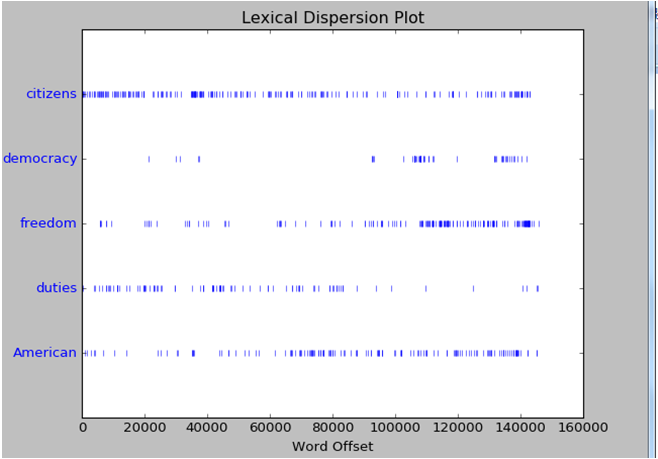
首先text4的长度为145735。上面的散点图就是生成的结果。注意,要得到这个散点图必须先安装Numpy以及Matplotlib。否则在画图的时候会报错。
从上面的这个散点图我们可以看到citizens是出现得最多的地方。Citizens的中文意思是市民,公民的意思。这也符合美国的一贯政治风格嘛。总统是在现场做演说自然首先就得来和选民们拉近关系。套套近乎嘛。而随着演讲的进行,American和freedom之类的词语就开始多起来了。和选民和拉近关系了后,后面就要开始普世价值以及爱国情绪煽动了。什么捍卫人类的freedom,为了American的强大之类的话语。
我们再多来点词汇看看:我们加入了china,tax,security,immigrant。分别是中国,税收,安全,移民
text4.dispersion_plot(["citizens","democracy","freedom","duties","American","china","tax",'security','immigrant'])

从上面的图可以看到明显少了的很多,除了security和tax有一些之外。诸如china,immigrant这些词基本就没出现。其实我们加入的china,tax,security,immigrant这些词语都是一些具体国家事务的词。但是在就职演说看不到半点的描述。因此我们可以认为总统的就职演说重点不是施政纲领,哪是在竞选的时候才会提到。就职演说就是个口才show。
如果想文本里面都有哪些单词,可以用set(text4)查看在总统的就职演说中出现了哪些词。由于量太大,这里就不列举出来了。既然知道了总的词数个数以及词的汇总,那么我们可以来计算每个词出现的频度了。从下面结果看到在text4中每个单词的出现频率平均是14次。
print 'the length of text4 is %d' % len(text4)
print len(text4) / len(set(text4))
E:\python2.7.11\python.exe E:/py_prj/NLTK_study/chapter1.py
the length of text4 is 145735
14
那么在这些演讲中这些词出现的次数是多少呢。我们以上图的citizens为例。可以看到citizizens出现了230次。
print text4.count('citizens')
E:\python2.7.11\python.exe E:/py_prj/NLTK_study/chapter1.py
230
那如果我们要找出在总统就职演说中出现最多的词该怎么办呢。是通过对单词一个个的计数来得出结果? 那样太费时间了。NLTK提供了专门的函数做到这一点。
fdist1=FreqDist(text4)
vocabulary1=fdist1.keys()
print vocabulary1[:10]
fdist1.plot(10,cumulative=True)
FreqDist是一个统计频率分布的函数,通过fdist1.plot我们可以画出用得最多的10个单词的分布。

我们可以细化一点,如何统计次数超过500次的单词呢。
fdist1=FreqDist(text4)
list=[w for w in set(text4) if fdist1[w] > 500]
[u'.', u'has', u'people', u'for', u'I', u'with', u'as', u'to', u'be', u'by', u'this', u'we', u'the', u'not', u'that', u'a', u'The', u';', u',', u'is', u'it', u'in', u'have', u'our', u'and', u'its', u'of', u'or', u'all', u'are', u'from', u'their', u'which', u'will']
这些词的次数都超过500词,可以认为是高频词。
list=[w for w in set(text4) if len(w) > 15].结果如下:
[u'internationality', u'misappropriation', u'irresponsibility', u'enthusiastically', u'disqualification', u'misrepresentation', u'misunderstanding', u'antiphilosophists', u'responsibilities', u'contradistinction', u'transcontinental', u'unconstitutional', u'discountenancing', u'sentimentalizing', u'uncharitableness', u'constitutionally', u'instrumentalities', u'RESPONSIBILITIES'
还可以通过print fdist1.max()来查看出现最多的单词。结果是the。
要计算单词的频率可以通过print fdist1.freq('internationality')来得到
python+NLTK 自然语言学习处理二:文本的更多相关文章
- python+NLTK 自然语言学习处理四:获取文本语料和词汇资源
在前面我们通过from nltk.book import *的方式获取了一些预定义的文本.本章将讨论各种文本语料库 1 古腾堡语料库 古腾堡是一个大型的电子图书在线网站,网址是http://www.g ...
- python+NLTK 自然语言学习处理八:分类文本一
从这一章开始将进入到关键部分:模式识别.这一章主要解决下面几个问题 1 怎样才能识别出语言数据中明显用于分类的特性 2 怎样才能构建用于自动执行语言处理任务的语言模型 3 从这些模型中我们可以学到那些 ...
- python+NLTK 自然语言学习处理:环境搭建
首先在http://nltk.org/install.html去下载相关的程序.需要用到的有python,numpy,pandas, matplotlib. 当安装好所有的程序之后运行nltk.dow ...
- python+NLTK 自然语言学习处理六:分类和标注词汇一
在一段句子中是由各种词汇组成的.有名词,动词,形容词和副词.要理解这些句子,首先就需要将这些词类识别出来.将词汇按它们的词性(parts-of-speech,POS)分类并相应地对它们进行标注.这个过 ...
- python+NLTK 自然语言学习处理三:如何在nltk/matplotlib中的图片中显示中文
我们首先来加载我们自己的文本文件,并统计出排名前20的字符频率 if __name__=="__main__": corpus_root='/home/zhf/word' word ...
- python+NLTK 自然语言学习处理七:N-gram标注
在上一章中介绍了用pos_tag进行词性标注.这一章将要介绍专门的标注器. 首先来看一元标注器,一元标注器利用一种简单的统计算法,对每个标识符分配最有可能的标记,建立一元标注器的技术称为训练. fro ...
- python+NLTK 自然语言学习处理五:词典资源
前面介绍了很多NLTK中携带的词典资源,这些词典资源对于我们处理文本是有大的作用的,比如实现这样一个功能,寻找由egivronl几个字母组成的单词.且组成的单词每个字母的次数不得超过egivronl中 ...
- Python+NLTK自然语言处理学习(一):环境搭建
Python+NLTK自然语言处理学习(一):环境搭建 参考黄聪的博客地址:http://www.cnblogs.com/huangcong/archive/2011/08/29/2157437.ht ...
- Python NLTK 自然语言处理入门与例程(转)
转 https://blog.csdn.net/hzp666/article/details/79373720 Python NLTK 自然语言处理入门与例程 在这篇文章中,我们将基于 Pyt ...
随机推荐
- 用VsCode编辑TypeScript
文地址:https://code.visualstudio.com/Docs/languages/typescript TypeScript是Javascript的超集,它提供了类.模块.接口来帮助你 ...
- jdbc3
- PHP面向对象之解释器模式
在博客园逛了1年多,从来都是看文章但没发表过什么文章.主要是因为技术太菜了,只有学习的份,自己那点水平实在也没什么好去分享的.但是最近在看 “深入PHP面向对象模式与实践” ,学习书中的内容后瞬间觉得 ...
- linux系统管理--查看进程
关于进程的查看,大家都不会陌生 ,主要是ps和pstree命令. ps aux 查看系统中所有进程,使用BSD操作系统格式.(注意:不是ps -aux) 执行结果 USER :该进程是由哪个用 ...
- 学java网络编程的心得体会
网络编程简单思路 一.发送端1创建udp服务,通过DatagramSocket对象;2确定数据,封装成包DatagramPacket(byte[] buf, int length, InetAddre ...
- CodeBlocks
- JS高级-数据结构的封装
最近在看了<数据结构与算法JavaScript描述>这本书,对大学里学的数据结构做了一次复习(其实差不多忘干净了,哈哈).如果能将这些知识捡起来,融入到实际工作当中,估计编码水平将是一次质 ...
- Linux中重定向
转:http://blog.csdn.net/songyang516/article/details/6758256 1重定向 1.1 重定向符号 > 输出 ...
- Java反射机制剖析(二)-功能以及举例
从<java反射机制剖析(一)>的API我们看到了许多接口和类,我们能够通过这些接口做些什么呢? 从上篇API中我们能看到它能够完成下面的这些功能: 1) 获得类 A. 运 ...
- js继承之原型链继承
面向对象编程都会涉及到继承这个概念,JS中实现继承的方式主要是通过原型链的方法. 一.构造函数.原型与实例之间的关系 每创建一个函数,该函数就会自动带有一个 prototype 属性.该属性是个指针, ...