[数据预处理]-中心化 缩放 KNN(一)
据预处理是总称,涵盖了数据分析师使用它将数据转处理成想要的数据的一系列操作。例如,对某个网站进行分析的时候,可能会去掉 html 标签,空格,缩进以及提取相关关键字。分析空间数据的时候,一般会把带单位(米、千米)的数据转换为“单元性数据”,这样,在算法的时候,就不需要考虑具体的单位。数据预处理不是凭空想象出来的。换句话说,预处理是达到某种目的的手段,并且没有硬性规则,一般会跟根据个人经验会形成一套预处理的模型,预处理一般是整个结果流程中的一个环节,并且预处理的结果好坏需要放到到整个流程中再进行评估。
机器学习分类问题简介
机器学习的 KNN 分类
图说 K 邻近
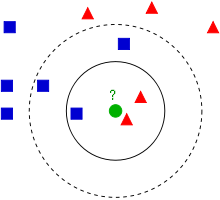

Scikit Learn KNN


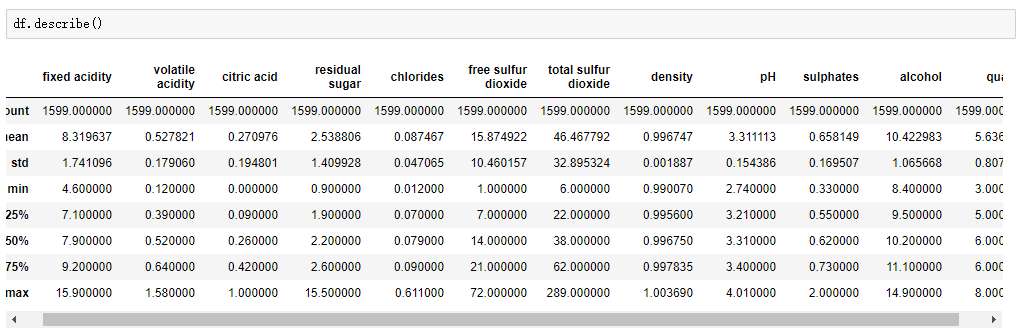

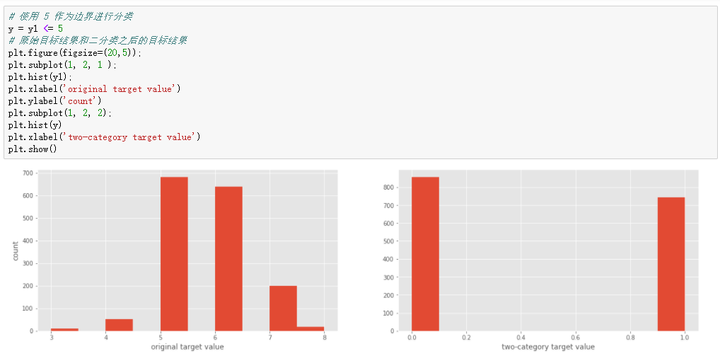
如何评价 KNN 结果
Accuracy = 正确预测数量/预测总数
KNN 的使用和训练测试的分割



预告 [数据预处理]-中心化 缩放 KNN(二)
使用其他的评估方法(reacll,f1)重新评估结果
使用预处理将精度结果再提高 10% 左右
完整的代码
[数据预处理]-中心化 缩放 KNN(一)的更多相关文章
- [机器学习]-[数据预处理]-中心化 缩放 KNN(二)
上次我们使用精度评估得到的成绩是 61%,成绩并不理想,再使 recall 和 f1 看下成绩如何? 首先我们先了解一下 召回率和 f1. 真实结果 预测结果 预测结果 正例 反例 正例 TP 真 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 一个轻client,多语言支持,去中心化,自己主动负载,可扩展的实时数据写服务的实现方案讨论
背景 背景是设计一个实时数据接入的模块,负责接收client的实时数据写入(如日志流,点击流),数据支持直接下沉到HBase上(兴许提供HBase上的查询),或先持久化到Kafka里.方便兴许进行一些 ...
- 数据预处理:规范化(Normalize)和二值化(Binarize)
注:本文是人工智能研究网的学习笔记 规范化(Normalization) Normalization: scaling individual to have unit norm 规范化是指,将单个的样 ...
- 任何国家都无法限制数字货币。为什么呢? 要想明白这个问题需要具备一点区块链的基础知识: 区块链使用的大致技术包括以下几种: a.点对点网络设计 b.加密技术应用 c.分布式算法的实现 d.数据存储技术 e.拜占庭算法 f.权益证明POW,POS,DPOS 原因一: 点对点网络设计 其中点对点的P2P网络是bittorent ,由于是点对点的网络,没有中心化,因此在全球分布式的网
任何国家都无法限制数字货币.为什么呢? 要想明白这个问题需要具备一点区块链的基础知识: 区块链使用的大致技术包括以下几种: a.点对点网络设计 b.加密技术应用 c.分布式算法的实现 d.数据存储技 ...
- 数据预处理 | 使用 Pandas 进行数值型数据的 标准化 归一化 离散化 二值化
1 标准化 & 归一化 导包和数据 import numpy as np from sklearn import preprocessing data = np.loadtxt('data.t ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
- python数据预处理for knn
机器学习实战 一书中第20页数据预处理,从文本中解析数据的程序. import numpy as np def dataPreProcessing(fileName): with open(fileN ...
- Scikit-learn:数据预处理Preprocessing data
http://blog.csdn.net/pipisorry/article/details/52247679 本blog内容有标准化.数据最大最小缩放处理.正则化.特征二值化和数据缺失值处理. 基础 ...
随机推荐
- 为什么硬链接不能链接目录、文件inode 和目录 dentry 的区别联系
我们对任何一个目录用ls -l 命令都可以看到其连接数至少是2,这也说明了系统中是存在硬连接的,而且命令ln -d 也可以让超级用户对目录作硬连接,这些都说明了系统限制对目录进行硬连接只是一个硬性规定 ...
- Linux第八讲随笔 -tar / 系统启动流程
linux 第八讲1.tar 参考 作用:压缩和解压文件.tar本身不具有压缩功能.他是调用压缩功能实现的. 语法:tar[必要参数][选择参数][文件] 参数:必要参数有如下: -A 新增压缩文件到 ...
- 用Go校验下载文件之SHA256
用GO校验下载文件之SHA256 原来对计算机和网络使用安全这块不够重视,用了N多年盗版的操作系统和办公软件,为了破解使用过各种激活软件,也安装使用过很多别人破解过的软件:网络下载的文件从不校验.慢慢 ...
- Errors are values
原文地址 https://blog.golang.org/errors-are-values Go程序员之间(特别是这些刚接触Go语言的新人)一个常见的讨论点是如何处理错误.谈话经常变成为对如下代码序 ...
- C# 命名空间和程序集
一.命名空间 1.通过使用using关键字引入命名空间,减少代码量 命名空间对相关的类型进行逻辑分组,通过命名空间能快速的定位到相关的类型,例如:在System.IO命名空间下,定义了所有I/O操作的 ...
- php中const与define的区别
1 版本差异: const 要求php的版本>5.3.0 define 可以兼容php4,php5 等版本 2 定义的位置区别: const关键字定义的常量是在编译时定义的,因此const关键字 ...
- 物联网细分领域-车联网(OBD)市场分析
前言: 这段时间在跟一个车联网的项目,所以做了一些研究. OBD概述 OBD是英文On-Board Diagnostic的缩写,中文翻译为"车载诊断系统".这个系统随时监控发动机的 ...
- 微服务时代TestOps工程师学习总结
TestOps很新鲜,也是近期衍生的新型职位.那TestOps主要目的是推动整个研发体系与发布体系更多在质量方面.可以这样理解DevOps是从研发推动配合运维和测试,而TestOps是从测试角度推动研 ...
- [Spark内核] 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解
本课主题 CacheManager 运行原理图 CacheManager 源码解析 CacheManager 运行原理图 [下图是CacheManager的运行原理图] 首先 RDD 是通过 iter ...
- [Spark性能调优] 第二章:彻底解密Spark的HashShuffle
本課主題 Shuffle 是分布式系统的天敌 Spark HashShuffle介绍 Spark Consolidated HashShuffle介绍 Shuffle 是如何成为 Spark 性能杀手 ...