(5)pyspark----共享变量
如果想在节点之间共享一份变量,spark提供了两种特定的共享变量,来完成节点之间的变量共享。
(1)广播变量(2)累加器
二、广播变量
概念:
广播变量允许程序员缓存一个只读的变量在每台机器上,而不是每个任务保存一个拷贝。例如,利用广播变量,我们能够以一种更有效率的方式将一个大数据量输入集合的副本分配给每个节点。
一个广播变量可以通过调用SparkContext.broadcast(v)方法从一个初始变量v中创建。广播变量是v的一个包装变量,它的值可以通过value方法访问。
用途:比如一个配置文件,可以共享给所有节点。比如一个Node的计算结果需要共享给其他节点。
声明:broadcast
调用broadcast,Scala中一切可序列化的对象都可以进行广播。
sc.broadcast(xxx)
引用广播变量数据:value
可在各个计算节点中通过 bc.value来引用广播的数据。

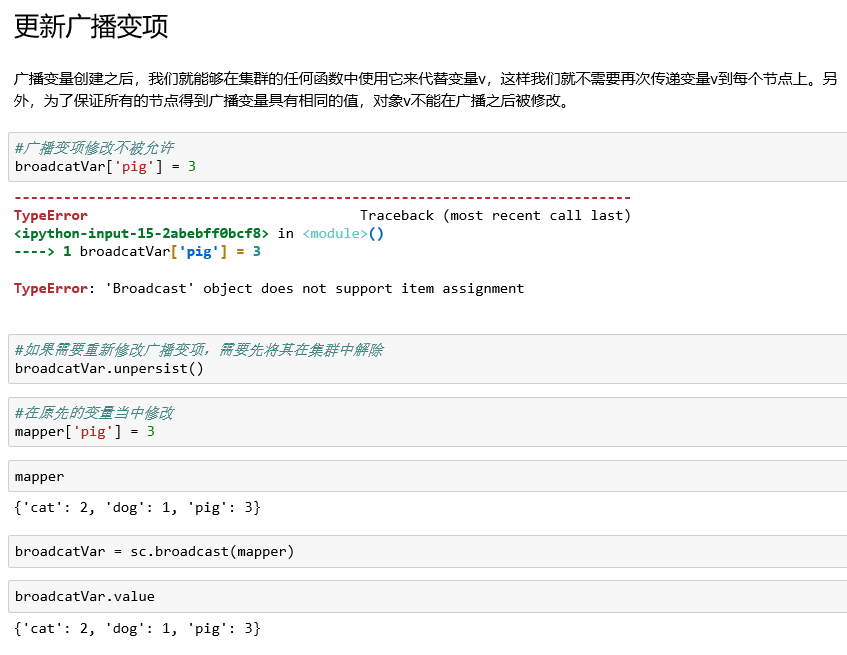
更新广播变量:unpersist
由于广播变量是只读的,即广播出去的变量没法再修改,
利用unpersist函数将老的广播变量删除,然后重新广播一遍新的广播变量。
bc.unpersist()
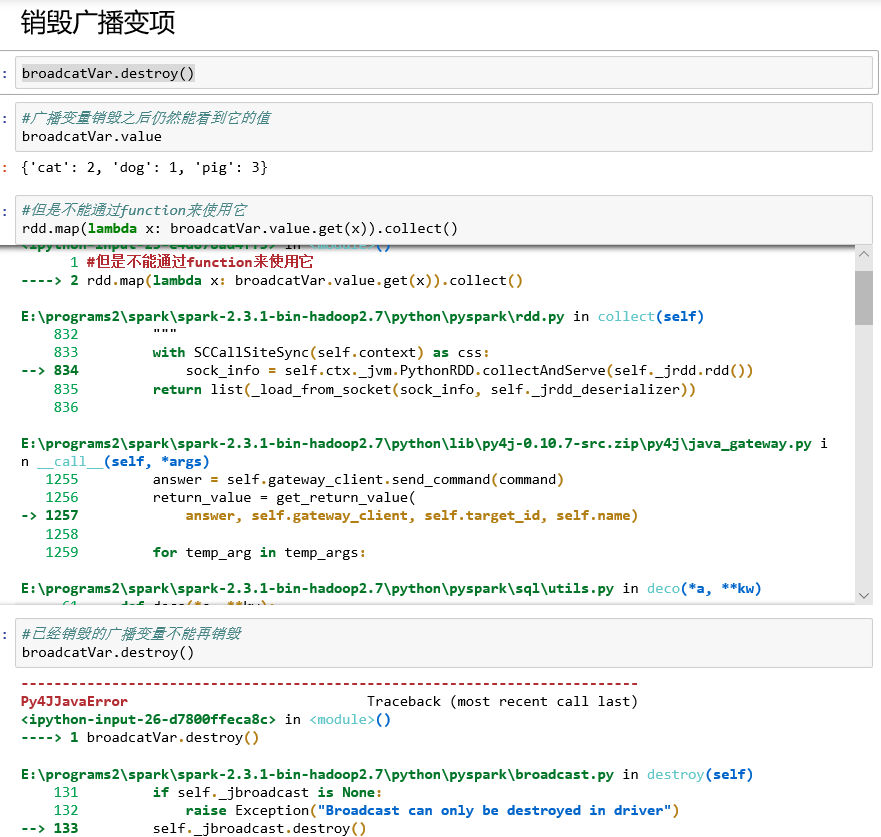
销毁广播变量:destroy
bc.destroy()可将广播变量的数据和元数据一同销毁,销毁之后就不能再使用了。
三、累加器
概念:
累加器是一种只能利用关联操作做“加”操作的变数,因此他能够快速执行并行操作。而且其能够操作counters和sums。Spark原本支援数值类型的累加器,程序员可以自行增加可被支援的类型。如果建立一个具体的累加器,其可在spark UI上显示。
用途:
对信息进行聚合,累加器的一个常见的用途是在调试时对作业的执行过程中事件进行计数。
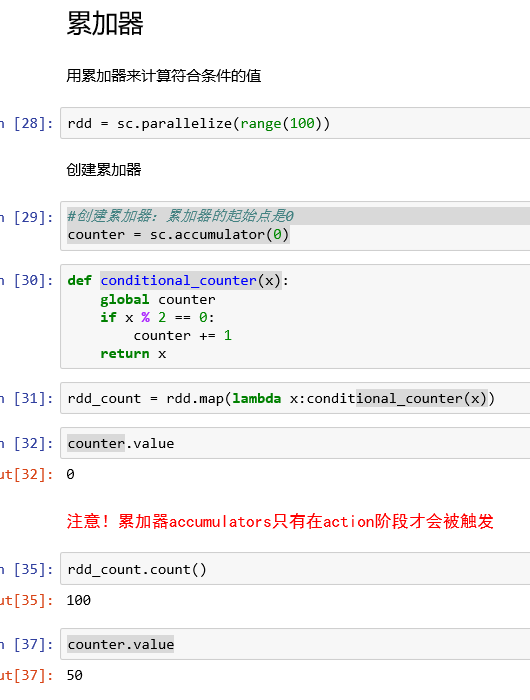
创建累加器:accumulator
调用SparkContext.accumulator(v)方法从一个初始变量v中创建。
运行在集群上的任务可以通过add方法或者使用+=操作来给它加值。然而,它们无法读取这个值。和广播变量相反,累加器是一种add only的变项。
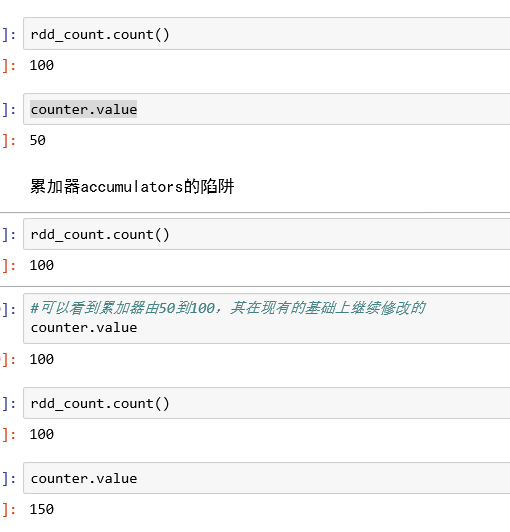
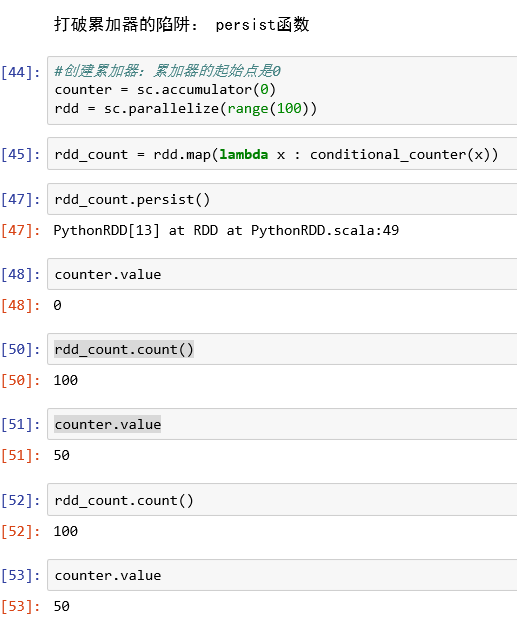
累加器的陷阱
打破累加器陷阱:persist函数

存累加器初始值:

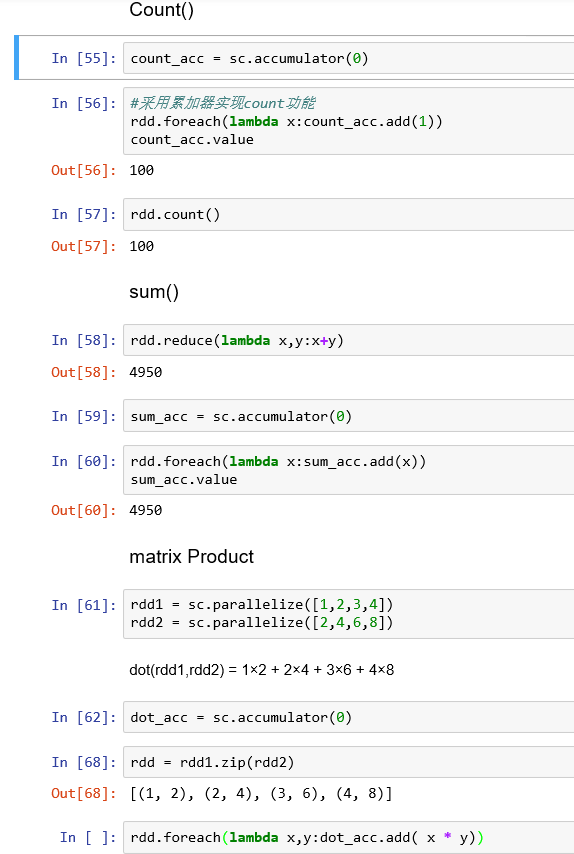
累加器实现一些基本的功能:
(5)pyspark----共享变量的更多相关文章
- pyspark 内容介绍(一)
pyspark 包介绍 子包 pyspark.sql module pyspark.streaming module pyspark.ml package pyspark.mllib package ...
- 5 pyspark学习---Broadcast&Accumulator&sparkConf
1 对于并行处理,Apache Spark使用共享变量.当驱动程序将任务发送给集群上的执行者时,集群中的每个节点上都有一个共享变量的副本,这样就可以用于执行任务了. 2 两种支持得类型 (1)Broa ...
- spark教程(14)-共享变量
spark 使用的架构是无共享的,数据分布在不同节点,每个节点有独立的 CPU.内存,不存在全局的内存使得变量能够共享,驱动程序和任务之间通过消息共享数据 举例来说,如果一个 RDD 操作使用了驱动程 ...
- Spark——共享变量
Spark执行不少操作时都依赖于闭包函数的调用,此时如果闭包函数使用到了外部变量驱动程序在使用行动操作时传递到集群中各worker节点任务时就会进行一系列操作: 1.驱动程序使将闭包中使用变量封装成对 ...
- spark 2.0 中 pyspark 对接 Ipython
pyspark 2.0 对接 ipython 在安装spark2.0 后,以往的对接ipython方法失效,会报如下错错误: 因为在spark2.0后对接ipython的方法进行了变更我们只需要在py ...
- sparksql---通过pyspark实现
上次在spark的一个群里面,众大神议论:dataset会取代rdd么? 大神1:听说之后的mlib都会用dataset来实现,呜呜,rdd要狗带 大神2:dataset主要是用来实现sql的,跟ml ...
- 动手学servlet(五) 共享变量
1. 无论对象的作用域如何,设置和读取共享变量的方法是一致的 -setAttribute("varName",obj); -getAttribute("varName&q ...
- Win7 单机Spark和PySpark安装
欢呼一下先.软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了.加油加油!!! 1. 安装方法参考: 已安装Pycharm 和 Intellij IDEA. win7 PySpark ...
- Java多线程——线程范围内共享变量
多个线程访问共享对象和数据的方式 1.如果每个线程执行的代码相同,可以使用同一个Runnable对象,这个Runnable对象中有那个共享数据,例如,买票系统就可以这么做. package java_ ...
- jupyter notebook + pyspark 环境搭建
安装并启动jupyter 安装 Anaconda 后, 再安装 jupyter pip install jupyter 设置环境 ipython --ipython-dir= # override t ...
随机推荐
- K3 新单到老单关联字段的添加
新单到老单字段的添加分为两种: 一种为文本字段信息的关联,新单与老单字段的信息均为文本字段: 另一种为基础资料信息的关联,新单与老单均为基础资料字段信息. K3 WISE 11.0中存储老 ...
- vue的计算属性get和set
1.计算属性是用来存储数据,但具有以下几个特点: a.数据可以进行逻辑处理操作. b.对计算属性中的数据进行监视. 2.计算属性和普通属性的区别: a.计算属性是基于它的依赖进行更新的,只有在相关依赖 ...
- Linux下清空文件的几种方法
$ : > filename $ > filename $ echo "" > filename $ echo > filename $ cat /dev/ ...
- JavaScript 三要素
一个完整的JavaScript 实现由3部分组成: ECMACcript ECMAScript 规定了这门语言的下列组成部分: 语法 类型 语句 关键字.保留字 操作符 对象为什么要使用DOM? ...
- Top English interview Q&A
http://www.hjenglish.com/new/p581292/ vocabulary endeavour [ɪn'devər] relevant ['reləvənt] , efficie ...
- Oracle学习总结(6)—— SQL注入技术
不管用什么语言编写的Web应用,它们都用一个共同点,具有交互性并且多数是数据库驱动.在网络中,数据库驱动的Web应用随处可见,由此而存在的SQL注入是影响企业运营且最具破坏性的漏洞之一. SQL注入基 ...
- selenium2+java切换窗口
package exercises; import java.util.ArrayList; import java.util.List; import java.util.Set; import o ...
- Spring自带字符编码过滤器
http://blog.csdn.net/youngage/article/details/51356821 http://blog.csdn.net/daelly/article/details/5 ...
- http数据绑定spring mvc详解
- 求最长回文子串,O(n)复杂度
最长回文子串问题-Manacher算法 最长回文串问题是一个经典的算法题. 0. 问题定义 最长回文子串问题:给定一个字符串,求它的最长回文子串长度. 假设一个字符串正着读和反着读是一样的,那它就是回 ...