【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解。从上一篇文章可以很快的了解PageRank的基础知识。相比其他一些文献的介绍,上一篇文章的介绍非常简洁明了。说明:本文的主要内容都是来自“赵国,宋建成.Google搜索引擎的数学模型及其应用,西南民族大学学报自然科学版.2010,vol(36),3”这篇学术论文。鉴于文献中本身提供了一个非常简单容易理解和入门的案例,所以本文就使用文章的案例和思路来说明PageRank的应用,文章中的文字也大部分是复制该篇论文,个人研究是对文章的理解,以及最后一篇的使用C#实现该算法的过程,可以让读者更好的理解如何用程序来解决问题。所以特意对作者表示感谢。如果有认为侵权,请及时联系我,将及时删除处理。
论文中的案例其实是来源于1993年全国大学生数学建模竞赛的B题—足球队排名问题。
本文原文链接:【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
1.足球队排名问题
1993年的全国大学生数学建模竞赛B题就出了这道题目,不过当时PageRank算法还没有问世,所以现在用PageRank来求解也只能算马后炮,不过可以借鉴一下思路,顺便可以加深对算法的理解,并可以观察算法实际的效果怎么样。顺便说一下,全国大学生数学建模竞赛的确非常有用,我在大学期间,连续参加过2004和2005年的比赛,虽然只拿了一个省二等奖,但是这个过程对我的影响非常大。包括我现在的编程,解决问题的思路都是从建模培训开始的。希望在校大学生珍惜这些机会,如果能入选校队,参加集训,努力学习,对以后的学习,工作都非常有帮助。下面看看这个题目的具体问题:
具体数据由于篇幅较大,已经上传为图片,需要看的,点击链接:数据链接

{kind=link}
2.利用PageRank算法的思路
2.1 问题分析
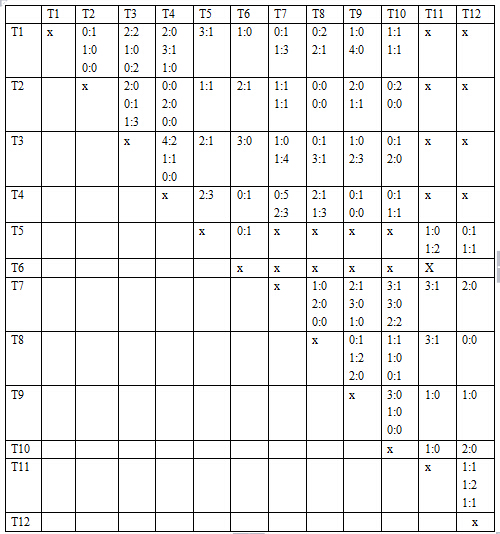
足球队排名次问题要求我们建立一个客观的评估方法,只依据过去一段时间(几个赛季或几年)内每个球队的战绩给出各个球队的名次,具有很强的实际背景.通过分析题中12支足球队在联赛中的成绩,不难发现表中的数据残缺不全,队与队之间的比赛场数相差很大,直接根据比赛成绩来排名次比较困难。
下面我们利用PageRank算法的随机冲浪模型来求解.类比PageRank算法,我们可以综合考虑各队的比赛成绩为每支球队计算相应的等级分(Rank),然后根据各队的等级分高低来确定名次,直观上看,给定球队的等级分应该由它所战胜和战平的球队的数量以及被战胜或战平的球队的实力共同决定.具体来说,确定球队Z的等级分的依据应为:一是看它战胜和战平了多少支球队;二要看它所战胜或战平球队的等级分的高低.这两条就是我们确定排名的基本原理.在实际中,若出现等级分相同的情况,可以进一步根据净胜球的多少来确定排名.由于表中包含的数据量庞大,我们先在不计平局,只考虑获胜局的情形下计算出各队的等级分,以说明算法原理。然后我们综合考虑获胜局和平局,加权后得到各队的等级分,并据此进行排名。考虑到竞技比赛的结果的不确定性,我们最后建立了等级分的随机冲浪模型,分析表明等级分排名结果具有良好的参数稳定性。
2.2 获取转移概率矩阵
首先利用有向赋权图的权重矩阵来表达出各队之间的胜负关系.用图的顶点表示相应球队,用连接两个顶点的有向边表示两队的比赛结果。同时给边赋权重,表明占胜的次数。所以,可以得到数据表中给出的12支球队所对应的权重矩阵,这是计算转义概率矩阵的必要步骤,这里直接对论文中的截图进行引用:


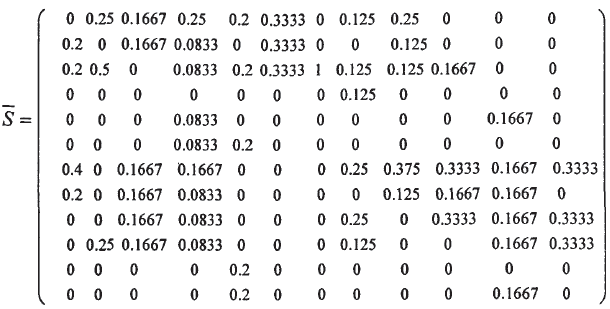

2.3 关于加权等级分
上述权重不够科学,在论文中,作者提出了加权等级分,就是考虑平局的影响,对2个矩阵进行加权得到权重矩阵,从而得到转移概率矩阵。这里由于篇幅比较大,但是思路比较简单,不再详细说明,如果需要详细了解,可以看论文。本文还是集中在C#的实现过程。
2.4 随机冲浪模型

3.C#编程实现过程
下面我们将使用C#实现论文中的上述过程,注意,2.3和2.2的思想是类似的,只不过是多了一个加权的过程,对程序来说还是很简单的。下面还是按照步骤一个一个来,很多人看到问题写程序很难下手,其实习惯就好了,按照算法的步骤来,一个一个实现,总之要先动手,不要老是想,想来想去没有结果,浪费时间。只有实际行动起来,才能知道实际的问题,一个一个解决,持之以恒,思路会越来越清晰。
3.1 计算权重矩阵
权重矩阵要根据测试数据,球队和每2个球队直接的比分来获取,所以我们使用一个字典来存储原始数据,将每个节点,2个队伍的比赛结果比分都写成数组的形式,来根据胜平负的场次计算积分,得到边的权重,看代码吧:
/// <summary>根据比赛成绩,直接根据积分来构造权重矩阵,根据i,对j比赛获取的分数</summary>
/// <param name="data">key为2个对的边名称,value是比分列表,分别为主客进球数</param>
/// <param name="teamInfo">球队的编号列表</param>
/// <returns>权重矩阵</returns>
public static double[,] CalcLevelTotalScore(Dictionary<String, Int32[][]> data, List<Int32> teamInfo)
{
Int32 N = teamInfo.Count;
double[,] result = new double[N, N]; #region 利用对称性,只计算一半
for (int i = ; i < N; i++)
{
for (int j = i + ; j <= N; j++)
{
#region 循环计算
String key = String.Format("{0}-{1}", teamInfo[i - ], teamInfo[j - ]);
//不存在比赛成绩
if (!data.ContainsKey(key))
{
result[i - , j - ] = result[j - , i - ] = ;
continue;
}
//计算i,j直接的互胜场次
var scores = data[key];//i,j直接的比分列表
var Si3 = scores.Where(n => n[] > n[]).ToList();//i胜场次
var S1 = scores.Where(n => n[] == n[]).ToList();//i平场次
var Si0 = scores.Where(n => n[] < n[]).ToList();//i负场次
result[i - , j - ] = Si3.Count* + S1.Count ;
result[j - , i - ] = Si0.Count * + S1.Count ;
#endregion
}
}
#endregion
//按照列向量进行归一化
return GetNormalizedByColumn(result);
}
上面最后返回调用了归一化的函数,比较简单,直接代码贴出来,折叠一下:
/// <summary>按照列向量进行归一化</summary>
/// <param name="data"></param>
/// <returns></returns>
public static double[,] GetNormalizedByColumn(double[,] data)
{
int N = data.GetLength();
double[,] result = new double[N, N];
#region 各个列向量归一化
for (int i = ; i < N; i++) //列
{
double sum = ;
//行
for (int j = ; j < N; j++) sum += data[j, i];
for (int j = ; j < N; j++)
{
if (sum != ) result[j, i] = data[j, i] / (double)sum;//归一化,每列除以和值
else result[j, i] = data[j, i];
}
}
#endregion return result;
}
3.2 计算最大特征值及特征向量
计算特征值和特征向量是一个数学问题,我们采用了Math.NET数学计算组件,可以直接计算很方便。详细的使用可以参考下面代码,组件的其他信息可以参考本站导航栏上的专题目录,有大量的使用文章。看代码吧。
/// <summary>求最大特征值下的特征向量</summary>
/// <param name="data"></param>
/// <returns></returns>
public static double[] GetEigenVectors(double[,] data)
{
var formatProvider = (CultureInfo)CultureInfo.InvariantCulture.Clone();
formatProvider.TextInfo.ListSeparator = " "; int N = data.GetLength();
Matrix<double> A = DenseMatrix.OfArray(data);
var evd = A.Evd();
var vector = evd.EigenVectors;//特征向量
var ev = evd.EigenValues;//特征值,复数形式发 if (ev[].Imaginary > ) throw new Exception("第一个特征值为复数");
//取 vector 第一列为最大特征向量
var result = new double[N];
for (int i = ; i < N; i++)
{
result[i] =Math.Abs(vector[i, ]);//第一列,取绝对值
}
return result;
}
3.3 随机冲浪模型的实现
随机冲浪模型主要是有一个比例,设置之后可以直接求解,也比较简单,函数如下:
/// <summary>获取随机冲浪模型的 转移矩阵:
/// 作用很明显,结果有明显的改善
/// </summary>
/// <returns></returns>
public static double[,] GetRandomModeVector(double[,] data ,double d = 0.35)
{
int N = data.GetLength();
double k = (1.0 - d) / (double)N;
double[,] result = new double[N, N];
for (int i = ; i < N; i++)
{
for (int j = ; j < N; j++) result[i, j] = data[i, j] * d + k;
}
return result;
}
3.4 其他
其他问题就是数据组合的过程,这里太多,不详细讲解。主要是构建测试数据以及排序后结果的处理,很简单。贴一个球队排序的函数,根据特征向量:
/// <summary>排序,输出球队编号</summary>
/// <param name="w"></param>
/// <param name="teamInfo"></param>
/// <returns></returns>
public static Int32[] TeamOrder(double[] w, List<Int32> teamInfo)
{
Dictionary<int, double> dic = new Dictionary<int, double>();
for (int i = ; i <= w.Length; i++) dic.Add(i , w[i-]);
return dic.OrderByDescending(n => n.Value).Select(n => n.Key).ToArray();
}
4.算法测试
我们使用问题1中的数据,进行测试,首先构建测试集合,代码如下,太长,折叠一下,主要是问题1的原始数据:
/// <summary>
/// 获取测试的数据集,key=对1-对2,value = int[,] 为比分
/// </summary>
public static Dictionary<String, Int32[][]> GetTestData()
{
Dictionary<String, Int32[][]> data = new Dictionary<string, int[][]>();
#region 依次添加数据
#region T1
data.Add("1-2", new Int32[][]{ new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("1-3", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("1-4", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("1-5", new Int32[][] { new Int32[] { , } });
data.Add("1-6", new Int32[][] { new Int32[] { , } });
data.Add("1-7", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("1-8", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("1-9", new Int32[][]{ new Int32[] { , }, new Int32[] { , } });
data.Add("1-10", new Int32[][]{ new Int32[] { , }, new Int32[] { , } });
#endregion #region T2
data.Add("2-3", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("2-4", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("2-5", new Int32[][] { new Int32[] { , } });
data.Add("2-6", new Int32[][] { new Int32[] { , } });
data.Add("2-7", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("2-8", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("2-9", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("2-10", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
#endregion #region T3
data.Add("3-4", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("3-5", new Int32[][] { new Int32[] { , } });
data.Add("3-6", new Int32[][] { new Int32[] { , } });
data.Add("3-7", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("3-8", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("3-9", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("3-10", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
#endregion #region T4
data.Add("4-5", new Int32[][] { new Int32[] { , } });
data.Add("4-6", new Int32[][] { new Int32[] { , } });
data.Add("4-7", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("4-8", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("4-9", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("4-10", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
#endregion #region T5
data.Add("5-6", new Int32[][] { new Int32[] { , } });
data.Add("5-11", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
data.Add("5-12", new Int32[][] { new Int32[] { , }, new Int32[] { , } });
#endregion #region T7
data.Add("7-8", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("7-9", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("7-10", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("7-11", new Int32[][] { new Int32[] { , } });
data.Add("7-12", new Int32[][] { new Int32[] { , } });
#endregion #region T8
data.Add("8-9", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("8-10", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("8-11", new Int32[][] { new Int32[] { , } });
data.Add("8-12", new Int32[][] { new Int32[] { , } });
#endregion #region T9
data.Add("9-10", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
data.Add("9-11", new Int32[][] { new Int32[] { , } });
data.Add("9-12", new Int32[][] { new Int32[] { , } });
#endregion #region T10
data.Add("10-11", new Int32[][] { new Int32[] { , } });
data.Add("10-12", new Int32[][] { new Int32[] { , } });
#endregion #region T11
data.Add("11-12", new Int32[][] { new Int32[] { , }, new Int32[] { , }, new Int32[] { , } });
#endregion
#endregion
return data;
}
测试的主要方法是:
var team = new List<Int32>(){,,,,,,,,,,,};
var data = GetTestData();
var k3 = CalcLevelScore3(data,team);
var w3 = GetEigenVectors(k3);
var teamOrder = TeamOrder(w3,team);
Console.WriteLine(teamOrder.ArrayToString());
排序结果如下:
,,,,,,,,,,,
结果和论文差不多,差别在前面2个,队伍7和3的位置有点问题。具体应该是计算精度的关系如果前面的计算有一些精度损失的话,对后面的计算有一点点影响。
PageRank的一个基本应用今天就到此为止,接下来如果大家感兴趣,我将继续介绍PageRank在球队排名和比赛预测结果中的应用情况。看时间安排,大概思路和本文类似,只不过在细节上要处理一下。
【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码的更多相关文章
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- 分布式机器学习:PageRank算法的并行化实现(PySpark)
1. PageRank的两种串行迭代求解算法 我们在博客<数值分析:幂迭代和PageRank算法(Numpy实现)>算法中提到过用幂法求解PageRank. 给定有向图 我们可以写出其马尔 ...
- PageRank算法初探
1. PageRank的由来和发展历史 0x1:源自搜索引擎的需求 Google早已成为全球最成功的互联网搜索引擎,在Google出现之前,曾出现过许多通用或专业领域搜索引擎.Google最终能击败所 ...
- PageRank算法实现
基本原理 在互联网上,如果一个网页被很多其他网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高.这就是PageRank的核心思想. 引用来自<数学之美>的简单例子: 网页Y的排名应该 ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- 张洋:浅析PageRank算法
本文引自http://blog.jobbole.com/23286/ 很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看 ...
- PageRank算法简介及Map-Reduce实现
PageRank对网页排名的算法,曾是Google发家致富的法宝.以前虽然有实验过,但理解还是不透彻,这几天又看了一下,这里总结一下PageRank算法的基本原理. 一.什么是pagerank Pag ...
- 机器学习十大算法之KNN(K最近邻,k-NearestNeighbor)算法
机器学习十大算法之KNN算法 前段时间一直在搞tkinter,机器学习荒废了一阵子.如今想重新写一个,发现遇到不少问题,不过最终还是解决了.希望与大家共同进步. 闲话少说,进入正题. KNN算法也称最 ...
- PageRank算法
PageRank,网页排名,又称网页级别,传说中是PageRank算法拯救了谷歌,它是根据页面之间的超链接计算的技术,作为网页排名的要素之一.它通过网络浩瀚的超链接关系来确定一个页面的等级.Googl ...
随机推荐
- 【ORACLE】MD5加密
今天乌干达充值卡入库时,发现有资源已经存在的异常, 异常原因经过核实是由于卡资源密码在库中已经存在, 为进一步查找存在的原因, 因此需要对导入文件密码的MD5 加密, 通过MD5加密后的字符串 ...
- JS获取当前时间戳的方法
JavaScript 获取当前时间戳:第一种方法: var timestamp = Date.parse(new Date()); 结果:1280977330000第二种方法: var timesta ...
- 关于UIScrollerView的基本用法和代理
- (void)viewDidLoad { [super viewDidLoad]; scrollView = [[UIScrollView alloc] initWithFrame:CGRectM ...
- debian下Apache和tomcat整合(使用apt工具)
最近部署web系统,需要使用tomcat处理和Apache整合使用,tomcat处理JSP,Apache处理静态资源.开始不知道怎么操作,在网上查阅资料走了很多弯路.完成时候,发现其实很简单,现将配置 ...
- RequireJS与SeaJS模块化加载示例
web应用越变的庞大,模块化越显得重要,尤其Nodejs的流行,Javascript不限用于浏览器,还用于后台或其他场景时,没有Class,没有 Package的Javascript语言变得难以管理, ...
- WebService的工作原理
Web Service全称XML Web Service WebService是一种可以接收从Internet或者Intranet上的其它系统中传递过来的请求,轻量级的独立的通讯技术.是:通过SOAP ...
- 配置Spark on YARN集群内存
参考原文:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool 运行文件有几个G大,默 ...
- Java 用程序给出随便大小的10 个数,序号为1-10,按从小到大顺序输出,并输出相应的序号?
import java.util.ArrayList; import java.util.Collections; import java.util.Iterator; import java.uti ...
- Raid 介绍以及软raid的实现
RAID: old Redundant Arrays of Inexpensive Disks (廉价磁盘冗余阵列) new Redundant Arrays of Independent Disks ...
- OUTLOOK 发生错误0x8004010D
问题: outlook 2003 在接收邮件时报错: “正在接收”报告了错误(0x8004010D):“在包含您的数据文件的驱动器上,磁盘空间不足.请清空“已删除邮件”文件夹或删除某些文件以释放 ...