jsoup抓取网页内容
java项目有时候我们需要别人网页上的数据,怎么办?我们可以借助第三方架包jsou来实现,jsoup的中文文档,那怎么具体的实现呢?那就跟我一步一步来吧
最先肯定是要准备好这个第三方架包啦,下载地址,得到这个jar后在需要怎么做呢?别急,我们慢慢来
将jsoup.jar拷贝到项目的WebRoot—>WEB-INF—>lib文件夹
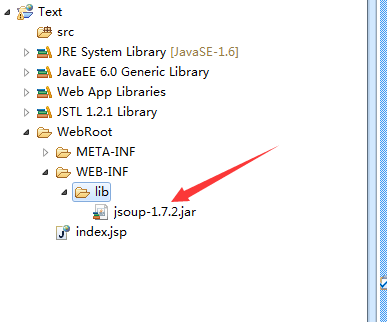 之后我们需要将这个架包引入一下哦!
之后我们需要将这个架包引入一下哦!
右键项目选择build path—>configure build path—>libraries—>add jars—>找到刚刚放入的目录下的jsoup



准备工作完成了,接下来就是我们的编码部分了,加油哦!
既然是抓取网页的内容那肯定首要有被抓的网站的地址,这里就以我其中一篇博客为准吧http://www.cnblogs.com/luhan/p/5953387.html
 这个是我这篇文章的截图,比如我要抓取Android零碎知识点,之后会一直更新哦这一段文字
这个是我这篇文章的截图,比如我要抓取Android零碎知识点,之后会一直更新哦这一段文字
//获取整个网站的根节点,也就是html开头部分一直到结束,这里get方式,post方式是一样的
Document document = Jsoup.connect(url).get();
//输出一下我们会看到整个字符串如下
System.out.println(document);
这里只是截图了一部分

我们会看到我们需要抓的那一段文字在a标签包裹在,而且还有一个重要的就是id=cb_post_title_url,看过文档的应该知道,jsoup里面有getElementById这个方法,其实跟js里面获取元素是一样的,这里我们就可以用
getElementById的方法来获取这个a标签,获取到后我们就可以获取里面的内容了不是吗?而正好jsou也给我们提供了这样的一个方法text()方法,就是获取标签的文本内容,记得是文本而不是html形式的
如下我们通过getElementById这个方法来获取到我们想要的a标签
Element a = document.getElementById("cb_post_title_url");
这时候我们输出的内容如下
System.out.println(a.text());
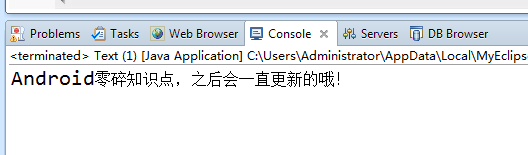
是不是得到了我们想要的了?当然啦,这只是jsoup的最简单的抓取而已,如果需要获取到的是个列表形式的啊,jsoup也一样可以的,我们都知道id是唯一的,不可以重复的,所以我们通过id获取到的只能是一行标签
但是一般列表比如ul-li我们就可以用getElementsByTag这个方法,通过标签名获取,然后再通过for循环的方式一个一个的去抓就完事啦,接下来附上代码
package com.luhan.text; import java.io.IOException; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element; public class Text {
private static final String url = "http://www.cnblogs.com/luhan/p/5953387.html"; public static void main(String[] args) {
try {
//获取整个网站的根节点,也就是html开头部分一直到结束
Document document = Jsoup.connect(url).post();
Element a = document.getElementById("cb_post_title_url");
System.out.println(a.text());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
jsoup里面的方法我就不一一介绍啦,不懂的小伙伴可以去看jsoup的中文文档哦,我就说说比较重要的方法吧
Jsoup.connect(url).post();获取网页的跟目录
getElementById通过id来获取
getElementsByClass通过class来获取
getElementsByTag通过标签名称来获取
text()获取标签的文本,再次强调一下是文本
html()获取标签里面的所有字符串包括html标签
attr(attributeKey)获取属性里面的值,参数是属性名称
注意
jsoup获取网页的根目录可能跟源代码不一样,所以需要小伙伴们细心哦
至此jsoup抓取网页的数据就告一段落啦,说的不太好,欢迎大家多指点,这个我用java控制台的,javaweb以及Android用法是一样的,先要导入框架,然后调用方法就ok了
jsoup抓取网页内容的更多相关文章
- 使用Jsoup函数包抓取网页内容
之前写过一篇用Java抓取网页内容的文章,当时是用url.openStream()函数创建一个流,然后用BufferedReader把这个inputstream读取进来.抓取的结果是一整个字符串.如果 ...
- paip.抓取网页内容--java php python
paip.抓取网页内容--java php python.txt 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog ...
- Asp.Net 之 抓取网页内容
一.获取网页内容——html ASP.NET 中抓取网页内容是非常方便的,而其中更是解决了 ASP 中困扰我们的编码问题. 需要三个类:WebRequest.WebResponse.StreamRea ...
- ASP.NET抓取网页内容的实现方法
这篇文章主要介绍了ASP.NET抓取网页内容的实现方法,涉及使用HttpWebRequest及WebResponse抓取网页内容的技巧,需要的朋友可以参考下 一.ASP.NET 使用HttpWebRe ...
- ASP.NET抓取网页内容
原文:ASP.NET抓取网页内容 一.ASP.NET 使用HttpWebRequest抓取网页内容 这种方式抓取某些页面会失败 不过,有时候我们会发现,这个程序在抓取某些页面时,是获不到所需的内容的, ...
- c#抓取网页内容乱码的解决方案
写过爬虫的同学都知道,这是个很常见的问题了,一般处理思路是: 使用HttpWebRequest发送请求,HttpWebResponse来接收,判断HttpWebResponse中”Content-Ty ...
- C# 抓取网页内容的方法
1.抓取一般内容 需要三个类:WebRequest.WebResponse.StreamReader 所需命名空间:System.Net.System.IO 核心代码: view plaincopy ...
- ASP.NET 抓取网页内容
(转)ASP.NET 抓取网页内容 ASP.NET 抓取网页内容-文字 ASP.NET 中抓取网页内容是非常方便的,而其中更是解决了 ASP 中困扰我们的编码问题. 需要三个类:WebRequest. ...
- 爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容 所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地.我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程 ...
随机推荐
- SQL之经典语句
一.基础 1.说明:创建数据库 CREATE DATABASE database-name 2.说明:删除数据库 drop database dbname 3.说明:备份sql server --- ...
- vmware workstation(mac版)查看vmnet8的网关地址
想为虚拟机配置固定ip,需要设置网关,但是mac版的vmware workstation没有Virtual Network Editor,所以不能直接查看到. 因此执行如下命令进行查找 find / ...
- MIC中示例程序计算π
mic中编程十分简单,只需在普通程序中简单加几句就可以,使用 lspci|grep -i -co-processor 命令可以查看机器中是否插入MIC卡以及MIC卡的数目,MIC编程环境的配置这里就不 ...
- redis php 执行命令时,单引号和双引号的区别。
#今天遇到一个坑爹的问题,写成单引号就不行,被原样输出了. /** *判断key是否存在 */ function exists_key($key){ return $this->cmd('EXI ...
- mybatis介绍安装
MyBatis 是支持定制化 SQL.存储过程以及高级映射的优秀持久层框架.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis 可以对配置和原生Map使用简单 ...
- chef简介
Chef 的简单介绍 Chef 主要分为三个部分 Chef Server.Workstation 以及 Chef Client.用户在 Workstation 上编写 Cookbook.然后,通过 k ...
- 用C#来学习唐诗三百首和全唐诗
Begin 最近把项目做完了,闲来无事,就想做点好玩的事情,刚好前几天下载了[唐诗三百首]和[全唐诗]这两个txt文件,正好用C#来整理一下. 然后导出QData格式,可以给其他软件读取. 以后弄个开 ...
- Centos 安装libreoffice 生成office 报错信息见内容
个人博客:https://blog.sharedata.info/ 错误信息:/opt/libreoffice5.2/program/soffice.bin: error while loading ...
- python字符串基本方法
字符串类型在Python中是十分重要的类型,他一般用引号中间添加字符的形式表达,不同于其他语言的是,Python中双引号(” “)与单引号(’ ‘)是不予区分的.都可以用来表示字符串 创建.赋值和访问 ...
- 【python】-- RabbitMQ Publish\Subscribe(消息发布\订阅)
RabbitMQ RabbitMQ Publish\Subscribe(消息发布\订阅) 1对1的消息发送和接收,即消息只能发送到指定的queue里,但这样使用有些局限性,有些时候你想让你的消息被所有 ...