简单的方法爬取b站dnf视频封面步骤解释
这随笔代码链接:http://www.cnblogs.com/yinghualuowu/p/8186375.html
首先我们要知道,一个分区封面显示到底在哪里可以找到。
很明显,查看审查元素并不能找到封面。这个时候应该想到封面是动态加载的。
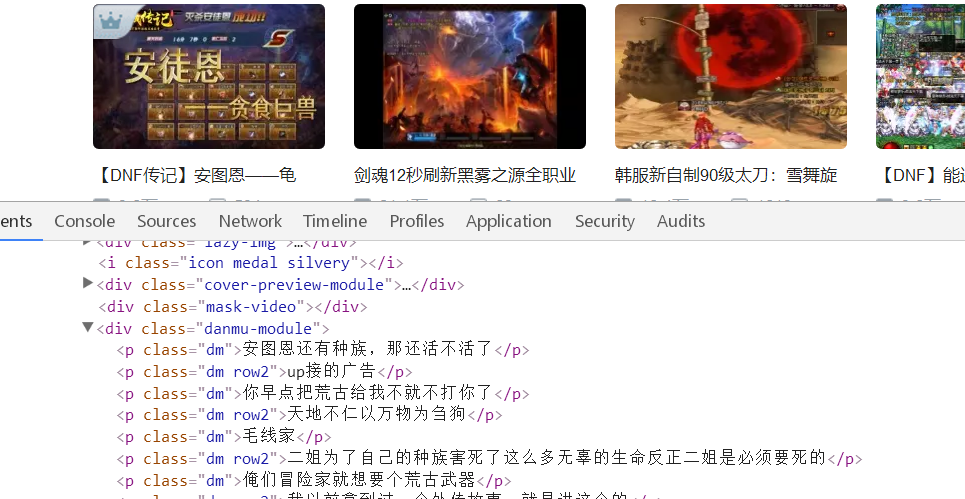
再次去Network寻找,我们发现这样一个JS。这是右侧热门视频封面的内容,点开之后存在pic:正是封面的链接。
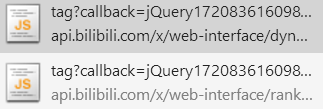

进行json解析之后,判定pic在data>archives结构下。这个时候链接是有了,那么将如何把Json拿出来呢?

让我们观察一下原来的信息,除去JQuery........()这层,里面就是json字符串了,既然如此简单,那么我们就...

查找开头第一个(,然后截取至最后一个),里面不就是了吗?
def instr(keystr):
st=keystr.find('(')+1
strhtml=keystr[st:len(keystr)-1]
return strhtml
def picsave(strJson,number):
global cnt
strdic=strJson['data']['archives']
num=len(strdic)
for i in range(0,num,1):
cnt=cnt+1
strdic=strJson['data']['archives'][i]
print(strdic['pic'])
urllib.request.urlretrieve(strdic['pic'],'E:\图片\dnf\%s.jpg'%(cnt))
然后进行翻页判断,我们尝试点开第一页和后面几页,看看不同。pn数字貌似变化很有规律啊。
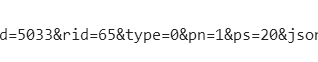
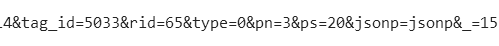
于是...
def urlget(num):
for i in range(1,num,1):
url='https://api.bilibili.com/x/tag/ranking/archives?callback=jQuery172014070206081723846_1514982701564&tag_id=5033&rid=65&type=0&pn='+str(i)+'&ps=20&jsonp=jsonp&_=1514982702144'
response=urllib.request.urlopen(url)
html=response.read().decode('utf-8')
html=instr(html)
strJson=eval(html)
picsave(strJson,i)
然后,就没有了。其实要高清大图的话,你需要点进去一个视频,然后审查元素,后面我会写一个输入av号来获取封面的代码
简单的方法爬取b站dnf视频封面步骤解释的更多相关文章
- Python 简单的方法爬取b站dnf视频封面
import urllib.request cnt=0 def instr(keystr): st=keystr.find('(')+1 strhtml=keystr[st:len(keystr)-1 ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- 爬取b站互动视频信息
首先分辨视频是不是互动视频可以看 https://api.bilibili.com/x/player.so?id=cid:1&aid=89017 这个api返回的xml中的 <inter ...
- Python爬虫一爬取B站小视频源码
如果要爬取多页的话 在最下方循环中 填写好循环的次数就可以了 项目源码 from fake_useragent import UserAgent import requests import time ...
- python爬取b站排行榜视频信息
和上一篇相比,差别不是很大 import xlrd#读取excel import xlwt#写入excel import requests import linecache import wordcl ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- 爬虫之爬取B站视频及破解知乎登录方法(进阶)
今日内容概要 爬虫思路之破解知乎登录 爬虫思路之破解红薯网小说 爬取b站视频 Xpath选择器 MongoDB数据库 爬取b站视频 """ 爬取大的视频网站资源的时候,一 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
随机推荐
- L1-039 古风排版(20 分)
中国的古人写文字,是从右向左竖向排版的.本题就请你编写程序,把一段文字按古风排版. 输入格式: 输入在第一行给出一个正整数N(<100),是每一列的字符数.第二行给出一个长度不超过1000的非空 ...
- Poj 2411 Mondriaan's Dream(压缩矩阵DP)
一.Description Squares and rectangles fascinated the famous Dutch painter Piet Mondriaan. One night, ...
- 关于系统中:/dev/mem
1)参考:https://blog.csdn.net/lsn946803746/article/details/52948036 博主:lsn946803746 2)参考:https://blog ...
- 【转】 Pro Android学习笔记(二九):用户界面和控制(17):include和merge
目录(?)[-] xml控件代码重用include xml控件代码重用merge 横屏和竖屏landsacpe portrait xml控件代码重用:include 如果我们定义一个控件,需要在不同的 ...
- 纯js+html+css实现模拟时钟
前几天没事写的个模拟时钟,代码仅供小白参考,大神请自动绕过. <!DOCTYPE html> <html lang="en"> <head> & ...
- 人物-IT-刘强东:刘强东
ylbtech-人物-IT-刘强东:刘强东 刘强东,男,汉族,1973年3月10日生(另一说法:1974年2月14日),江苏宿迁人,祖籍湖南湘潭 .京东集团董事局主席兼首席执行官,本科毕业于中国人民大 ...
- word2010以上版本中快捷录入数学公式的方法(二)
以前推荐的方法,随着方正飞翔网站上关闭了数学公式输入法的支持也不能不用了,现在再推荐一个可以在word2010以上版中快捷输入数学公式的方法,安装AxMath,一切问题都OK!我是直接购买的正版,25 ...
- java报表开发之报表总述
转自:https://blog.csdn.net/u011659172/article/details/40504271?utm_source=blogxgwz6
- python 字典 get 小例子
语法 get()方法语法: dict.get(key, default=None) 参数 key -- 字典中要查找的键. default -- 如果指定键的值不存在时,返回该默认值值. 返回值 返回 ...
- CSS之边距合并
外边距合并指的是,当两个垂直外边距相遇时,它们将形成一个外边距.合并后的外边距的高度等于两个发生合并的外边距的高度中的较大者. 情况1:当一个元素出现在另一个元素上面时,第一个元素的下外边距与第二个元 ...