【Kaggle】泰坦尼克号
引言
这是泰坦尼克号事件的基本介绍:

我们需要做的就是通过给出的数据集,通过对特征值的分析以及运用机器学习模型,分析什么样的人最可能存活,并给出对测试集合的预测。
对于Kaggle,我认为大体上有这么几个步骤:
- 读取数据 pd.read_csv('文件地址.csv') 读取进来的数据是dataframe的格式
- EDA,也就是对数据信息进行基本的了解,例如有多少的特征值,预测值是什么,是否包含缺失值,哪些数据需要进行处理,要进行哪些处理,哪些数据可以直接被使用。
- 对训练集数据进行数据预处理。 在上一步我们已经有了一个对数据处理方案的初步认识,这一步就是实施数据处理的具体步骤(处理缺失值,类别值)
- 运用机器模型对训练数据集进行训练,得到机器模型
- 对测试数据集进行处理,并套用机器模型,得出预测值
蓝色字体下面的内容代表对上面代码基础知识的补充
EDA: 对数据进行分析
- **导入数据,查看基本信息 **
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
data_train = pd.read_csv('tanic_train.csv')#导入进来的是dataframe格式
#data_train 可以打开data_train的具体信息,是dataframe的格式
#data_train.info() #显示了基本信息的总和,包括有多少行,多少列,每列包含多少的数据,可以看出是否具有缺失值
data_train.describe() #可以得到一些方差均值等统计信息,当然这是针对于数据,对于文本信息这里是没有显示的
#data_train['Sex'].unique()#可以判断出函数值取值范围
#dara_train.head(5) #显示数据集合前五行的内容
结果如下:
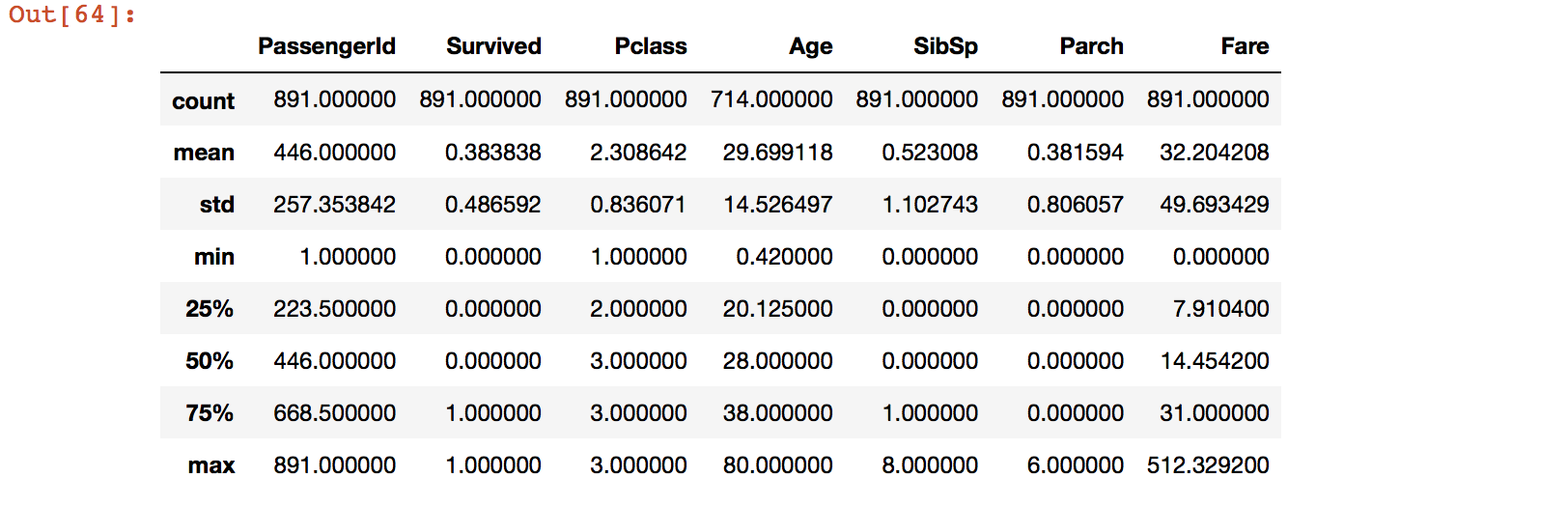
我们在上一步查看基本信息的时候已经发现每个特征值含有的元素数量有不一样的,例如Age只有714个元素,而其他的大部分有891个元素,这说明有缺失值的存在,我们来看一下缺失值的具体信息可以使用如下的方法:
- 查看是否具有缺失值的存在:
data_train.loc[data_train.Age.isnull(),'Age'] #如果没有后面的这个'Age', 会显示数据集合而不是一列
结果如下:

df.loc()
import pandas as pd
data = [[1,2,3],[4,5,6]]
index = [0,1]
columns=['a','b','c']
df = pd.DataFrame(data=data, index=index, columns=columns)
1.1 loc[1] #通过行标签进行索引(当索引是字符时,相应的loc['d'])
df.loc[1]
a 4
b 5
c 6
1.2 loc[0: ] #获取多行数据
a b c
0 1 2 3
1 4 5 6
1.3 loc[[0,1],['a','b']] #获取某几行某几列
a b
0 1 2
1 4 5
1.4 loc[:,'a'] #获取某列
0 1
1 4
- **查看单个特征或者几个特征和结果的关系,可以使用crosstab **
temp = pd.crosstab([data_train.Pclass, data_train.Sex], data_train.Survived.astype(bool),margins=False)
print(temp)
temp.plot(kind='bar', stacked=True, color=['red','blue'], grid=False) #stacked 是判断是否需要堆叠
结果如下:
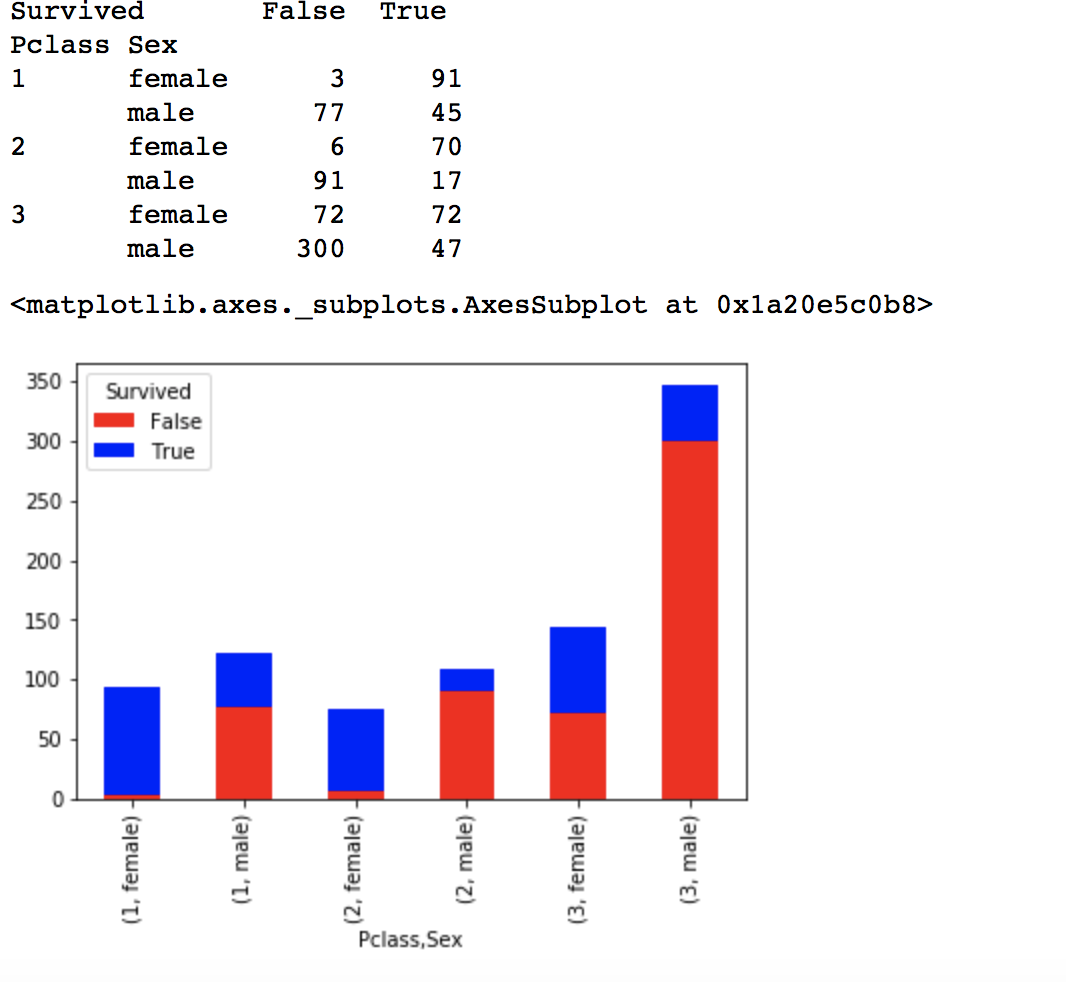
关于crosstab,有一个数据集 data, 内容为如下所示:
Sample Gender Handedness
1 Female Right-handed
2 male Left-handed
3 Female Right-handed
4 male Right-handed
5 male Left-handed
6 male Right-handed
7 Female Right-handed
8 Female Left-handed
9 male Right-handed
10 Female Right-handed
>>>pd.crosstab(data.Gender,data.Handedness,margins=True)#margins的意思是包含不包含All
>>>
Handedness Left-handed Right-handed All
Gender
Female 1 4 5
Male 2 3 5
All 3 7 10
对于crosstab的前两个参数可以输数组,Series或者数组列表。,在比如对小费数据:
>>>pd.crosstab([tips.time,tips.day],tips.smoker,margins=True)
>>>smoker No Yes All
time day
Dinner Fri 3 9 12
Sat 45 42 87
Sun 57 19 76
Thur 1 0 1
Lunch Fri 1 6 7
Thur 44 17 61
All 151 93 244
经过EDA这个过程,我们需要了解每个特征的含义,哪一个特征值是有用的,是需要处理的,需要进行哪些处理。
Data Processing 数据预处理
- 对于缺失值来讲:
如果缺值得样本占总数比例极高,我们可能直接舍弃
如果缺失值所占比例极小, 我们可以直接填入平均值或者众数
如果缺失值所占比例既不大也不小,那么可以考虑它和跟其他腾征之间的关系,运用相应的模型预测,如:随机森林,线性回归
对于年龄缺失值处理比较简单的一种方法就是使用均值或者中位数来填充缺失值,具体代码如下:
data_train['Age']=data_train['Age'].fillna(data_train['Age'].mean()/median())
在这里我们的数据集中,我们采取随机森林的方法:
#把已有的数值型特征取出来形成一个新的数据框
from sklearn.ensemble import RandomForestRegressor
age_df = data_train[['Age','Fare','Parch','SibSp','Pclass']]
#乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix() # 把dataframe转换成数组形式,因为在进行数据训练的时候一定是数组形式的
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
#y 即目标年龄
y = known_age[:,0]
#x即特征属性值
x = known_age[:,1:]
#fit到随机森林回归算法中去
rfr = RandomForestRegressor(random_state = 0,n_estimators = 2000, n_jobs = -1)
rfr.fit(x,y)
#用得到的模型进行位置年龄的结果预测
predictedAges = rfr.predict(unknown_age[:,1:]) #看一下里面是啥
#用得到的预测结果填补原缺失数据
data_train.loc[data_train.Age.isnull(),'Age'] = predictedAges ##去掉括号试试
对类别型数据进行处理,如果取值没有大小的意义,一般使用pandas的”get_dummies”函数,如果取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}.当然如果不采用pandas的”get_dummies”的话,我们也可以认为的规定类别性变量转换之后的数值
import pandas as pd
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
size_mapping = {
'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].map(size_mapping)
class_mapping = {label:idx for idx,label in enumerate(set(df['class label']))}
df['class label'] = df['class label'].map(class_mapping)
pd.get_dummies(df)
结果如下:

正如上面所说,我们也可以使用直接替换的方法(male视为1,female视为2),代码如下:
data_train["Sex"].unique()#看一下取值范围,是否只是拥有男女两种模式
data_train.loc[data_train['Sex'] == 'male','Sex'] = 1
data_train.loc[data_train['Sex'] == 'female','Sex'] = 0
当然对于登船地的缺失值的处理也可以使用其他模型(类似于年龄),例如随机森林,线性回归等。但是因为这里缺失值只有两个,所以对登船的地方(Embarked)进行简单的处理,直接令其为'S'或者也可以众数平均值等,这一列的值有S,C,Q,missing。令 S=0,C=1, Q=2
data_train['Embarked'].unique()
data_train['Embarked'] == data_train['Embarked'].fillna('S')
data_train.loc[data_train["Embarked"] == "S", "Embarked"] = 0
data_train.loc[data_train["Embarked"] == "C", "Embarked"] = 1
data_train.loc[data_train["Embarked"] == "Q", "Embarked"] = 2
接下来我们需要对数据进行标准化处理:
from sklearn import preprocessing
st=np.array(data_train[['Age']])
scaler = preprocessing.StandardScaler().fit(st)
#在fit函数中,如果特征值只是一列的话,一定要注意在从数据集合挑选这一列特征的时候要使用X[['someting']],这样在使用np.array()之后才是可以被使用的
data_train['Age']=scaler.transform(st)
st2=np.array(data_train[['Fare']])
scaler = preprocessing.StandardScaler().fit(st2)
data_train['Fare']=scaler.transform(st2)
机器学习建模
train_np=data_train[['Survived','Age','Fare','Pclass','Parch','Sex','SibSp','Cabin','Embarked']]
# y即Survival结果
y = train_np.loc[:, 'Survived']
# X即特征属性值
X = train_np.loc[:, ['Age','Fare','Pclass','Parch','Sex','SibSp','Cabin','Embarked']]
# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression()
clf.fit(X.values, y.values)
clf
就这样,我们得到了一个模型,结果如下:

将模型用于测试集合
data_test=pd.read_csv('test.csv')
data_test.info()
data_test['Fare']=data_test['Fare'].fillna(data_test['Fare'].median())
data_test.loc[data_test.Cabin.notnull(),'Cabin']=0
data_test.loc[data_test.Cabin.isnull(),'Cabin']=1
data_test.loc[data_test['Sex']=='male','Sex'] = 1
data_test.loc[data_test['Sex']=='female','Sex'] = 0
data_test.loc[data_test["Embarked"] == "S", "Embarked"] = 0
data_test.loc[data_test["Embarked"] == "C", "Embarked"] = 1
data_test.loc[data_test["Embarked"] == "Q", "Embarked"] =2
from sklearn.ensemble import RandomForestRegressor
age_df = data_test[['Age','Fare','Parch','SibSp','Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
#known_age
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
#unknown_age
#y 即目标年龄
y = known_age[:,0]
# x即特征属性值
x = known_age[:,1:]##
#fit到随机森林回归算法中去
rfr = RandomForestRegressor(random_state = 0,n_estimators = 2000, n_jobs = -1)
rfr.fit(x,y)
# 用得到的模型进行位置年龄的结果预测
predictedAges = rfr.predict(unknown_age[:,1::]) #看一下里面是啥
#用得到的预测结果填补原缺失数据
data_test.loc[data_test.Age.isnull(),'Age'] = predictedAges ##去掉括号试试
prediction_test=clf.predict(test_np)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':prediction_test.astype(np.int32)})
result.to_csv('result.csv')
将result.csv 上交到Kaggle,排名如下:
准确率为0.77033, 排名是5964囧
优化
首先我们要考虑在数据集合将其分成训练集合和测试集合
from sklearn import cross_validation
data=data_train[['Age','Survived','Fare','Pclass','Parch','Sex','SibSp','Cabin','Embarked']]
X=np.array(data_train[['Age','Fare','Pclass','Parch','Sex','SibSp','Cabin','Embarked']])
y=np.array(data_train['Survived'])
X_train,X_test,y_train,y_test=cross_validation.train_test_split(X,y,test_size=0.3)
其后我们需要训练模型,并应用在我们自己分成的测试集合中
from sklearn import linear_model
clf = linear_model.LogisticRegression()
clf.fit(X_train, y_train)
clf.score(X_test,y_test)
【Kaggle】泰坦尼克号的更多相关文章
- 数据分析-kaggle泰坦尼克号生存率分析
概述 1912年4月15日,泰坦尼克号在首次航行期间撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难.沉船导致大量伤亡的原因之一是没有足够的救生艇给乘客和船员.虽然幸存下来有一些运气因素,但 ...
- kaggle 泰坦尼克号问题总结
学习了机器学习这么久,第一次真正用机器学习中的方法解决一个实际问题,一步步探索,虽然最后结果不是很准确,仅仅达到了0.78647,但是真是收获很多,为了防止以后我的记忆虫上脑,我决定还是记录下来好了. ...
- 【项目实战】Kaggle泰坦尼克号的幸存者预测
前言 这是学习视频中留下来的一个作业,我决定根据大佬的步骤来一步一步完成整个项目,项目的下载地址如下:https://www.kaggle.com/c/titanic/data 大佬的传送门:http ...
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- 箱线图boxplot
箱线图boxplot--展示数据的分布 图表作用: 1.反映一组数据的分布特征,如:分布是否对称,是否存在离群点 2.对多组数据的分布特征进行比较 3.如果只有一个定量变量,很少用箱线图去看数据的分布 ...
- Kaggle竞赛 —— 泰坦尼克号(Titanic)
完整代码见kaggle kernel 或 NbViewer 比赛页面:https://www.kaggle.com/c/titanic Titanic大概是kaggle上最受欢迎的项目了,有7000多 ...
- kaggle入门--泰坦尼克号之灾(手把手教你)
作者:炼己者 具体操作请看这里-- https://www.jianshu.com/p/e79a8c41cb1a 大家也可以看PDF版,用jupyter notebook写的,视觉效果上感觉会更棒 链 ...
- 数据挖掘竞赛kaggle初战——泰坦尼克号生还预测
1.题目 这道题目的地址在https://www.kaggle.com/c/titanic,题目要求大致是给出一部分泰坦尼克号乘船人员的信息与最后生还情况,利用这些数据,使用机器学习的算法,来分析预测 ...
- 你能在泰坦尼克号上活下来吗?Kaggle的经典挑战
Kaggle Kaggle是一个数据科学家共享数据.交换思想和比赛的平台.人们通常认为Kaggle不适合初学者,或者它学习路线较为坎坷. 没有错.它们确实给那些像你我一样刚刚起步的人带来了挑战.作为一 ...
随机推荐
- intellijidea课程 intellijidea神器使用技巧1-5 idea界面介绍
菜单栏介绍: file:文件操作edit:文本操作view:视图操作navigate:跳转code:源码文件analyze:项目依赖关系分析refactor:代码重构快捷操作,如:抽取函数build: ...
- Android开发从系统图库中选择一张图片的方法
刚开始学习OpenCv4Android编程,做了个小demo. 就是一个主界面上添加一个ImageView 两个Button控件. 一个Button用来从系统相册选择一张照片: 另一个Button是用 ...
- 【FPGA】Quartus导出.qxp格式的网表文件
首先,右击项目顶层文件. 选择Design Partition -> Export Design Partition 即可完成.
- SonarQube代码质量管理平台介绍与搭建
前 言 1.SonarQube的介绍 SonarQube是一个管理代码质量的开放平台. 可以从七个维度检测代码质量(为什么要用SonarQube): (1) 复杂度分布(complexity):代码复 ...
- 将 Azure SQL 内数据下载到本地,满足企业的「数据收集」
嫌长不看版 本文介绍了通过复制和导出两个操作,将 Azure SQL 数据库中的内容转移至其他位置(例如本地环境)的具体做法.借此可以帮助用户在 Azure 中运行数据库的同时,在本地或指定的其他位置 ...
- StringBuffer和StringBuilder区别?
1. String是不可变类,改变String变量中的值,相当于开辟了新的空间存放新的string变量 2. StringBuffer 可变的类,可以通过append方法改变变量的值,且StringB ...
- Visual Studio 编辑器打开项目后,一直提醒Vs在忙,解决方法
今天打开VS2015后,因为这个解决中有很项目,突然就一直现在加载中,点击VS提示在忙,怎么破那?请往下看 第一种方法 1.关闭VS: 2.去C:\Users\<your users name& ...
- 笨办法学Python(三十)
习题 30: Else 和 If 前一习题中你写了一些 “if 语句(if-statements)”,并且试图猜出它们是什么,以及实现的是什么功能.在你继续学习之前,我给你解释一下上一节的加分习题的答 ...
- ubuntu 安装 deb 软件包
参考链接地址 blog.csdn.net/kevinhg/article/details/5934462 sudo dpkg -i xxxx.deb 安装一个 Debian 软件包,如你手动下载的文件
- 【CCPC-Wannafly Winter Camp Day4 (Div1) F】小小马(分类讨论)
点此看题面 大致题意: 给你一张\(n*m\)的棋盘,问你一匹马在两个点中是否存在一条经过黑白格子数目相等的路径. 简化题目 首先,我们来简化一下题目. 考虑到马每次走的时候,所经过的格子的颜色必然发 ...