Lucene打分公式的数学推导
原文出自:http://www.cnblogs.com/forfuture1978/archive/2010/03/07/1680007.html
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下。因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数。
Lucene的打分公式非常复杂,如下:

在推导之前,先逐个介绍每部分的意义:
- t:Term,这里的Term是指包含域信息的Term,也即title:hello和content:hello是不同的Term
- coord(q,d):一次搜索可能包含多个搜索词,而一篇文档中也可能包含多个搜索词,此项表示,当一篇文档中包含的搜索词越多,则此文档则打分越高。
- queryNorm(q):计算每个查询条目的方差和,此值并不影响排序,而仅仅使得不同的query之间的分数可以比较。其公式如下:

- tf(t in d):Term t在文档d中出现的词频
- idf(t):
Term t在几篇文档中出现过(原作者有错,纠正如下:idf为逆文档频率,idf= N(总文档数)/含有t的文档数),idf越大一般说明是公用词语,idf值越小说明是领域词,一般来说更有意义。 - norm(t, d):标准化因子,它包括三个参数:
- Document boost:此值越大,说明此文档越重要。
- Field boost:此域越大,说明此域越重要。
- lengthNorm(field) = (1.0 / Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大。


- 各类Boost值
- t.getBoost():查询语句中每个词的权重,可以在查询中设定某个词更加重要,common^4 hello
- d.getBoost():文档权重,在索引阶段写入nrm文件,表明某些文档比其他文档更重要。
- f.getBoost():域的权重,在索引阶段写入nrm文件,表明某些域比其他的域更重要。
以上在Lucene的文档中已经详细提到,并在很多文章中也被阐述过,如何调整上面的各部分,以影响文档的打分,请参考有关Lucene的问题(4):影响Lucene对文档打分的四种方式一文。
然而上面各部分为什么要这样计算在一起呢?这么复杂的公式是怎么得出来的呢?下面我们来推导。
首先,将以上各部分代入score(q, d)公式,将得到一个非常复杂的公式,让我们忽略所有的boost,因为这些属于人为的调整,也省略coord,这和公式所要表达的原理无关。得到下面的公式:

然后,有Lucene学习总结之一:全文检索的基本原理中的描述我们知道,Lucene的打分机制是采用向量空间模型的:
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。

我们认为两个向量之间的夹角越小,相关性越大。
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
余弦公式如下:

下面我们假设:
查询向量为Vq = <w(t1, q), w(t2, q), ……, w(tn, q)>
文档向量为Vd = <w(t1, d), w(t2, d), ……, w(tn, d)>
向量空间维数为n,是查询语句和文档的并集的长度,当某个Term不在查询语句中出现的时候,w(t, q)为零,当某个Term不在文档中出现的时候,w(t, d)为零。
w代表weight,计算公式一般为tf*idf。
我们首先计算余弦公式的分子部分,也即两个向量的点积:
Vq*Vd = w(t1, q)*w(t1, d) + w(t2, q)*w(t2, d) + …… + w(tn ,q)*w(tn, d)
把w的公式代入,则为
Vq*Vd = tf(t1, q)*idf(t1, q)*tf(t1, d)*idf(t1, d) + tf(t2, q)*idf(t2, q)*tf(t2, d)*idf(t2, d) + …… + tf(tn ,q)*idf(tn, q)*tf(tn, d)*idf(tn, d)
在这里有三点需要指出:
- 由于是点积,则此处的t1, t2, ……, tn只有查询语句和文档的并集有非零值,只在查询语句出现的或只在文档中出现的Term的项的值为零。
- 在查询的时候,很少有人会在查询语句中输入同样的词,因而可以假设tf(t, q)都为1
- idf是指Term在多少篇文档中出现过,其中也包括查询语句这篇小文档,因而idf(t, q)和idf(t, d)其实是一样的,是索引中的文档总数加一,当索引中的文档总数足够大的时候,查询语句这篇小文档可以忽略,因而可以假设idf(t, q) = idf(t, d) = idf(t)
基于上述三点,点积公式为:
Vq*Vd = tf(t1, d) * idf(t1) * idf(t1) + tf(t2, d) * idf(t2) * idf(t2) + …… + tf(tn, d) * idf(tn) * idf(tn)
所以余弦公式变为:

下面要推导的就是查询语句的长度了。
由上面的讨论,查询语句中tf都为1,idf都忽略查询语句这篇小文档,得到如下公式
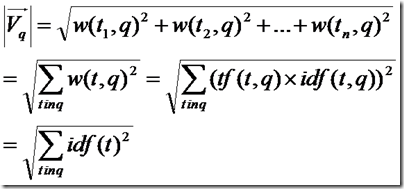
所以余弦公式变为:

下面推导的就是文档的长度了,本来文档长度的公式应该如下:

这里需要讨论的是,为什么在打分过程中,需要除以文档的长度呢?
因为在索引中,不同的文档长度不一样,很显然,对于任意一个term,在长的文档中的tf要大的多,因而分数也越高,这样对小的文档不公平,举一个极端的例子,在一篇1000万个词的鸿篇巨著中,"lucene"这个词出现了11次,而在一篇12个词的短小文档中,"lucene"这个词出现了10次,如果不考虑长度在内,当然鸿篇巨著应该分数更高,然而显然这篇小文档才是真正关注"lucene"的。
然而如果按照标准的余弦计算公式,完全消除文档长度的影响,则又对长文档不公平(毕竟它是包含了更多的信息),偏向于首先返回短小的文档的,这样在实际应用中使得搜索结果很难看。
所以在Lucene中,Similarity的lengthNorm接口是开放出来,用户可以根据自己应用的需要,改写lengthNorm的计算公式。比如我想做一个经济学论文的搜索系统,经过一定时间的调研,发现大多数的经济学论文的长度在8000到10000词,因而lengthNorm的公式应该是一个倒抛物线型的,8000到 10000词的论文分数最高,更短或更长的分数都应该偏低,方能够返回给用户最好的数据。
在默认状况下,Lucene采用DefaultSimilarity,认为在计算文档的向量长度的时候,每个Term的权重就不再考虑在内了,而是全部为一。
而从Term的定义我们可以知道,Term是包含域信息的,也即title:hello和content:hello是不同的Term,也即一个Term只可能在文档中的一个域中出现。
所以文档长度的公式为:

代入余弦公式:
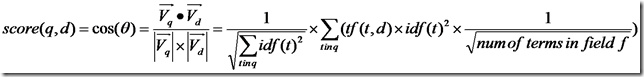
再加上各种boost和coord,则可得出Lucene的打分计算公式。
Lucene打分公式的数学推导的更多相关文章
- Lucene学习总结之六:Lucene打分公式的数学推导
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下.因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数. Lucene ...
- Lucene学习总结之六:Lucene打分公式的数学推导 2014-06-25 14:20 384人阅读 评论(0) 收藏
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下.因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数. Lucene ...
- 关于不同进制数之间转换的数学推导【Written By KillerLegend】
关于不同进制数之间转换的数学推导 涉及范围:正整数范围内二进制(Binary),八进制(Octonary),十进制(Decimal),十六进制(hexadecimal)之间的转换 数的进制有多种,比如 ...
- Lucene打分规则与Similarity模块详解
搜索排序结果的控制 Lucnen作为搜索引擎中,应用最为广泛和成功的开源框架,它对搜索结果的排序,有一套十分完整的机制来控制:但我们控制搜索结果排序的目的永远只有一个,那就是信息过滤,让用户快速,准确 ...
- [ An Ac a Day ^_^ ] hdu 4565 数学推导+矩阵快速幂
从今天开始就有各站网络赛了 今天是ccpc全国赛的网络赛 希望一切顺利 可以去一次吉大 希望还能去一次大连 题意: 很明确是让你求Sn=[a+sqrt(b)^n]%m 思路: 一开始以为是水题 暴力了 ...
- 『sumdiv 数学推导 分治』
sumdiv(POJ 1845) Description 给定两个自然数A和B,S为A^B的所有正整数约数和,编程输出S mod 9901的结果. Input Format 只有一行,两个用空格隔开的 ...
- [hdu5307] He is Flying [FFT+数学推导]
题面 传送门 思路 看到这道题,我的第一想法是前缀和瞎搞,说不定能$O\left(n\right)$? 事实证明我的确是瞎扯...... 题目中的提示 这道题的数据中告诉了我们: $sum\left( ...
- 借One-Class-SVM回顾SMO在SVM中的数学推导--记录毕业论文5
上篇记录了一些决策树算法,这篇是借OC-SVM填回SMO在SVM中的数学推导这个坑. 参考文献: http://research.microsoft.com/pubs/69644/tr-98-14.p ...
- UVA - 10014 - Simple calculations (经典的数学推导题!!)
UVA - 10014 Simple calculations Time Limit: 3000MS Memory Limit: Unknown 64bit IO Format: %lld & ...
随机推荐
- 实现继承+接口继承+虚方法+隐藏方法+this/base+抽象类+密封类/方法+修饰符
概念: 在上一节课中学习了如何定义类,用类当做模板来声明我们的数据. 很多类中有相似的数据,比如在一个游戏中,有Boss类,小怪类Enemy,这些类他们有很多相同的属性,也有不同的,这个时候我们可以使 ...
- ControlTemplate,ItemsPanelTemplate,DataTemplate(wpf)
在WPF中有三大模板ControlTemplate,ItemsPanelTemplate,DataTemplate.其中ControlTemplate和ItemsPanelTemplate是控件模板, ...
- 条款44:将与参数无关的代码剥离template
使用template时,不小心的时候可能就会带来代码膨胀的问题: template<typename T, std::size_t n> class SquareMatrix{ publi ...
- fastadmin学习文档
https://doc.fastadmin.net/docs/index.html 介绍 FastAdmin是一款基于ThinkPHP5+Bootstrap的极速后台开发框架. 主要特性 基于Auth ...
- (转)关于Linux核心转储文件 core dump
所谓核心转储文件是内含进程终止时内存映像的一个文件.产生条件:特定的信号会引发进程创建一个核心转储文件并终止运行. 包括哪些特定信号,请参见http://man7.org/linux/man-page ...
- 如何用windbg分析内存泄露
1. 必须在命令行中设置为要分析的进程打开用户堆栈信息:C:\Program Files\Debugging Tools for Windows (x64)>gflags.exe -i ...
- POJ3641(快速幂)
Pseudoprime numbers Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8529 Accepted: 35 ...
- RCE、exp、Exploit、Exploit Pack、exp-gui、Payload、MetaSploit都是啥
对于走在安全路上的小菜来说,这几个exp.Exploit.Exploit Pack.exp-gui.Payload.MetaSploit名词着实把人转的不轻,下面给大家解释下: RCE,remote ...
- nc之一:NetCat简介与使用方法
精品学习网考试频道小编应广大考生的需要,特为参加考试的考生策划了“NetCat简介与使用方法”专题等有关资料,供考生参考! 在入侵中它是最经典的工具之一 ,NetCat被所有的网络安全爱好者和研究者称 ...
- HAproxy+Mycat
haproxy+mycat搭建haproxy server 10.0.1.134mycat server 10.0.1.134,10.0.1.135mysql master 10.0.1.134mys ...