分布式一致性算法之Paxos原理剖析
概述
Zookeeper集群中,只有一个节点是leader节点,其它节点都是follower节点(实际上还有observer节点,不参与选举投票,在这里我们先忽略,下同)。所有更新操作,必须经过leader节点,leader节点和follower节点之间保持着数据同步和心跳。
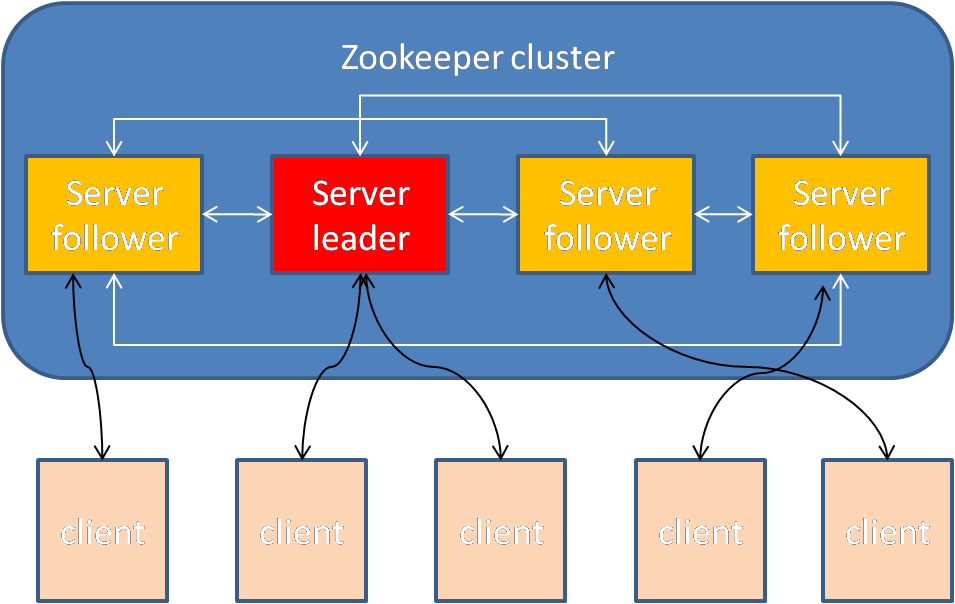
客户端使用zookeeper时,可能会连到follower身份的server上,也可能会连到leader身份的server上。
三类角色分工如下:
Leader:处理写请求,单点
Follower:处理客户端请求,参与投票
Observer:不参与leader选举投票,只处理客户端请求
在一个zookeeper集群里,有多少个server是固定的,每个节点有一个唯一id,标识它自己,另外,每个server还有用于选举的IP和port,这些都在配置文件中。一个具体的例子如下:
server.1= server1的IP地址:2888:3888
server.2= server2的IP地址:2888:3888
server.2= server3的IP地址:2888:3888
这里有3个server,其id分别为1、2、3。2888为节点和leader交换信息的端口,3888为选举端口。这个节点的id,在投票时,用户标识参加竞选的节点的身份。
问题:这个leader节点是怎么确定的?
答案:zookeeper系统自己选举出来的,所有server节点(observer除外),都参与这个选举。这样做的好处是:当现在leader挂掉了之后,系统可以重新选举一个节点做leader。
Zookeeper的选举算法能保证:只要超过半数节点还活着,就一定能选举出唯一个一个节点作为leader。
选举发生时机
当任何一个节点进入looking状态时,选举开始,进入looking状态有如下原因:
1、节点刚启动,使自己进入选举状态
2、发现leader节点挂掉了
Zookeeper中的leader怎么知道follower还活着?follower怎么知道leader还活着?leader会定时向follower发ping消息;follower会定时向leader发ping消息。当发现无法ping通leader时,就会将自己的状态改为LOOKING,并发起新一轮选举。处于选举模式时,zookeeper服务不可用。
一个节点成为leader条件
一个节点要成为leader,必须得到至少n/2+1(即半数以上节点)投票,实际上,在实现时,还可以考虑其它规则,比如节点权重。
为什么要保证至少n/2+1的节点同意?因为这样能保证本节点得到多数派的支持。因为每一个节点,只能支持一个节点成为leader,因此,只要一个节点获得至少n/2+1选票,就一定会比其它任何节点得到的选票多。
这个规则意味着,如果超过半数以上的节点挂掉,zookeeper是选举不出leader节点的,因此,zookeeper集群最多允许n/2节点故障。
要解决的问题
选举算法目标是确保一定要选出一个唯一的leader节点。这有两层含义:
1、一定要选出一个节点作为leader
2、这个leader一定要唯一
为此,要解决如下问题:
1、在一次选举中,节点应该把票投给谁?
规则:每个节点有一个唯一id,在选举中,节点总是把票投给id最大的那个节点,这样,id大的节点更有可能成为leader,天生就是做领导的料。
2、在一次选举过程中,有些节点由于没有启动而没参加(有些人去国外了,没有赶上这次大选,当他回国后,进入looking状态,要发起选举,怎么办?),后来这个节点启动了,此时要求选举,怎么解决?
3、运行过程中,leader节点挂掉了,怎么办?
此时其它节点会发现leader挂了,会发起新一轮选举,最后选出新leader。
尝试解决方案
1、直接指定一个节点做leader,例如,永远都让id最大节点当leader,这个想法最简单。问题:这个节点挂了怎么办?这会出现单点问题。
2、每次选举中,让活着节点中,id最大节点当leader。问题:1、其它节点怎么知道活着节点中,谁id最大?
选举算法流程
选举开始时,每个节点为自己生成一张投票,推荐自己成为leader,并把投票发送给其它节点,这相当于paxos算法中的proposer角色。接下来,节点启动一个接收线程接收其它节点发送过来的投票,并对选票进行处理,这相当于paxos中的acceptor角色。简单说,节点之间通过这种消息发送(投票),最终选举出leader。
当收到其他它节点的选票之后,会和自己的投票比较,如果比自己的投票好(比如推荐的leader的id更大,选举轮数更新),则更新自己的选票,接下来把收到的选票放在选票列表里(该列表存储了所有节点的投票,是一个key-value结构,key为节点的id,value为该节点的投票)。并再次把自己的投票发送给其它节点。
接下来节点会统计选票列表中每个节点获得的票数,如果有一个节点获得超过半数的选票,则认为该节点是leader。如果本节点就是,则将自身的状态置为leading,表明自己是leader;否则将自己的状态置为following,表明自己是follower。
通过若干轮的消息交换,最终,会有一个节点获得超过一半的选票而成为leader。这种方法的精髓在于,每个节点在不需要获得所有节点的信息(投票结果)的前提下,达成一致意见,选出leader。
算法中涉及的重要变量
logicalclock
volatile long logicalclock;
表示选举轮数,在lookForLeader开始的时候会加1,,另外,在收到其他节点的投票信息时,如果其它节点的electionEpoch比本值大,本值会被赋成electionEpoch。也就是说,每次节点启动时,该值为0?这个值只在节点存活的时候有意义?即节点重启后,该值为0。
ProposedLeader
long proposedLeader;
该值为本节点推荐的leader的id,初始时为自己,后面会更新,这个值不会从文件中读,也就是说,重启后会自动使用本节点id。getInitId源代码如下:
public long getId() {
return myid;
}
ProposedZxid
long proposedZxid;
本节点建议的zxid,在starter函数中,被初始化为-1;在updateProposal函数中,会更新该变量的值。
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
private long getInitLastLoggedZxid(){
if(self.getLearnerType() == LearnerType.PARTICIPANT)
return self.getLastLoggedZxid();
else return Long.MIN_VALUE;
}
public long getLastLoggedZxid() {
if (!zkDb.isInitialized()) {
loadDataBase();
}
return zkDb.getDataTreeLastProcessedZxid();
}
ProposedEpoch
long proposedEpoch;
表示本节点推荐的选举轮数,在updateProposal函数更新选票时,会更新该值。节点启动初始化时候,第一次调用updateProposal,会把proposedEpoch的值赋为getPeerEpoch,而该函数又会调用getCurrentEpoch,getCurrentEpoch的代码如下:
public long getCurrentEpoch() throws IOException {
if (currentEpoch == -1) {
currentEpoch = readLongFromFile(CURRENT_EPOCH_FILENAME);
}
return currentEpoch;
}
这表明,该值会从日志文件中读出来。也就是说,节点重启后,会使用上次活着的时候的值。
为什么有了zxid还需要epoch?zxid是用来表示数据的新旧,而epoch是用来表示选举的轮数。
运行实例
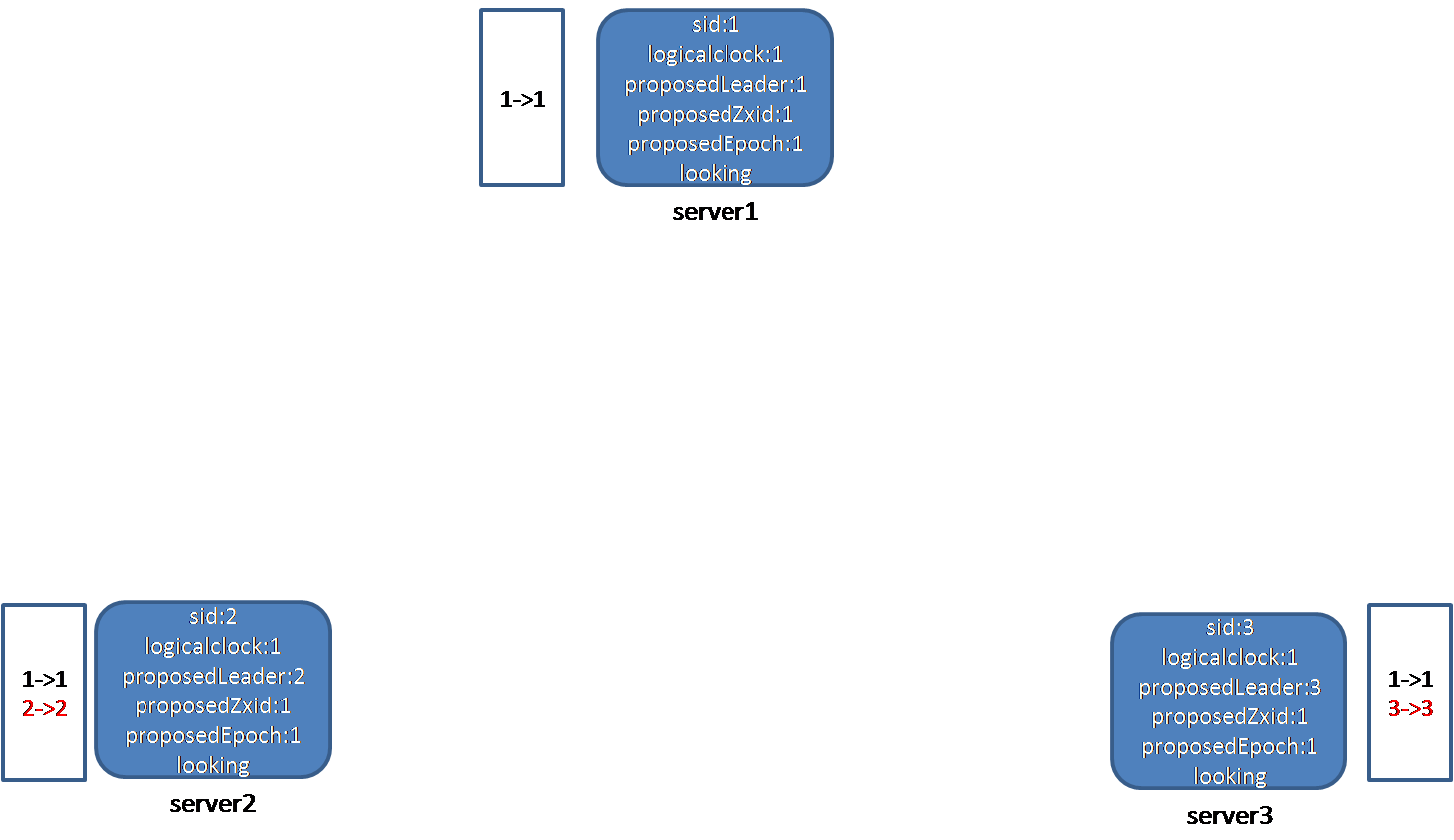
节点1、2、3启动后,都进入looking状态,开始leader选举。每个节点的proposedLeader即推荐的leader都是自己;logicalclock值都为1;建议的proposedZxid值都为1;建议的proposedEpoch值都为1;投票列表为每个节点投自己的一票(1->1,2->2,3->3)。节点1首先向2、3发送自己的投票消息:

节点2、3收到节点1的投票消息,首先查看1的状态,发现1处于looking状态。接下来,判断1发来的electionEpoch和本地逻辑时钟logicalclock的大小,发现两者相等(都为1)。接着判断leader、zxid、peerEpoch和本地proposedLeader、proposedZxid、proposedEpoch的大小,节点2发现节点1推荐的leader的id比自己小(1<2),节点3也发现节点1推荐的leader的id比自己的小(1<3),因此不用更新自己的投票。接下来,节点2、3把节点1的投票放入自己的投票列表中,这样,节点2收到的投票的列表为:
1->1
2->2
节点3的为:
1->1
3->3
节点2、3再判断此次投票是否可以结束,发现不能结束。如下图所示:
节点2向节点1、3发送自己的投票信息,节点3由于发送线程的故障原因,投票信息一直没有出去:
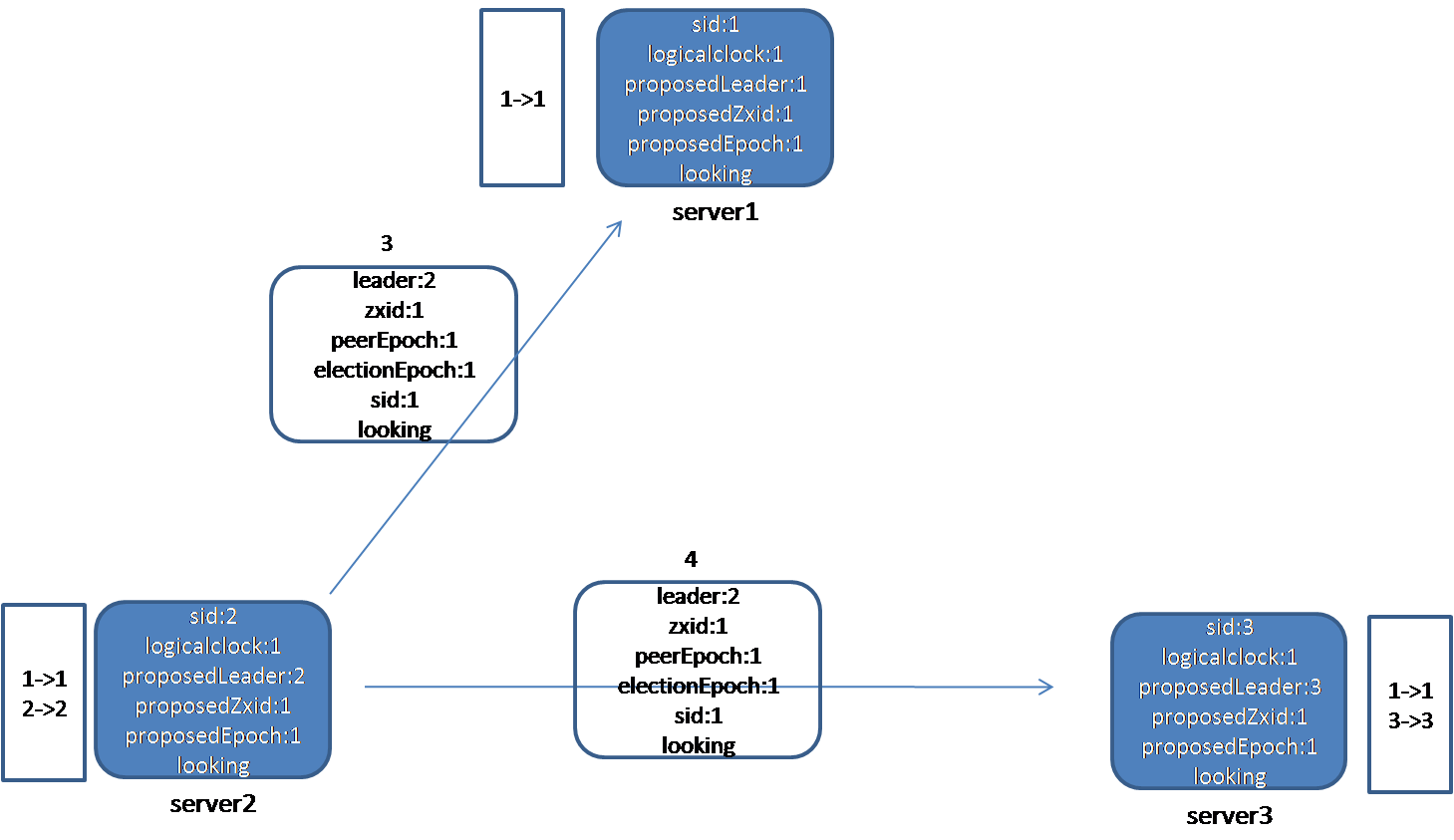
在2发出的投票信息中,选择的leader是它自己。
节点1、3收到节点2的投票消息。节点1比较自己的logcalclock和节点2发来的electionEpoch的大小,二者相等,接下来比较leader、zxid、peerEpoch和本地proposedLeader、proposedZxid、proposedEpoch的大小,发现节点2推荐的leader的id(2)比自己的proposedLeader(1)大,于是更新自己的选票,将proposedLeader改为2。然后,节点1将2的选票(2->2)放入自己收到的投票箱中,接着判断投票是否可以结束(调用函数termPredicate),由于节点2被超过半数的节点选择(1、2),因此选举可以结束,由于自己不是leader,节点1将自己的状态改为following。
节点3比较自己的logcalclock和节点2发来的electionEpoch的大小,二者相等,接下来比较leader、zxid、peerEpoch和本地proposedLeader、proposedZxid、proposedEpoch的大小,发现节点2推荐的leader的id(2)比自己的proposedLeader(3)小,不用更新自己的选票。然后,节点3将2的选票(2->2)放入自己收到的投票箱中,接着判断投票是否可以结束(调用函数termPredicate),由于没有节点获得超过半数的选票,因此选举继续。
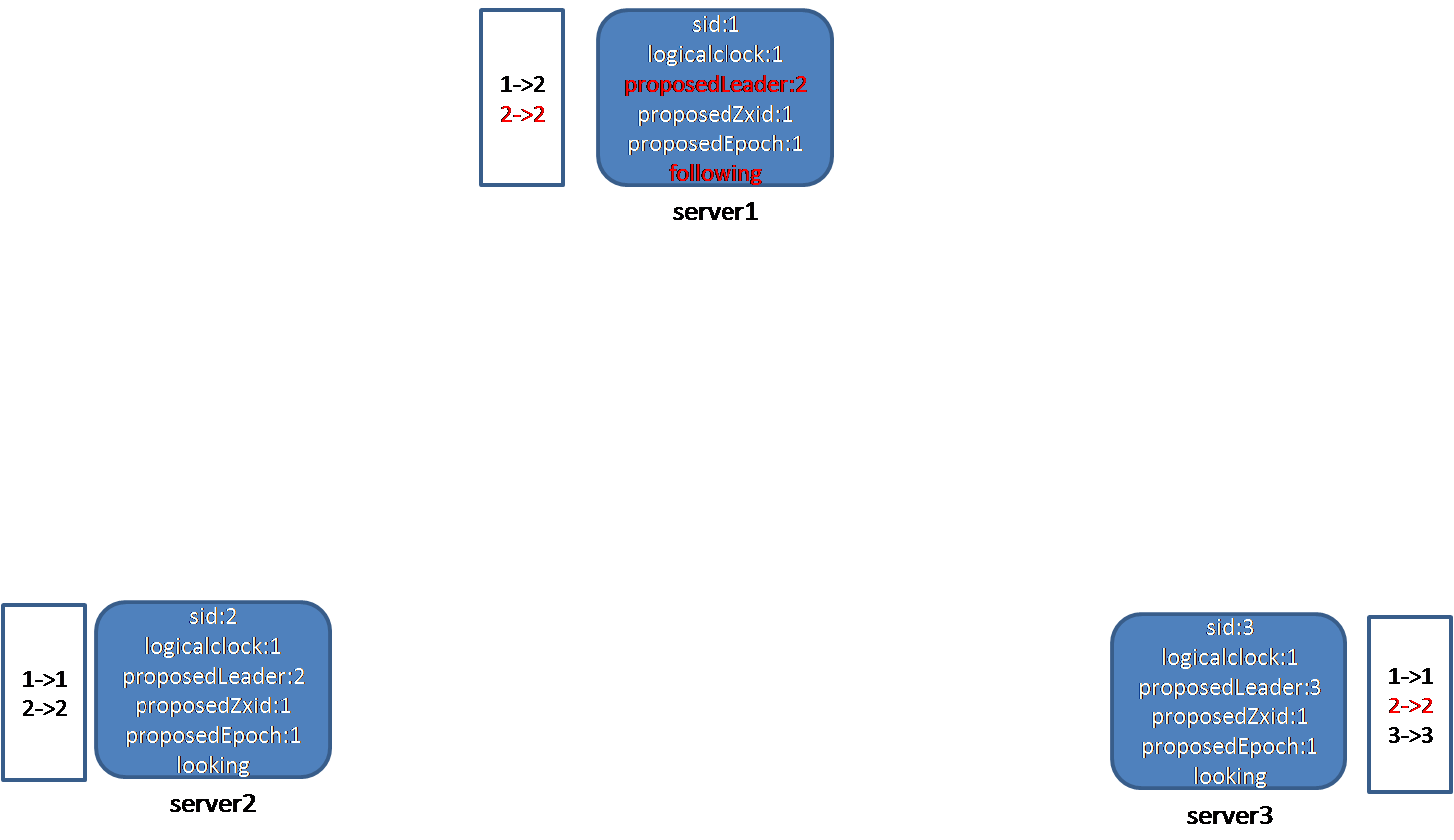
节点1收到节点2的选票,更新选票后,再向节点1、3发送自己的投票信息:此时,节点1选的leader已经变为2,而且节点1的状态已经变成following。
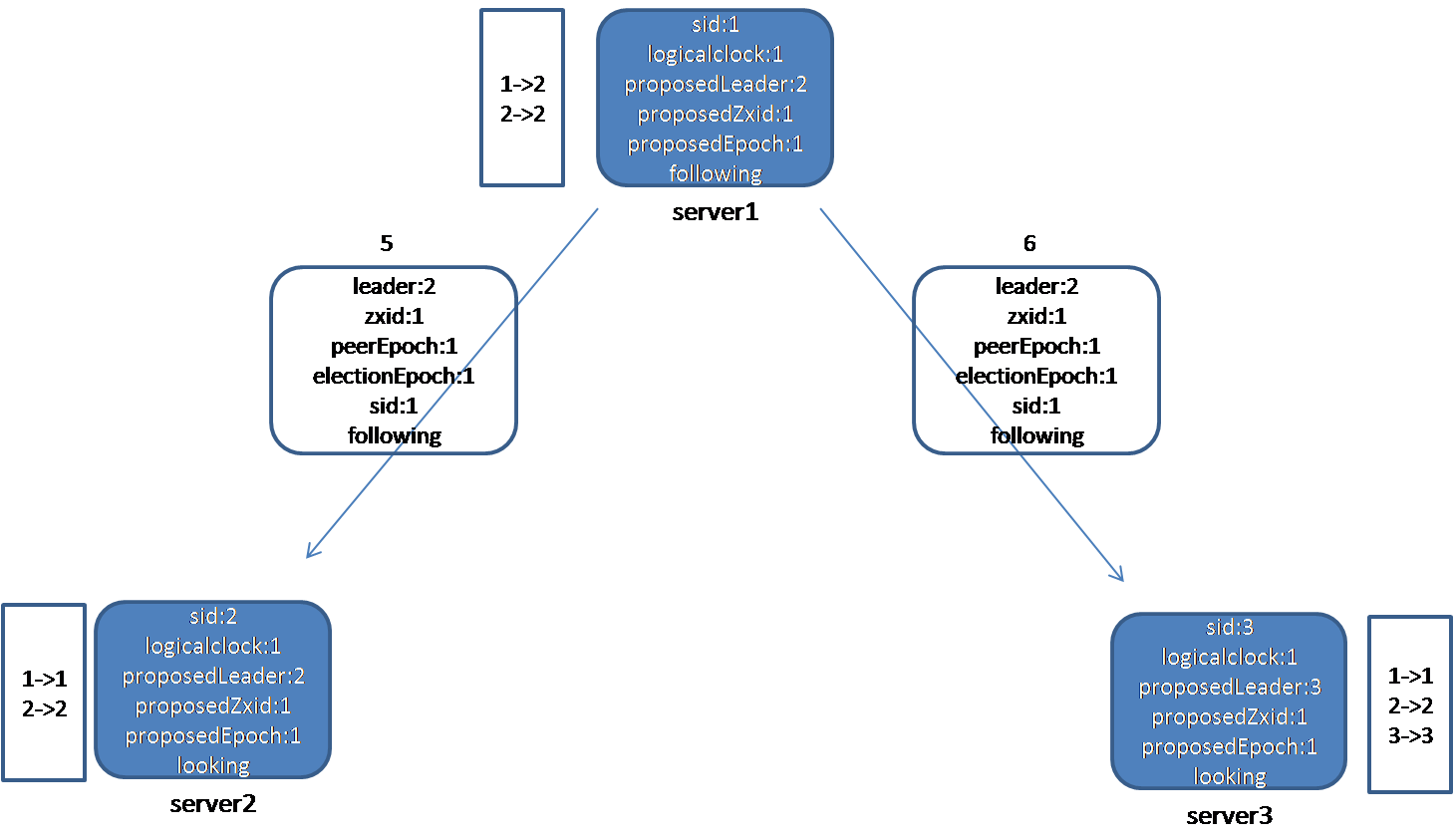
节点2在收到节点1的选票信息后,判断节点1的状态,发现为following,这表明,节点1已经认为leader选出来了,并且是2。节点2首先更新自己的收票箱,将1的投票改为2,接着,判断选举是否结束,发现确实可以结束,节点2就更新自己的状态,由于发现自己是被半数以上人推荐的leader,因此把自己的状态改为leading。同样,节点3在收到节点1的投票信息后,判断节点1的状态,发现为following,这表明,节点1已经认为leader选出来了,并且是2。节点3首先更新自己的收票箱,将1的投票改为2,接着,判断选举是否结束,发现确实可以结束,节点3就更新自己的状态,由于发现自己不是被半数以上人推荐的leader,因此把自己的状态改为following。至此,选举结束,选出来的leader为2,1、3都为follower。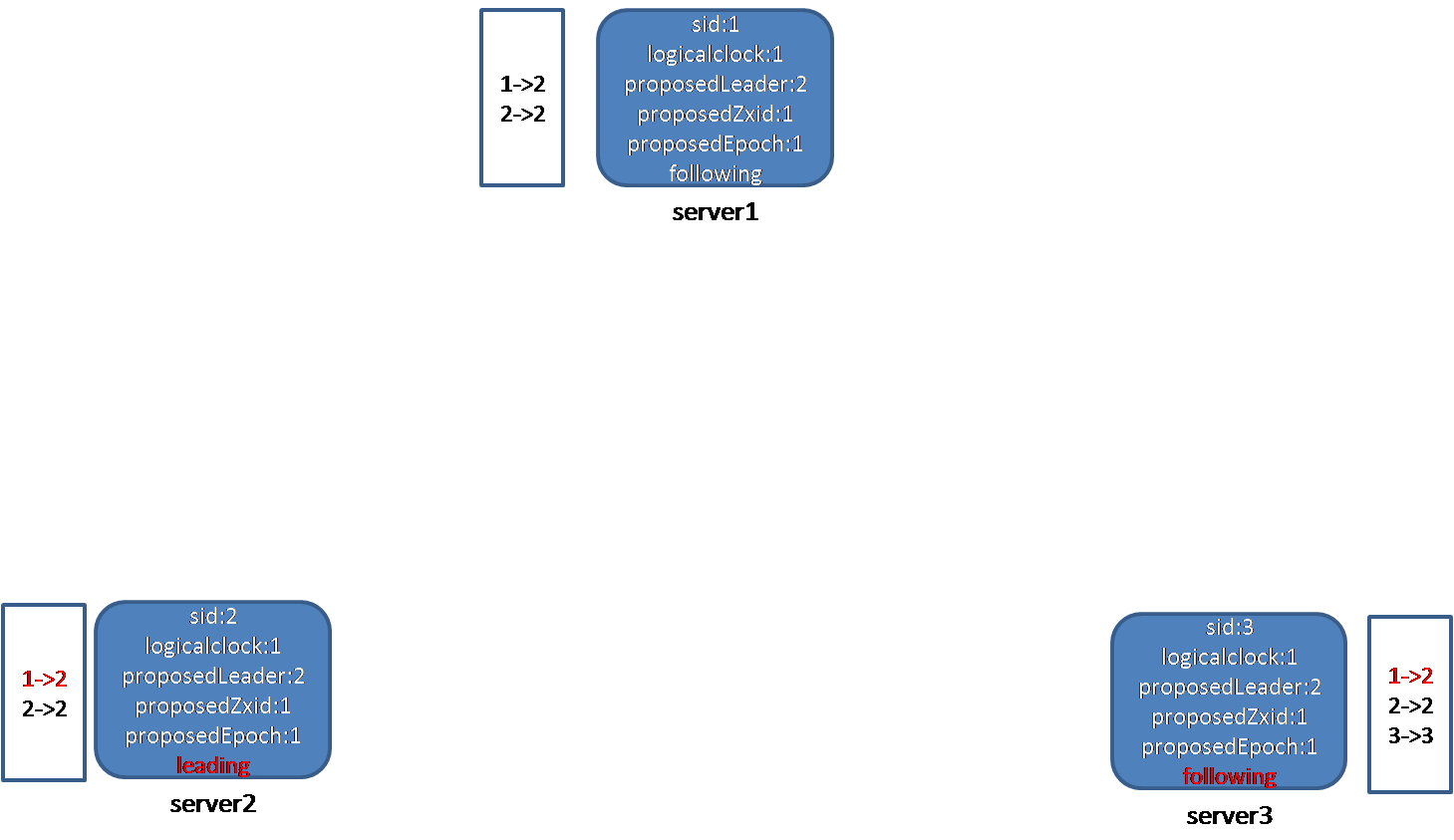
分布式一致性算法之Paxos原理剖析的更多相关文章
- 搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法
搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法 2PC 由于BASE理论需要在一致性和可用性方面做出权衡,因此涌现了很多关于一致性的算法和协议.其中比较著名的有二阶提交协议(2 Phas ...
- 分布式一致性算法--Paxos
Paxos算法是莱斯利·兰伯特(Leslie Lamport)1990年提出的一种基于消息传递的一致性算法.Paxos算法解决的问题是一个分布式系统如何就某个值(决议)达成一致.在工程实践意义上来说, ...
- 分布式一致性的基石---Paxos算法(1)
分布式一致性的基石---Paxos算法(1) Paxos算法是由微软的工程师Lamport提出,Lamport依靠Paxos算法获得图灵奖: Paxos算法旨在解决相互信任的分布式系统中,多个节点能快 ...
- 分布式一致性算法——paxos
一.什么是paxos算法 Paxos 算法是分布式一致性算法用来解决一个分布式系统如何就某个值(决议)达成一致的问题. 人们在理解paxos算法是会遇到一些困境,那么接下来,我们带着以下几个问题来学习 ...
- 分布式一致性算法 2PC 3PC Paxos
分布式一致性算法的目的是为了解决分布式系统 一致性算法可以通过共享内存(需要锁)或者消息传递实现,本文讨论后者实现的一致性算法,不仅仅是分布式系统中,凡是多个过程需要达成某种一致的场合都可以使用. 本 ...
- 分布式一致性算法:Raft 算法(论文翻译)
Raft 算法是可以用来替代 Paxos 算法的分布式一致性算法,而且 raft 算法比 Paxos 算法更易懂且更容易实现.本文对 raft 论文进行翻译,希望能有助于读者更方便地理解 raft 的 ...
- 【转】分布式一致性算法:Raft 算法(Raft 论文翻译)
编者按:这篇文章来自简书的一个位博主Jeffbond,读了好几遍,翻译的质量比较高,原文链接:分布式一致性算法:Raft 算法(Raft 论文翻译),版权一切归原译者. 同时,第6部分的集群成员变更读 ...
- 分布式共识算法 (二) Paxos算法
系列目录 分布式共识算法 (一) 背景 分布式共识算法 (二) Paxos算法 分布式共识算法 (三) Raft算法 分布式共识算法 (四) BTF算法 一.背景 1.1 命名 Paxos,最早是Le ...
- 分布式一致性算法2PC和3PC
为了解决分布式一致性问题,产生了不少经典的分布式一致性算法,本文将介绍其中的2PC和3PC.2PC即Two-Phase Commit,译为二阶段提交协议.3PC即Three-Phase Commit, ...
随机推荐
- java.lang.IllegalStateException: Circular dependencies cannot exist in RelativeLayout
<TextView android:layout_width="fill_parent" android:layout_height="wrap_content&q ...
- hadoop核心逻辑shuffle代码分析-map端 (转)
一直对书和各种介绍不太满意, 终于看到一篇比较好的了,迅速转载. 首先要推荐一下:http://www.alidata.org/archives/1470 阿里的大牛在上面的文章中比较详细的介绍了sh ...
- Java 加密PDF设置密码并添加水印
/** * Project Name:XXX * File Name:EncryptLogFile.java * Date:2016-6-12上午11:56:38 * Copyright (c) 20 ...
- ListItem Updating事件监视有没有上传附件
using System; using System.Collections.Generic; using System.Text; using Microsoft.SharePoint; using ...
- 兼容性良好的 sticky-footer 布局
<div class="content"> <div class="content-wrapper"> <div class=&q ...
- js动画之requestAnimationFrame
1.setTimeout和setInterval 在讲setTimeout和setInterval之前,先讲一下异步执行的运行机制.(同步执行也是如此,因为它可以被视为没有异步任务的异步执行.) (1 ...
- 涉及JSP、Servlet的页面编码问题
1. JSP页面中,二处的字符编码有何区别 1.<%@ page contentType="text/html;charset=UTF-8" %> 是服务器端java程 ...
- chromium之revocable_store
// |RevocableStore| is a container of items that can be removed from the store. Revoke: 撤销 Revocable ...
- (九)Pycharm异常、模块
异常: 当Python检测到一个错误时,解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的"异常" 捕获异常: 格式:try+执行代码······ ...
- intellij IEDA 从svn拉环境到正常运行
intellij IEDA 从svn拉环境到正常运行 1.svn拉项目 在项目选择界面点击Check out from Version Control 从中选择Subversion(SVN) 2.选 ...