python2.7 内置ConfigParser支持Unicode读写
1 python编码基础
对应 C/C++ 的 char 和 wchar_t, Python 也有两种字符串类型,str 与 unicode:
# -*- coding: utf-8 -*-
# file: example1.py
import string # 这个是 str 的字符串
s = '关关雎鸠' # 这个是 unicode 的字符串
u = u'关关雎鸠' print isinstance(s, str) # True
print isinstance(u, unicode) # True print s.__class__ # <type 'str'>
print u.__class__ # <type 'unicode'>stryu
前面的申明:# -*- coding: utf-8 -*- 表明,上面的 Python 代码由 utf-8 编码。
两个 Python 字符串类型间可以用 encode / decode 方法转换:
# 从 str 转换成 unicode
print s.decode('utf-8') # 关关雎鸠 # 从 unicode 转换成 str
print u.encode('utf-8') # 关关雎鸠
encode/decode转换
为什么从 unicode 转 str 是 encode,而反过来叫 decode?
因为 Python 认为 16 位的 unicode 才是字符的唯一内码,而大家常用的字符集如 gb2312,gb18030/gbk,utf-8,以及 ascii 都是字符的二进制(字节)编码形式。把字符从 unicode 转换成二进制编码,当然是要 encode。
反过来,在 Python 中出现的 str 都是用字符集编码的 ansi 字符串。Python 本身并不知道 str 的编码,需要由开发者指定正确的字符集 decode。
(补充一句,其实 Python 是可以知道 str 编码的。因为我们在代码前面申明了 # -*- coding: utf-8 -*-,这表明代码中的 str 都是用 utf-8 编码的,我不知道 Python 为什么不这样做。)
如果用错误的字符集来 encode/decode 会怎样?
# 用 ascii 编码含中文的 unicode 字符串
u.encode('ascii') # 错误,因为中文无法用 ascii 字符集编码
# UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-3: ordinal not in range(128) # 用 gbk 编码含中文的 unicode 字符串
u.encode('gbk') # 正确,因为 '关关雎鸠' 可以用中文 gbk 字符集表示
# '\xb9\xd8\xb9\xd8\xf6\xc2\xf0\xaf'
# 直接 print 上面的 str 会显示乱码,修改环境变量为 zh_CN.GBK 可以看到结果是对的 # 用 ascii 解码 utf-8 字符串
s.decode('ascii') # 错误,中文 utf-8 字符无法用 ascii 解码
# UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128) # 用 gbk 解码 utf-8 字符串
s.decode('gbk') # 不出错,但是用 gbk 解码 utf-8 字符流的结果,显然只是乱码
# u'\u934f\u51b2\u53e7\u95c6\u5ea8\设定
为什么 Python 这么容易出现字符串编/解码异常?
这要提到处理 Python 编码时容易遇到的两个陷阱。第一个是有关字符串连接的:
# -*- coding: utf-8 -*-
# file: example2.py # 这个是 str 的字符串
s = '关关雎鸠' # 这个是 unicode 的字符串
u = u'关关雎鸠' s + u # 失败,UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128)
字符串连接
简单的字符串连接也会出现解码错误?
陷阱一:在进行同时包含 str 与 unicode 的运算时,Python 一律都把 str 转换成 unicode 再运算,当然,运算结果也都是 unicode。
由于 Python 事先并不知道 str 的编码,它只能使用 sys.getdefaultencoding() 编码去 decode。在我的印象里,sys.getdefaultencoding() 的值总是 'ascii' ——显然,如果需要转换的 str 有中文,一定会出现错误。
除了字符串连接,% 运算的结果也是一样的:
# 正确,所有的字符串都是 str, 不需要 decode
"中文:%s" % s # 中文:关关雎鸠 # 失败,相当于运行:"中文:%s".decode('ascii') % u
"中文:%s" % u # UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128) # 正确,所有字符串都是 unicode, 不需要 decode
u"中文:%s" % u # 中文:关关雎鸠 # 失败,相当于运行:u"中文:%s" % s.decode('ascii')
u"中文:%s" % s # UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128)
%运算
其实,sys.getdefaultencoding() 的值是可以用“后门”方式修改的,我不是特别推荐这个解决方案,但是还是贴一下,因为后面有用:
# -*- coding: utf-8 -*-
# file: example3.py
import sys # 这个是 str 的字符串
s = '关关雎鸠' # 这个是 unicode 的字符串
u = u'关关雎鸠' # 使得 sys.getdefaultencoding() 的值为 'utf-8'
reload(sys) # reload 才能调用 setdefaultencoding 方法
sys.setdefaultencoding('utf-8') # 设置 'utf-8' # 没问题
s + u # u'\u5173\u5173\u96ce\u9e20\u5173\u5173\u96ce\u9e20' # 同样没问题
"中文:%s" % u # u'\u4e2d\u6587\uff1a\u5173\u5173\u96ce\u9e20' # 还是没问题
u"中文:%s" % s # u'\u4e2d\u6587\uff1a\u5173\u5173\u96ce\u9e20'
setdefaultencoding
可以看到,问题魔术般的解决了。但是注意! sys.setdefaultencoding() 的效果是全局的,如果你的代码由几个不同编码的 Python 文件组成,用这种方法只是按下了葫芦浮起了瓢,让问题变得复杂。
另一个陷阱是有关标准输出的。(另一个陷阱跟本文章关系不大,请参考这一节的原文:http://in355hz.iteye.com/blog/1860787)
2 python读写ini配置文件
以上介绍了基础python编解码知识,下面具体说明ConfigParser如果管理ini配置文件
配置文件编码为UTF-8,内容如下:
[section]
option=中文字符串
cfg.ini
可以通过Notepad++来查看cfg.ini文件的编码方式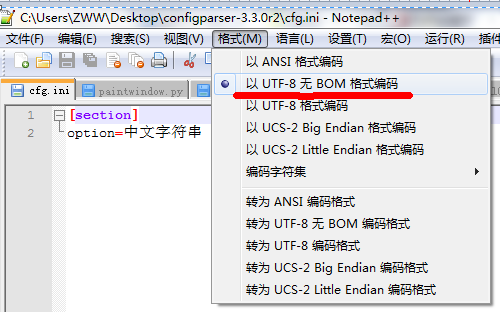
ConfigParser可以方便的读取ini配置文件,但是当重新写入时会遇到问题
import codecs
import ConfigParser cfgfile="cfg.ini" config = ConfigParser.ConfigParser()
config.readfp(codecs.open(cfgfile, "r", "utf-8"))
value = config.get("section","option")
#config.write(open("cfg2.ini", "w+"))
config.write(codecs.open("cfg2.ini", "w+", "utf-8"))
write error
跟踪了一下,在ConfigParser模块的如下位置出现问题:
具体来说是str(value)出错了,因为在例子中的value值为“中文字符串”这已经超出ascii编码的处理范围,我的解决方法是重新实现写入操作,请参考代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
#-------------------------------------------------------------------------------
# Name:
# Purpose:
#
# Author: ZWW
#
# Created: 19/01/2014
# Copyright: (c) ZWW 2014
# Licence: <your licence>
#-------------------------------------------------------------------------------
import codecs
import ConfigParser
import types
import sys cfgfile="cfg.ini" def ini_set(sec,key,value):
try:
config.readfp(codecs.open(cfgfile, "r", "utf-8"))
if not config.has_section(sec):
temp = config.add_section(sec)
config.set(sec, key, value)
except Exception as e:
print("error",str(e))
file = codecs.open(cfgfile, "w", "utf-8")
sections=config.sections()
for section in sections:
#print section
file.write("[%s]\n" % section)
for (key, value) in config.items(section):
if key == "__name__":
continue
if type(value) in (type(u'') , type('')):
file.write(key+"="+value)
elif type(value) == type(1):
optStr="%s=%d"%(key,value)
file.write(optStr)
elif type(value) == type(1.5):
optStr="%s=%f"%(key,value)
file.write(optStr)
else:
print "do not support this type"
print value
file.write("\n")
file.close() if __name__=="__main__":
config = ConfigParser.ConfigParser()
config.readfp(codecs.open(cfgfile, "r", "utf-8"))
value = config.get("section","option")
#config.write(open("cfg2.ini", "w+"))
#config.write(codecs.open("cfg2.ini", "w+", "utf-8"))
print value str='中文'
print str
print type(str)
print repr(str) utf8str = str.decode('utf-8')
print utf8str
print type(utf8str)
print repr(utf8str) ini_set("section","option",utf8str)
test.py
执行完程序后输出如下:
1 >>>
2 中文字符串
3 涓枃
4 <type 'str'>
5 '\xe4\xb8\xad\xe6\x96\x87'
6 中文
7 <type 'unicode'>
8 u'\u4e2d\u6587'
9 >>>
output of test.py
Output of test.py
新的cfg.ini内容如下: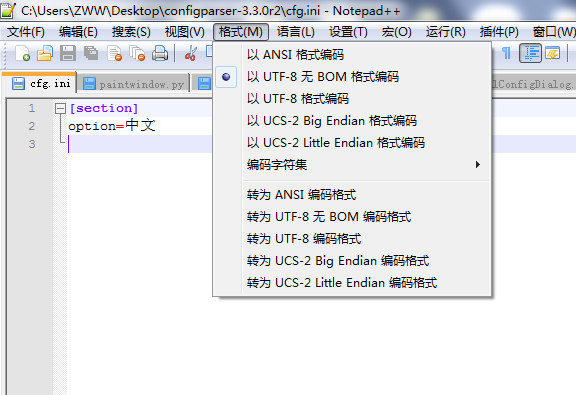
python2.7 内置ConfigParser支持Unicode读写的更多相关文章
- 018-019 NET5_内置容器支持依赖注入+IServiceCollection的生命周期
概念: DI依赖注入: IServiceCollection仅支持构造函数注入 什么是依赖注入? 如果对象A依赖对象B,对象B依赖对象C,就可以先构造对象C,然后传递给对象B,再把对象B传递给A.得到 ...
- Apache Spark 3.0 将内置支持 GPU 调度
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU.FPGA 或 TPU 来加速计算.在 Apache Hadoop 3.1 版本里面 ...
- AngularJS提供的内置过滤器
1. currencycurrecy过滤器可以将一个数值格式化为货币格式.用{{ 123 | currency }}来将123转化成货币格式.currecy过滤器允许我们自己设置货币符号.默认情况下会 ...
- Unity3d shader内置矩阵
内置矩阵 支持的矩阵(float4x4):UNITY_MATRIX_MVP 当前模型视图投影矩阵UNITY_MATRIX_MV 当前模型视图矩阵UNITY_MATRI ...
- python学习交流 - 内置函数使用方法和应用举例
内置函数 python提供了68个内置函数,在使用过程中用户不再需要定义函数来实现内置函数支持的功能.更重要的是内置函数的算法是经过python作者优化的,并且部分是使用c语言实现,通常来说使用内置函 ...
- SpringMVC内置的精准数据绑定2
https://blog.csdn.net/flashflight/article/details/42935137 之前写过一篇<扩展SpringMVC以支持更精准的数据绑定1>用于完成 ...
- ipython, 一个 python 的交互式 shell,比默认的python shell 好用得多,支持变量自动补全,自动缩进,支持 bash shell 命令,内置了许多很有用的功能和函数
一个 python 的交互式 shell,比默认的python shell 好用得多,支持变量自动补全,自动缩进,支持 bash shell 命令,内置了许多很有用的功能和函数. 若用的是fish s ...
- Python内置的urllib模块不支持https协议的解决办法
Django站点使用django_cas接入SSO(单点登录系统),配置完成后登录,抛出“urlopen error unknown url type: https”异常.寻根朔源发现是python内 ...
- (实用)CentOS 6.3更新内置Python2.6
在安装Kilo版的OpenStack时,我们发现社区已经将Python升到2.7,而CentOS 6.3上仍然在使用2.6版的Python.本文记录将CentOS 6.3内置的Python2.6更新为 ...
随机推荐
- Matlab数值计算示例: 牛顿插值法、LU分解法、拉格朗日插值法、牛顿插值法
本文源于一次课题作业,部分自己写的,部分借用了网上的demo 牛顿迭代法(1) x=1:0.01:2; y=x.^3-x.^2+sin(x)-1; plot(x,y,'linewidth',2);gr ...
- JS判断鼠标进入容器方向的方法和分析window.open新窗口被拦截的问题
1.鼠标进入容器方向的判定 判断鼠标从哪个方向进入元素容器是一个经常碰到的问题,如何来判断呢?首先想到的是:获取鼠标的位置,然后经过一大堆的if..else逻辑来确定.这样的做法比较繁琐,下面介绍两种 ...
- 多线程爬坑之路-Thread和Runable源码解析
多线程:(百度百科借一波定义) 多线程(英语:multithreading),是指从软件或者硬件上实现多个线程并发执行的技术.具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提 ...
- 自己实现简单Spring Ioc
IoC则是一种 软件设计模式,简单来说Spring通过工厂+反射来实现IoC. 原理简单说明: 其实就是通过解析xml文件,通过反射创建出我们所需要的bean,再将这些bean挨个放到集合中,然后对外 ...
- oracle 误删数据恢复
1.根据时间点查系统版本号scn: select timestamp_to_scn(to_timestamp('2013-01-07 11:20:00','YYYY-MM-DD HH:MI:SS')) ...
- Jquery 获得当前标签的名称和标签属性
得到标签的名称 $("#name").prop("tagName"); 或者 $("#name")[0].tagName; 注意:1.得到的 ...
- centos7 安装时候检测不到空余硬盘的解决办法
我是用U盘装的centos,在进行硬盘规划时,看到硬盘的可用空间太少 这是因为我的硬盘以前装的是windows系统,硬盘几乎都已经被windows 操作系统给使用了,剩余空间也只会是windows用剩 ...
- Bluemix中国版体验(二)
从上一篇到现在大概有一个多月了.时隔一个月再登录中国版Bluemix,发现界面竟然更新了,现在的风格和国际版已经基本保持一致!这次我们来体验一下Mobile Service.不过mobile serv ...
- NYOJ 455
1.应该交代清楚,参加宴会的人不知道一共有多少顶帽子.假如知道有n顶帽子的话,第一次开灯看见有n-1只,自然就知道自己是第n顶黑帽子,所以应该是这n个人在第一次关灯就打自己脸,不过这么一来就没意思了, ...
- Java中的进程和线程
Java中的进程与线程 一:进程与线程 概述:几乎任何的操作系统都支持运行多个任务,通常一个任务就是一个程序,而一个程序就是一个进程.当一个进程运行时,内部可能包括多个顺序执行流,每个顺序执行流就是 ...