【大数据-课程】高途-天翼云侯圣文-Day3-实时计算原理解析
〇、老师及课程介绍
一、今日内容

二、实时计算理论解析
1、什么是实时计算

微批处理、流式处理、实时计算
水流和车流的例子
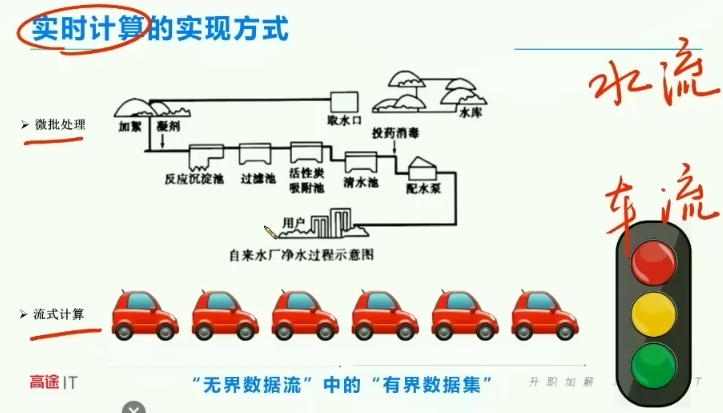
spark streaming就是一种微批处理,水满了才处理,进入下一个地方
流式计算:没有等待
深入:红绿灯交替的场景是微批处理,就不是流式计算了
水流的场景是流式计算时:直饮机,自来水直接可以饮用,出水的过程没有停一停等一等
其他:水流、视频流、
2、数据处理的四大概念
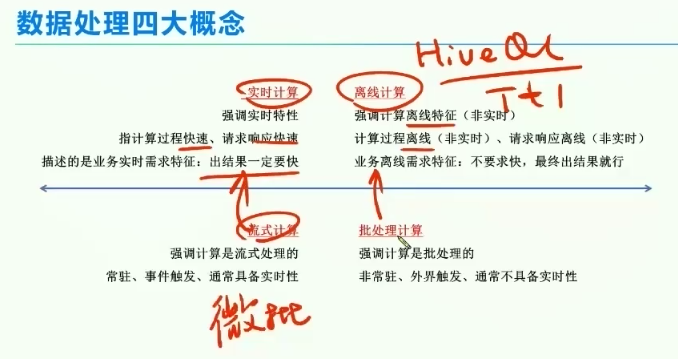
实时:微批处理或流式处理,20%,要求高,trouble shooting比较难
离线:80%的工作量
3、实时处理的价值
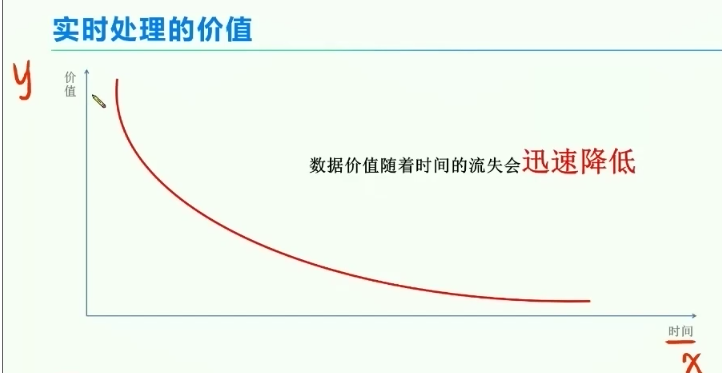
例如:送餐
4、应用场景:风控、欺诈、反欺诈

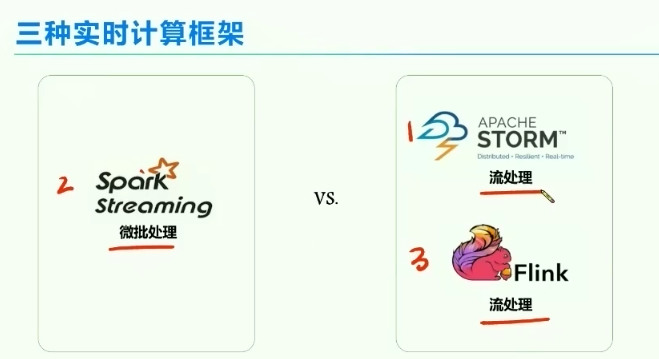
三、批处理框架比较
1、三种框架
2、storm发展历程
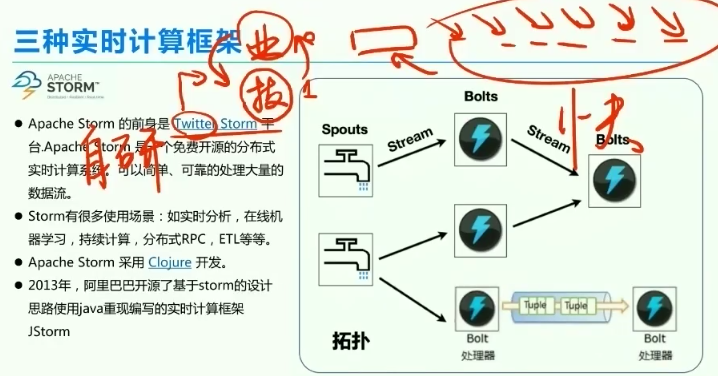
storm基于推特的storm自研产生
不流行的原因:开发语言不常用,准确性低,吞吐能力
阿里基于java重现,开发了jstorm
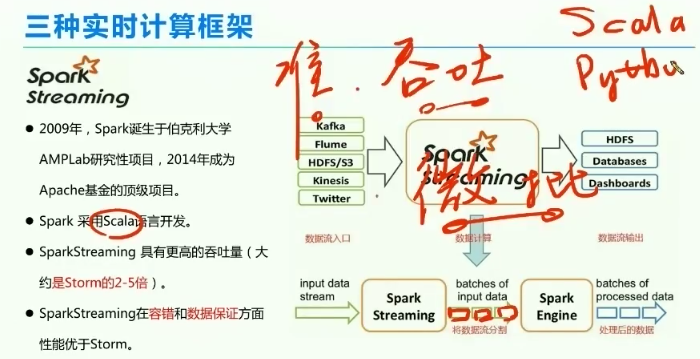
3、Spark Streaming的发展历程
为了解决准确性问题,以及吞吐量提升的问题
由流处理,转为微批处理语言
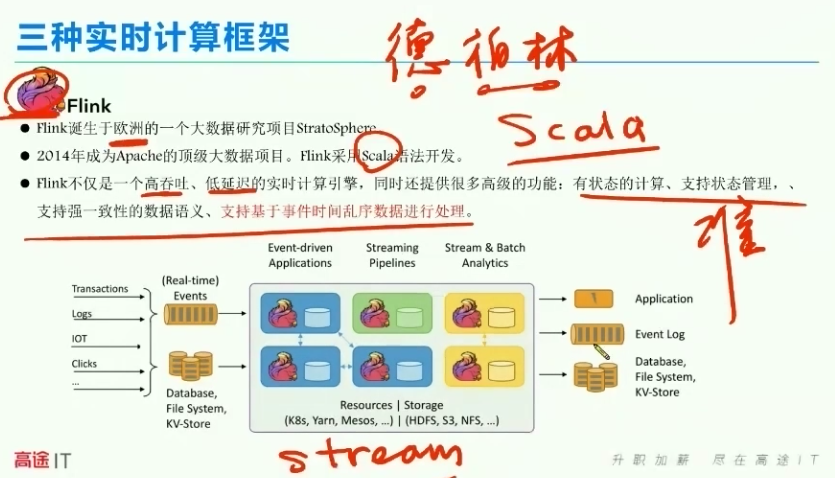
4、flink的发展历程
欧洲,德国柏林的小松鼠
5、性能对比

四、Flink介绍
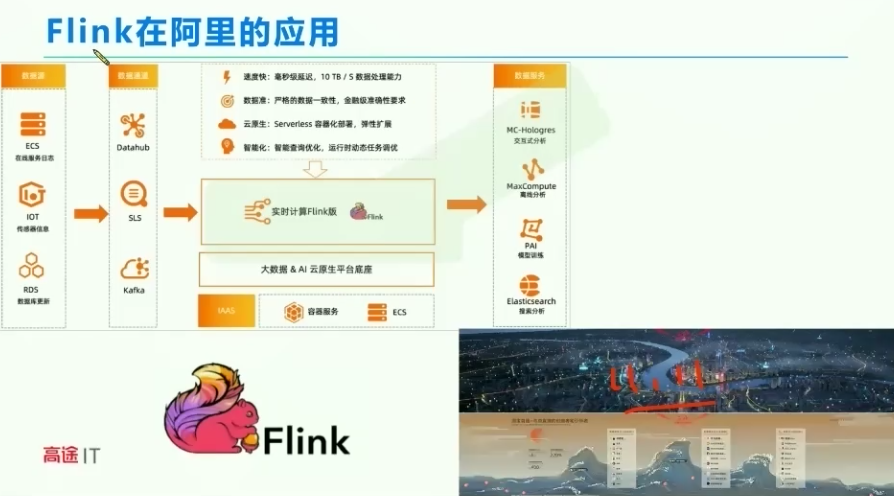
1、flink在阿里的应用
2、技术栈
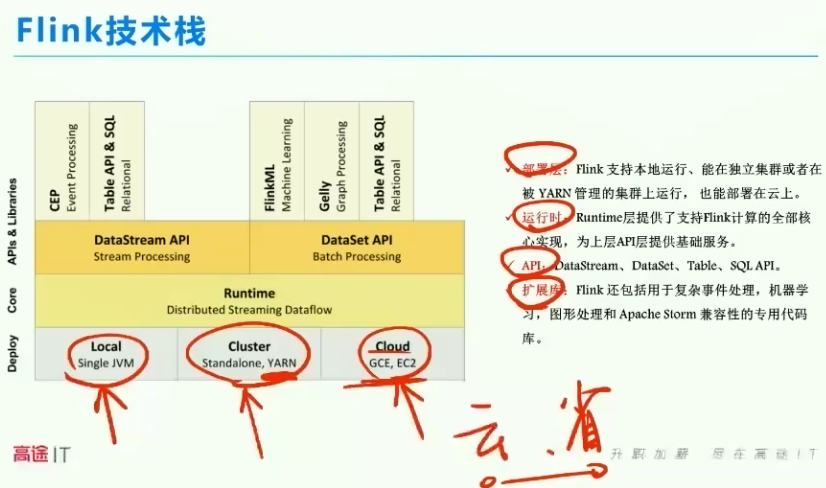
云计算节省成本,例如喝牛奶
流批一体,可以实现流处理,也可以实现批处理
3、适用于所有人的编程模型
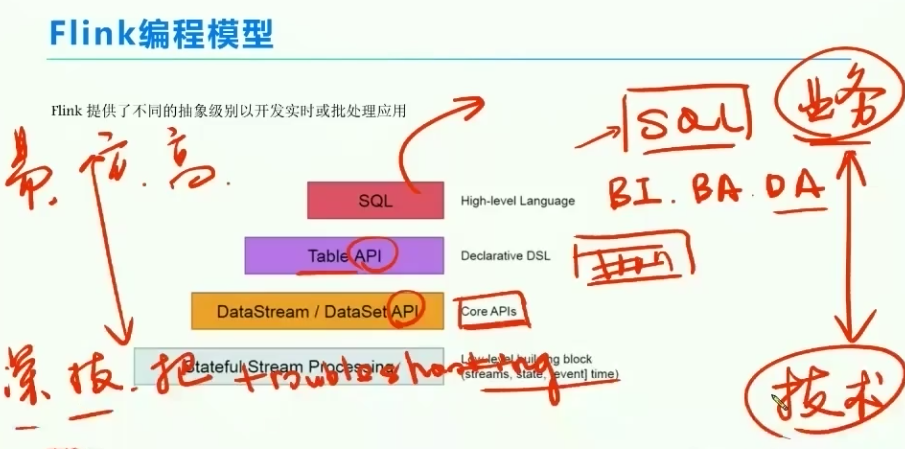
越往上,越方便,越高效
越到底层,越易于troubleshooting
4、Flink核心内容-四个顶梁柱
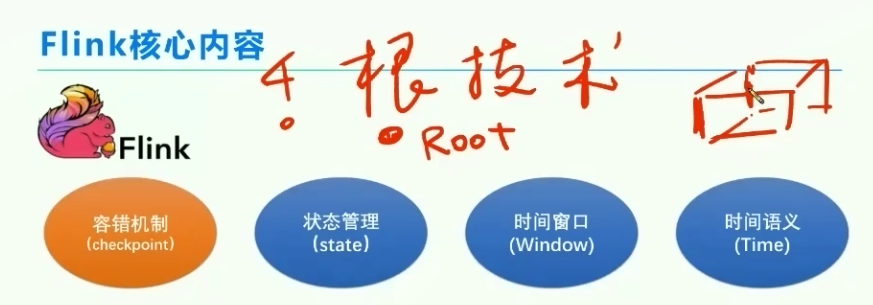
查询状态
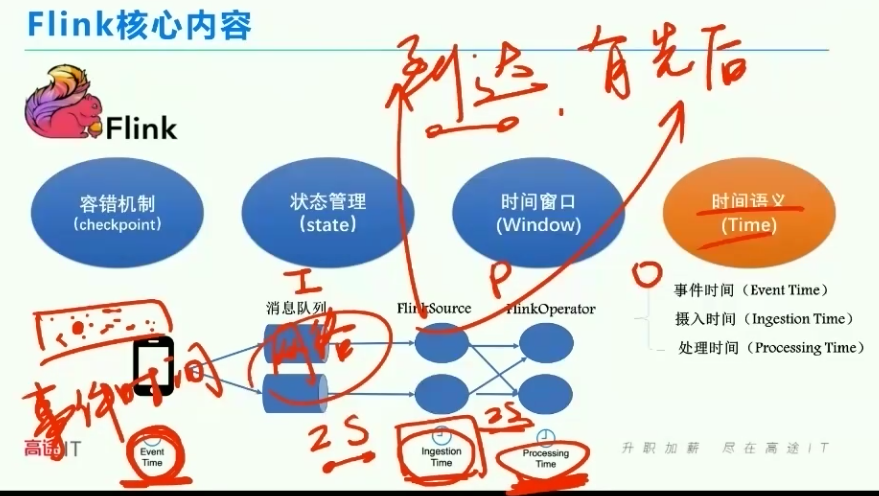
水印标签就是等待的时间,为了解决网络延迟带来的影响-相当于黄灯
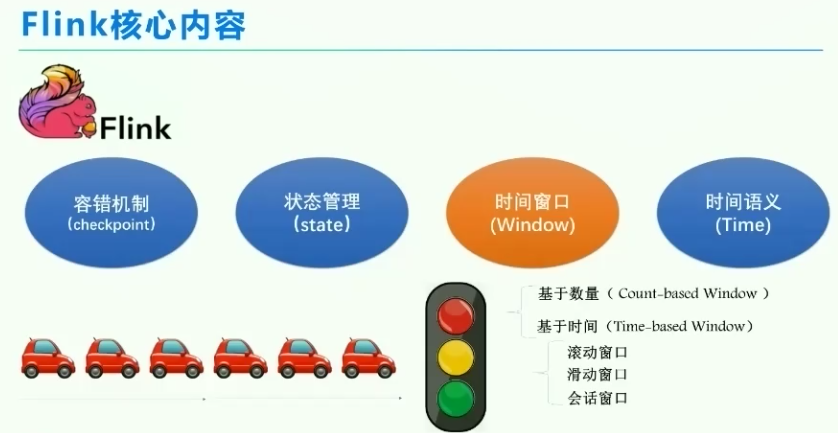
5、无界数据流中的有限数据集
现象&技术方式-分段数汽车
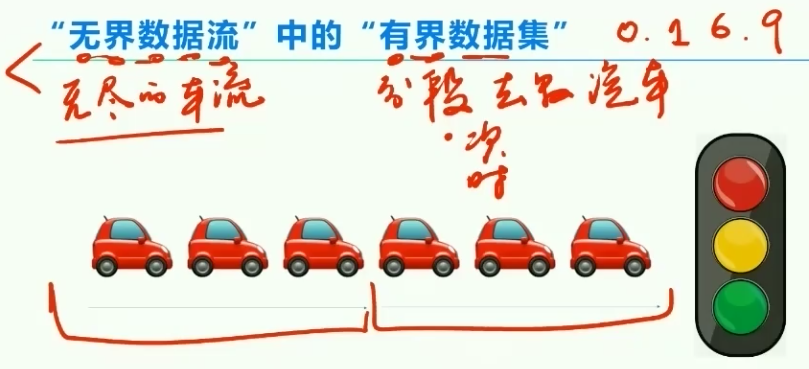
数据或时间到了触发计算(汽车通行)
五、实战技术
1、技术和生活举例了解三个内容
固态水变液态水
sink:下沉
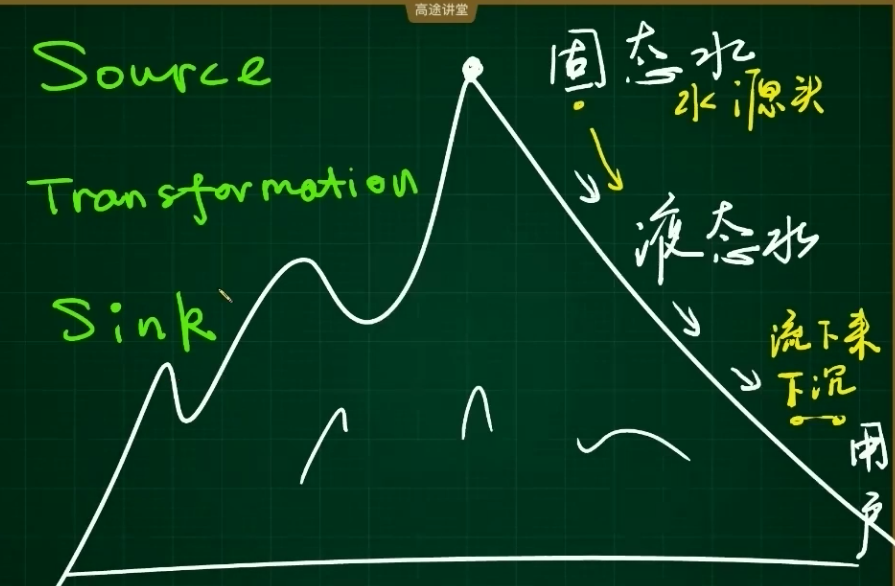
2、source
MySQL构成数据源
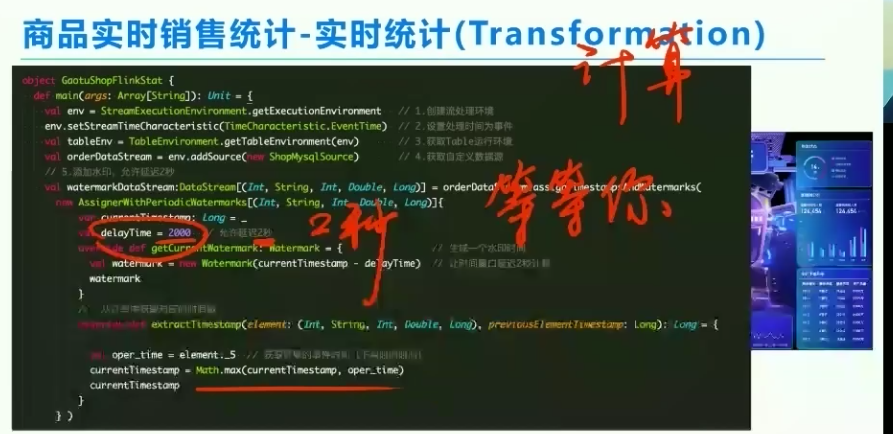
3、transform
通过水印标签watermark,实现了准确性
事件时间、摄入时间、处理时间
事件时间是客户端发生的时间
摄入时间是处理节点接收到的时间
处理时间是服务开始处理的时间
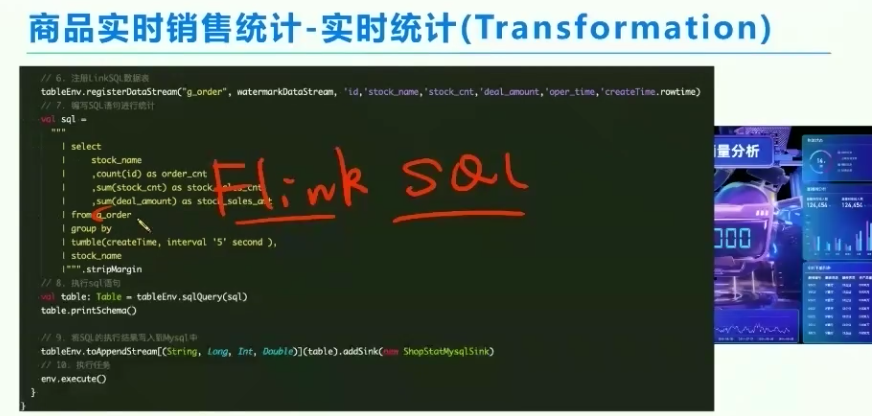
4、sink,把数据推送给谁
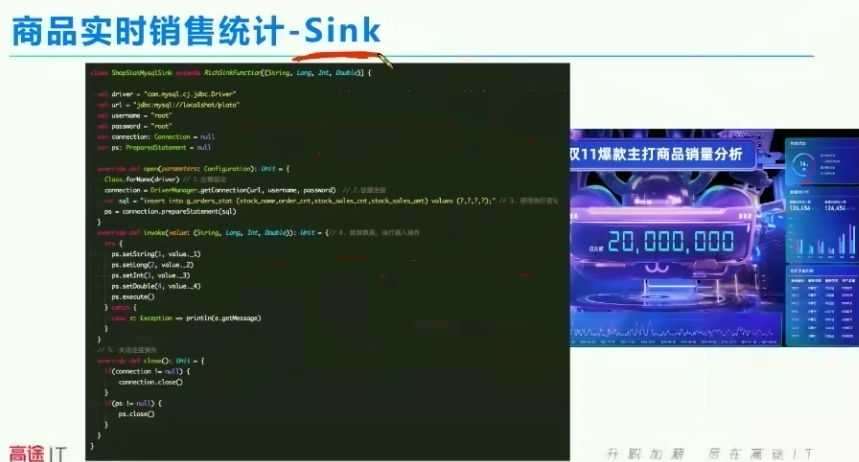
5、其他
val=value,是常量
var=variable,是变量
6、课程内容
【大数据-课程】高途-天翼云侯圣文-Day3-实时计算原理解析的更多相关文章
- 大数据量高并发的数据库优化详解(MSSQL)
转载自:http://www.jb51.net/article/71041.htm 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能. ...
- MySQL在大数据、高并发场景下的SQL语句优化和"最佳实践"
本文主要针对中小型应用或网站,重点探讨日常程序开发中SQL语句的优化问题,所谓“大数据”.“高并发”仅针对中小型应用而言,专业的数据库运维大神请无视.以下实践为个人在实际开发工作中,针对相对“大数据” ...
- Java,面试题,简历,Linux,大数据,常用开发工具类,API文档,电子书,各种思维导图资源,百度网盘资源,BBS论坛系统 ERP管理系统 OA办公自动化管理系统 车辆管理系统 各种后台管理系统
Java,面试题,简历,Linux,大数据,常用开发工具类,API文档,电子书,各种思维导图资源,百度网盘资源BBS论坛系统 ERP管理系统 OA办公自动化管理系统 车辆管理系统 家庭理财系统 各种后 ...
- 阿里大数据产品Dataphin上线公共云,将助力更多企业构建数据中台
日前,由阿里数据打造的智能数据构建与管理Dataphin,重磅上线阿里云-公共云,开启智能研发版本的公共云公测!在此之前,Dataphin以独立部署方式输出并服务线下客户,已助力多家大型客户高效自动化 ...
- DB开发之大数据量高并发的数据库优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- 大数据量高并发的数据库优化,sql查询优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- 持续引领大数据行业发展,腾讯云发布全链路数据开发平台WeData
9月11日,在腾讯全球数字生态大会大数据专场上,腾讯云大数据产品副总经理雷小平重磅发布了全链路数据开发平台WeData,同时发布和升级了流计算服务.云数据仓库.ES.企业画像等6款核心产品,进一步优化 ...
- 大数据量高并发访问SQL优化方法
保证在实现功能的基础上,尽量减少对数据库的访问次数:通过搜索参数,尽量减少对表的访问行数,最小化结果集,从而减轻网络负担:能够分开的操作尽量分开处理,提高每次的响应速度:在数据窗口使用SQL时,尽量把 ...
- 大数据(3) - 高可用 HDFS HA
HDFS HA高可用 1 HA概述 1)所谓HA(high available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制 ...
- [大数据] hadoop高可用(HA)部署(未完)
一.HA部署架构 如上图所示,我们可以将其分为三个部分: 1.NN和DN组成Hadoop业务组件.浅绿色部分. 2.中间深蓝色部分,为Journal Node,其为一个集群,用于提供高可用的共享文件存 ...
随机推荐
- Java SE 19 新增特性
Java SE 19 新增特性 作者:Grey 原文地址: 博客园:Java SE 19 新增特性 CSDN:Java SE 19 新增特性 源码 源仓库: Github:java_new_featu ...
- 在logstash中启动X-Pack Management功能后配置logstash的情况说明
开启X-Pack Management功能后,启动logstsh的时候就不用再配置logstash.conf文件了,启动的时候也不用再使用-f指定这个文件进行启动了 一旦启动了logstash的集中管 ...
- Alermanager_template,email
default.tmpl {{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing ...
- Fluentd直接传输日志给Elasticsearch
官方文档地址:https://docs.fluentd.org/output/elasticsearch td-agent的v3.0.1版本以后自带包含out_elasticsearch插件,不用再安 ...
- [题解] Codeforces 1720 E Misha and Paintings 结论
题目 算是诈骗题? 令一开始就存在的颜色数为cnt.k>=cnt的情况,显然每次找一个出现不止一次的颜色,然后把这个颜色的恰好一个方块替换成一种没有出现过的颜色就可以了,\(k-cnt\)次解决 ...
- Redis核心设计原理(深入底层C源码)
Redis 基本特性 1. 非关系型的键值对数据库,可以根据键以O(1) 的时间复杂度取出或插入关联值 2. Redis 的数据是存在内存中的 3. 键值对中键的类型可以是字符串,整型,浮点型等,且键 ...
- 邻接矩阵dfs
#include<bits/stdc++.h> using namespace std; int a[11][11]; bool visited[11]; void store_graph ...
- Nginx通用优化示例
user nginx; worker_processes auto; #worket_cpu_affinity auto; error_log /var/log/nginx/error.log war ...
- 齐博x1如何取消某个标签的缓存时间
标签默认会有缓存, 如果你要强制取消缓存时间的话, 可以加上下面的参数 time="-1"如下图所示 标签默认缓存时间是10分钟, 你也可以改成其它时间 比如 time=" ...
- 齐博x1万能数据统计接口
为何叫万能数据统计接口呢?因为可以调用全站任何数据表的数据总条数,并且可以设置查询条件http://qb.net/index.php/index/wxapp.count.html?table=memb ...