ProxySQL(11):链式规则( flagIN 和 flagOUT )
文章转载自:https://www.cnblogs.com/f-ck-need-u/p/9350631.html
理解链式规则
在mysql_query_rules表中,有两个特殊字段"flagIN"和"flagOUT",它们分别用来定义规则的入口和出口,从而实现链式规则(chains of rules)。
链式规则的实现方式如下:
- 当入口值flagIN设置为0时,表示开始进入链式规则。如未显式指定规则的flagIN值,则默认都为0。
- 当语句匹配完当前规则后,将记下当前规则的flagOUT值,如果flagOUT值非空(NOT NULL),则为该语句打上flagOUT标记。如果该规则的apply字段值不是1,则继续向下匹配。
- 如果语句的flagOUT标记和下一条规则的flagIN值不同,则跳过该规则,继续向下匹配。直到匹配到flagOUT=flagIN的规则,则匹配该规则。该规则是链式规则中的另一条规则。
- 直到某规则的apply字段设置为1,或者已经匹配完所有规则,则最后一次被评估的规则将直接生效,不再继续向下匹配。
通过下面两张图,应该很容易理解链式规则的生效方式。
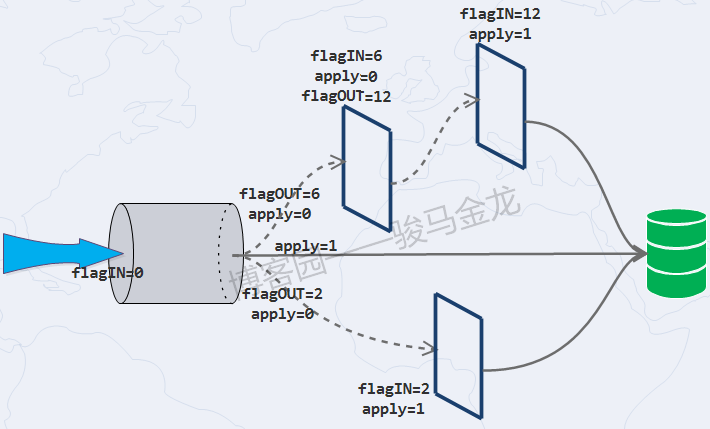
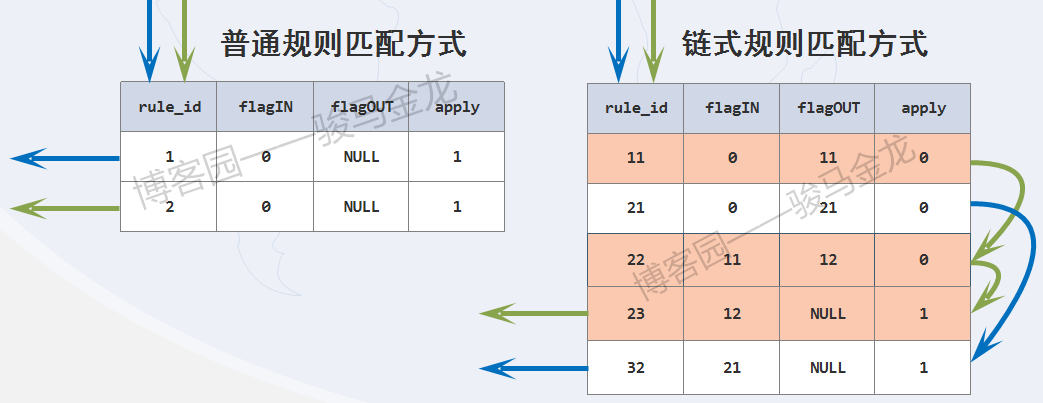
必须注意,规则是按照rule_id的大小顺序进行的。且并非只有apply=1时才会应用规则,当无规则可匹配,或者某规则的flagIN和flagOUT值相同,都会应用最后一次被评估的规则。
以下几个示例,可以解释生效规则:
# rule_id=3 生效
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | 23 |
| 3 | 0 | 23 | NULL |
+---------+-------+--------+---------+
# rule_id=2 生效
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | 23 |
| 3 | 0 | 24 | NULL |
+---------+-------+--------+---------+
# rule_id=2 生效,因为匹配完rule_id=2后,还打着flagOUT=23标记
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | NULL |
| 3 | 1 | 24 | NULL |
+---------+-------+--------+---------+
# rule_id=3 生效,因为匹配完rule_id=2后,还打着flagOUT=23标记
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | NULL |
| 3 | 1 | 23 | NULL |
+---------+-------+--------+---------+
链式规则示例
有了普通规则匹配方式,为什么还要设计链式规则呢?虽然ProxySQL通过正则表达式实现了很灵活的规则匹配模式,但需求总是千变万化的,有时候仅通过一条正则匹配规则和替换规则很难实现比较复杂的要求,例如sharding时。
链式规则除了常用的多次替换,还可巧用于多次匹配。
本文简单演示一下链式规则,不具有实际意义,只为后面ProxySQL实现sharding的文章做基础知识铺垫。
2个测试库,共4张表test{1,2}.t{1,2}。
mysql> select * from test1.t1;
+------------------+
| name |
+------------------+
| test1_t1_malong1 |
| test1_t1_malong2 |
| test1_t1_malong3 |
+------------------+
mysql> select * from test1.t2;
+------------------+
| name |
+------------------+
| test1_t2_malong1 |
| test1_t2_malong2 |
| test1_t2_malong3 |
+------------------+
mysql> select * from test2.t1;
+--------------------+
| name |
+--------------------+
| test2_t1_xiaofang1 |
| test2_t1_xiaofang2 |
| test2_t1_xiaofang3 |
+--------------------+
mysql> select * from test2.t2;
+--------------------+
| name |
+--------------------+
| test2_t2_xiaofang1 |
| test2_t2_xiaofang2 |
| test2_t2_xiaofang3 |
+--------------------+
现在借用链式规则,一步一步地将对test1.t1表的查询路由到test2.t2表的查询。再次声明,此处示例毫无实际意义,仅为演示链式规则的基本用法。
大致链式匹配的过程为:
test1.t1 --> test1.t2 --> test2.t1 --> test2.t2
以下是具体插入的规则:
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values
(1,1,0,0,23,"test1\.t1","test1.t2");
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values
(2,1,0,23,24,"test1\.t2","test2.t1");
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern,destination_hostgroup) values
(3,1,1,24,NULL,"test2\.t1","test2.t2",30);
load mysql query rules to runtime;
save mysql query rules to disk;
admin> select rule_id,
apply,
flagIN,
flagOUT,
match_pattern,
replace_pattern,
destination_hostgroup DH
from mysql_query_rules;
+---------+-------+--------+---------+---------------+-----------------+------+
| rule_id | apply | flagIN | flagOUT | match_pattern | replace_pattern | DH |
+---------+-------+--------+---------+---------------+-----------------+------+
| 1 | 0 | 0 | 23 | test1\.t1 | test1.t2 | NULL |
| 2 | 0 | 23 | 24 | test1\.t2 | test2.t1 | NULL |
| 3 | 1 | 24 | NULL | test2\.t1 | test2.t2 | 30 |
+---------+-------+--------+---------+---------------+-----------------+------+
查询test1.t1表,测试结果。
[root@xuexi ~]# mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test1.t1;"
+--------------------+
| name |
+--------------------+
| test2_t2_xiaofang1 | <-- 查询返回结果为test2.t2内容
| test2_t2_xiaofang2 |
| test2_t2_xiaofang3 |
+--------------------+
admin> select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 | <-- 3条规则全都命中
| 2 | 1 |
| 3 | 1 |
+---------+------+
admin> select hostgroup,digest_text from stats_mysql_query_digest;
+-----------+----------------------------------+
| hostgroup | digest_text |
+-----------+----------------------------------+
| 30 | select * from test2.t2 | <-- 路由目标hg=30
+-----------+----------------------------------+
显然,已经按照预想中的方式进行匹配、替换、路由。
一个问题:如果查询的是test1.t2表或test2.t1表,会进行链式匹配吗?
答案是不会,因为rule_id=2和rule_id=3这两个规则的flagIN都是非0值,而每个SQL语句初始时只进入flagIN=0的规则。
此外还需注意,当某语句未按照我们的期望途经所有的链式规则,则可能会根据destination_hostgroup字段的值直接路由出去,即使没有指定该字段值,还有用户的默认路由目标组,或者基于端口的路由目标。所以,在写链式规则时,应当尽可能地针对某一类型的语句进行完完整整的定制,保证这类语句能途经我们所期望的所有规则。
ProxySQL(11):链式规则( flagIN 和 flagOUT )的更多相关文章
- MySQL中间件之ProxySQL(11):链式规则( flagIN 和 flagOUT )
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.理解链式规则 在mysql_query_rules表中,有两个特殊 ...
- (原创)c++11中 function/lamda的链式调用
关于链式调用,比较典型的例子是c#中的linq,不过c#中的linq还只是一些特定函数的链式调用.c++中的链式调用更少见因为实现起来比较复杂.c++11支持了lamda和function,在一些延迟 ...
- PHP设计模式:类自动载入、PSR-0规范、链式操作、11种面向对象设计模式实现和使用、OOP的基本原则和自动加载配置
一.类自动载入 SPL函数 (standard php librarys) 类自动载入,尽管 __autoload() 函数也能自动加载类和接口,但更建议使用 spl_autoload_registe ...
- Objective-C 链式语法的实现
对于 Objective-C 的语法,喜欢的人会觉得它是如此的优雅,代码可读性强,接近自然语言,开发者在调用大多数方法时不需要去查看注释或文档,通常只凭借方法名就可以大致知道这个方法的作用,可以理解为 ...
- Java链式方法 连贯接口(fluent interface)
有两种情况可运用链式方法: 第一种 除最后一个方法外,每个方法都返回一个对象 object2 = object1.method1(); object3 = object2.method2(); ob ...
- zzuli 2131 Can Win dinic+链式前向星(难点:抽象出网络模型+建边)
2131: Can Win Time Limit: 1 Sec Memory Limit: 128 MB Submit: 431 Solved: 50 SubmitStatusWeb Board ...
- (数据科学学习手札107)在Python中利用funct实现链式风格编程
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 链式编程是一种非常高效的组织代码的方式,典型如p ...
- C#用链式方法表达循环嵌套
情节故事得有情节,不喜欢情节的朋友可看第1版代码,然后直接跳至“三.想要链式写法” 一.起缘 故事缘于一位朋友的一道题: 朋友四人玩LOL游戏.第一局,分别选择位置:中单,上单,ADC,辅助:第二局新 ...
- 由表单验证说起,关于在C#中尝试链式编程的实践
在web开发中必不可少的会遇到表单验证的问题,为避免数据在写入到数据库时出现异常,一般比较安全的做法是前端会先做一次验证,通过后把数据提交到后端再验证一次,因为仅仅靠前端验证是不安全的,有太多的htt ...
随机推荐
- 在矩池云使用Disco Diffusion生成AI艺术图
在 Disco Diffusion 官方说明的第一段,其对自身是这样定义: AI Image generating technique called CLIP-Guided Diffusion.DD ...
- World Tour Finals 2019 D - Distinct Boxes 题解
太神了,专门写一篇题解 qwq 简要题意:给你 \(R\) 个红球和 \(B\) 个蓝球,你要把它们放到 \(K\) 个箱子里,要求没有两个箱子完全相同(即两种球个数就相同),求 \(K\) 的最大值 ...
- 多校B层冲刺NOIP20211110 字符配对游戏
原题 问题描述 操场边,运动会没有项目的同学也没闲着,经过几天的研究,他们发明了一个很有意思的字符串配对游戏,两位同学准备两张白纸,第一个同学在纸上写一个整数N和一个由小写字母组成的字符串S,将S重复 ...
- 使用Properties集合存储数据,遍历取出Properties集合中的数据和Properties集合中的方法store和load
package com.yang.Test.PropertiesStudy; import java.io.FileWriter; import java.io.IOException; import ...
- PKUSC 2022 口胡题解
\(PKUSC\ 2022\)口胡题解 为了更好的在考试中拿分,我准备学习基础日麻知识(为什么每年都考麻将 啊啊啊) 首先\(STO\)吉老师\(ORZ,\)真的学到了好多 观察标签发现,这套题覆盖知 ...
- 从函数计算到 Serverless 架构
前言 随着 Serverless 架构的不断发展,各云厂商和开源社区都已经在布局 Serverless 领域,一方面表现在云厂商推出传统服务/业务的 Serverless 化版本,或者 Serverl ...
- 《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(10)-Fiddler如何设置捕获Firefox浏览器的Https会话
1.简介 经过上一篇对Fiddler的配置后,绝大多数的Https的会话,我们可以成功捕获抓取到,但是有些版本的Firefox浏览器仍然是捕获不到其的Https会话,需要我们更进一步的配置才能捕获到会 ...
- pytest-fixture执行顺序
作用域-scope 作用域越大,越先执行,session>package>module>class>function. 是否自动调用fixture 自动调用(autouse=T ...
- 创建Prism项目
1.创建Prism Prism是一个用于WPF.Xamarin Form.Uno平台和 WinUI 中构建松散耦合.可维护和可测试的XAML应用程序框架 通过以下方式访问.使用.学习它: https: ...
- PlayCover for mac-Mac 上全屏运行 iOS 应用程序
前言 如何在Mac电脑运行ios应用呢?PlayCover for Mac一款彻底解放苹果电脑的iOS软件安装工具,无需付费,操作简单,可以安装ipa文件,可以通过鼠标.键盘和控制器 在Mac上全屏运 ...