HBase架构、模型、特点
如需大数据开发整套视频(hadoop\hive\hbase\flume\sqoop\kafka\zookeeper\presto\spark):请联系QQ:1974983704
1、HBase概述
- HBase是一个构建在HDFS上的分布式列存储系统(数据真正存放的位置是HDFS上的,HBase是做数据管理);
- HBase是Apache Hadoop生态系统中的重要一员,主要用于海量结构化数据存储;
- HBase是Google Bigtable的开源实现;
- 从逻辑上讲,HBase将数据按照表、行和列进行存储,它是一个分布式的、稀疏的、持久化存储的多维度排序表;
- HBase VS HDFS
(HDFS适合批处理场景,HDFS不支持数据随机查找、HDFS不支持数据更新)
- HBase VS Hive
(Hive适合批处理数据分析场景;Hive不适合实时的数据访问)
2、HBase应用场景
网页库(360搜索-网络爬虫)
商品库(淘宝搜索-历史长的查询)
交易信息(淘宝数据魔方)
云存储服务(小米)
用户画像系统
监控信息(OpenTSDB)
3、HBase概念模型
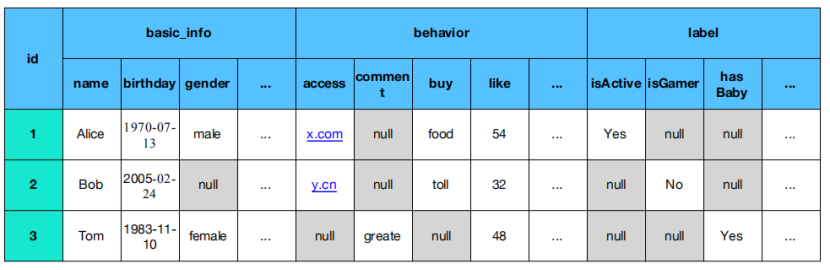
HBase中数据是可以有多个版本的(默认会返回最新的数据)
- HBase VS Mysql
列:
-HBase的列是可以无限扩展的;
-HBase的列没有类型;
-HBase的多个列可以构成一个列簇(column family)
主键&索引:
-HBase有且仅有一个主键(row key);
-数据根据主键进行排序;-不支持二级索引;
值:
-HBase的值是由多个版本的,每一个成为一个Cell;
-Cell的数目也没有限制(默认是3个)
4、HBase模型特点
高可靠性
与MapReduce良好的集成
可扩展性强:支持数十亿行,上百万列;支持数十万个版本
可以存储非常稀疏的数据
支持点查:根据主键获取一行数据
支持扫描:快速获取某些行区间范围的数据;高效获取某几列的数据
5、HBase物理模型
数据存储需求:节省空间,null值不存储;节省IO,列式扫描少读取数据
数据存储方案的选择:行式存储Mysql,列式存储HBase
列簇式存储:同一列簇的所有列的数据存放在一起;不同列簇的数据物理上分开存储
- HBase物理模型-Cell格式
Cell的构成部分
-row key
-column family
-qualifier(column)
-timestamp
-value
- HBase物理模型-列簇
列簇可以看成式一系列排序好的cell的集合
Cell按照下列顺序进行排序
-row key升序
-column family升序
-qualifier升序
-timestamp降序
- 支持快速检索(二分查找)
- HBase物理模型

HBase将一张大表拆分为多个分片,每一个分片称为一个Region(默认好像式1个G,可以设置);
不同的Region可以放在不同的服务器上;
分片的方式式按照主键的取值区间划分;
每一个Region都包含所有的列簇;
Region按大小分割的,每个表开始只有一个Region,随着数据增多,Region不断增大,当增到到一个阀值的时候,Region就会等分成两个新的Region,之后会有越来越多的Region;
Region式HBase中分布式存储和负载均衡的最小单元
Region内部包含多个列簇,每一个列簇交给一个Store来存储
每个Store将数据分为两部分:存储在内存中的数据(MemStore)和存储在文件系统的数据(StoreFile)
MemStore只存储新增的和修改过的数据,并在内存满的时候将数据刷到StoreFile中
6、HBase架构
HBase的所有数据都存储在HDFS上,只做数据管理工作
HBase还依赖于Zookeeper
HBase本身只有两个角色RegionServer和HMaster
一个HRegionServer下只有一个HLog
- HRegion(区域)
HBase会自动的将表划分为不同的区域
每个区域包含所有行的一个子集
对用户来说,每个表是一堆数据的集合,靠主键来区分
从物理上来说,一张表被拆分成了多块,每一块是一个HRegion
我们用表名+开始和结束主键,来区分每一个HRegion
一个HRegion会保存一个表里面某段连续的数据,从开始主键到结束主键
一张完整的表格是保存在多个HRegion上面
- HRegionServer
所有的数据库数据都保存在HDFS上面
用户通过访问HRegionServer获取这些数据
一台机器上面一般只运行一个HRegionServer
一个HRegionServer上面有多个HRegion,一个HRegion也只会被一个HRegionServer维护
HRegionServer主要负责响应用户I/O请求,从HDFS读写数据,是HBase中最核心的模块
HRegionServer内部管理了一系列的HRegion对象
每个HRegion对应了Table中的一个Region,HRegion中由多个HStore组成
每个HStore对应了Table中的一个Column Family的存储
最好将具备共同IO特性的Column放在一个Column Family中
- HMaster
每个HRegionServer都会与HMaster通信
HMaster的主要任务就是给HRegionServer分配HRegion
HMaster指定HRegionServer要维护哪些HRegion
当一台HRegionServer宕机时,HMaster会把它负责的HRegion标记为未分配,然后再把它们分配到其他HRegionServer中
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
-.管理用户对Table的增、删、改、查操作;
-管理HRegionServer的负载均衡,调整Region分布;
-在Region Split后,负责新的Region的分配;
-在HRegionServer停机后,负责失效HRegionServer上的Regions迁移
HBase架构、模型、特点的更多相关文章
- HBASE架构解析(二)
http://www.blogjava.net/DLevin/archive/2015/08/22/426950.html HBase读的实现 通过前文的描述,我们知道在HBase写时,相同Cell( ...
- 深入了解HBASE架构(转)
dd by zhj: 最近的工作需要跟HBase打交道,所以花时间把<HBase权威指南>粗略看了一遍,感觉不过瘾,又从网上找了几篇经典文章. 下面这篇就是很经典的文章,对HBase的架构 ...
- 深入HBase架构解析(二)【转】
转自:http://www.blogjava.net/DLevin/archive/2015/08/22/426950.html 前言 这是<深入HBase架构解析(一)>的续,不多废话, ...
- 【转】HBase架构解析
转载地址:http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html HBase架构组成 HBase采用Master/Slave架构搭建 ...
- Hbase架构和读写流程
转载自:http://www.cnblogs.com/muzili-ykt/p/muzili_ykt.html 在HBase读写时,相同Cell(RowKey/ColumnFamily/Column相 ...
- [转]毕设- 深入HBase架构解析(二)
深入HBase架构解析(二) 前言 这是<深入HBase架构解析(一)>的续,不多废话,继续.... HBase读的实现 通过前文的描述,我们知道在HBase写时,相同Cell(RowKe ...
- 详解HBase架构原理
一.什么是HBase HBase是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价的PC Server上搭建大规模结构化存储集群. H ...
- [转帖]深度分析HBase架构
深度分析HBase架构 https://zhuanlan.zhihu.com/p/30414252 原文链接(https://mapr.com/blog/in-depth-look-hbase-a ...
- hbase架构和读写过程
转载自:https://www.cnblogs.com/itboys/p/7603634.html 在HBase读写时,相同Cell(RowKey/ColumnFamily/Column相同)并不保证 ...
- HBASE架构解析(一)
http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html 前记 公司内部使用的是MapR版本的Hadoop生态系统,因而从MapR的官 ...
随机推荐
- ssh 免密访问
首先配置三台机器的hosts文件 填写需要配置的三台主机ip,然后命名,这里我写的时 t1 t2 t3 三台机器上都要配置hosts文件,要配置一样. 三台机器改完后保存退出 ping一下刚才配置的三 ...
- 重试机制的实现(Guava Retry)
重试机制的实现 重试作用: 对于重试是有场景限制的,参数校验不合法.写操作等(要考虑写是否幂等)都不适合重试. 远程调用超时.网络突然中断可以重试.外部 RPC 调用,或者数据入库等操作,如果一次操作 ...
- gin web 2
routers/router.go package routers import ( "github.com/gin-gonic/gin" "gin-blog/pkg/s ...
- maven 引入了jar包,但却不能使用jar包里类
无报错,但是就是 无法 使用 lombok 的类. 发现classpath 里面也的确没有lombok jar包. 最后把json 的 version 属性加上 就正常了. 所以 结论: 不加vers ...
- 渲染杂谈:early-z、z-culling、hi-z、z-perpass到底是什么?
之前一直被这几个和深度缓存(z-buffer)相关的概念搞得神魂颠倒.今天在翻阅<Real-Time Rendering>时碰巧碰巧看到了这部分的讲解.硬着头皮看了看,姑且算是讲几个概念分 ...
- python监控文件变化
网址: https://blog.csdn.net/qq_40223983/article/details/102889329 起步在python中文件监控主要有两个库,一个是pyinotify,一个 ...
- SPI接口
串行外设接口(Serial Peripheral Interface)是一种同步外设接口,它可以使单片机与各种外围设备以串行方式进行通信以交换信息.SPI最早是Motorola公司提出的全双工三线同步 ...
- iOS开发 网络学习(4)HTTPS
一.HTTPS简介 HTTPS : Hyper Text Transfer Protocol over Secure Socket Layer,是以安全为目标的HTTP通道,简单讲是HTTP的安全版. ...
- Java流程控制之while循环详解
while循环 while循环 do...while循环 for循环 在Java5中引入了一种主要用于数组的增强型for循环 while循环 while循环是最基本的循环,它的结构为 while(布尔 ...
- nginx的nginx.conf目录简单配置
我的nginx.conf是在 etc/nginx/目录下 我是直接在http随便找了个地方添加如下代码的: server { listen 8066; server_name 192.168.0.2 ...