kubernetes之HPA
1.什么是HPA?
在 Kubernetes 中,HorizontalPodAutoscaler 自动更新工作负载资源 (例如 Deployment 或者 StatefulSet), 目的是自动扩缩工作负载以满足需求。
水平扩缩意味着对增加的负载的响应是部署更多的 Pods。 这与 “垂直(Vertical)” 扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
如果负载减少,并且 Pod 的数量高于配置的最小值, HorizontalPodAutoscaler 会指示工作负载资源( Deployment、StatefulSet 或其他类似资源)缩减。
水平 Pod 自动扩缩不适用于无法扩缩的对象(例如:DaemonSet。)
HorizontalPodAutoscaler 被实现为 Kubernetes API 资源和控制器。
资源决定了控制器的行为。在 Kubernetes 控制平面内运行的水平 Pod 自动扩缩控制器会定期调整其目标(例如:Deployment)的所需规模,以匹配观察到的指标, 例如,平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标。
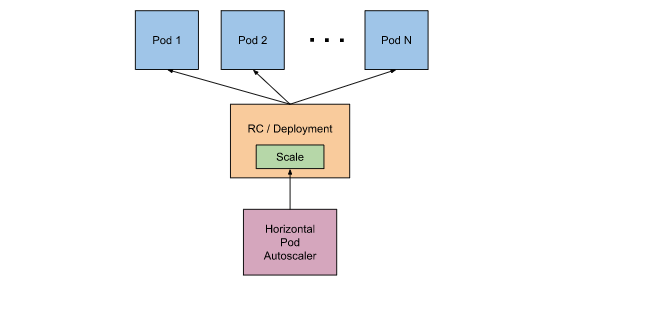
官方是这样给出的。
2.下载metrics
GitHUB地址
https://github.com/kubernetes-sigs/metrics-server
3.测试是否metrics是否正常运行,metrics正常运行。
kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
kubernetes-master01 183m 4% 1279Mi 21%
kubernetes-node01 49m 1% 1111Mi 18%
kubernetes-node02 39m 0% 369Mi 6%
4.创建测试应用
vim web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web-nginx-hpa
name: web-deployment-nginx-test
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: web-nginx-hpa
template:
metadata:
labels:
app: web-nginx-hpa
spec:
containers:
- image: nginx
name: web-deployment-nginx-test
resources:
limits:
cpu: "50m"
memory: 20Mi
requests:
cpu: "50m"
memory: 20Mi
5.创建Serivce,这一步可以为前端提供一个访问入口。方便我们测试使用。
cat service-hpa.yaml
apiVersion: v1
kind: Service
metadata:
name: hpa-service
spec:
selector:
run: php-apache
ports:
- name: http
port: 80
targetPort: 80
6.创建hpa资源
cat web.hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: web-deployment-nginx-test
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-deployment-nginx-test
minReplicas: 2 # 最小Pod数量
maxReplicas: 10 # 最大Pod数量
targetCPUUtilizationPercentage: 30 # CPU到百分之30使用扩缩容。
7.创建完毕后测试。
while :;do wget -q -O- http://nginx-hpa;done
8.随着不断访问,流量渐渐上来了。会触发扩缩容。
kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web-deployment-nginx-test Deployment/web-deployment-nginx-test 0%/30% 2 10 2 90m
web-deployment-nginx-test Deployment/web-deployment-nginx-test 76%/30% 2 10 2 90m
web-deployment-nginx-test Deployment/web-deployment-nginx-test 76%/30% 2 10 4 91m
web-deployment-nginx-test Deployment/web-deployment-nginx-test 55%/30% 2 10 6 91m
web-deployment-nginx-test Deployment/web-deployment-nginx-test 50%/30% 2 10 6 91m
9.停止压测。因为默认情况下,每30s检测一次指标,只要检测到了配置HPA的目标值,则会计算出预期的工作负载的副本数,再进行扩缩容操作。同时,为了避免过于频繁的扩缩容,默认在5min内没有重新扩缩容的情况下,才会触发扩缩容。 不过,HPA本身的算法相对比较保守,可能并不适用于很多场景。例如,一个快速的流量突发场景,如果正处在5min内的HPA稳定期,这个时候根据HPA的策略,会导致无法扩容。 另外,在一些Serverless场景下,有缩容到0然后冷启动的需求,但HPA默认不支持。
kubectl get pod -w
web-deployment-nginx-test-54f8c5b657-c2wc4 1/1 Running 0 44m
web-deployment-nginx-test-54f8c5b657-c54w4 0/1 ContainerCreating 0 1s
web-deployment-nginx-test-54f8c5b657-cgf74 0/1 ContainerCreating 0 16s
web-deployment-nginx-test-54f8c5b657-k4mpc 0/1 ContainerCreating 0 1s
web-deployment-nginx-test-54f8c5b657-qv9f2 1/1 Running 0 16s
web-deployment-nginx-test-54f8c5b657-v5zfr 1/1 Running 0 3m4s
web-deployment-nginx-test-54f8c5b657-cgf74 1/1 Running 0 27s
kubernetes之HPA的更多相关文章
- 基于Custom-metrics-apiserver实现Kubernetes的HPA(内含踩坑)
前言 这里要说一下Prometheus的检控指标从哪里来,它有3个渠道: 主机监控,也就是部署了Node Exporter组件的主机,它以DaemonSet或者系统进程的形式运行,Prometheus ...
- 基于Kubernetes的hpa实现pod实例数量的自动伸缩
Pod 是在 Kubernetes 体系中,承载用户业务负载的一种资源.Pod 们运行的好坏,是用户们最为关心的事情.在业务流量高峰时,手动快速扩展 Pod 的实例数量,算是玩转 Kubernetes ...
- Kubernetes 弹性伸缩HPA功能增强Advanced Horizontal Pod Autoscaler -介绍部署篇
背景 WHAT(做什么) Advanced Horizontal Pod Autoscaler(简称:AHPA)是kubernetes中HPA的功能增强. 在兼容原生HPA功能基础上,增加预测.执行模 ...
- Kubernetes(二)架构及资源关系简单总结
Kubernetes架构 先引用一下官方的架构图: 对于本文来说,我觉得这张图有点复杂了,但是我又懒得自己画了,就用这张吧.Kubernetes是一个集群,和传统的集群相似,它也是有一个主节点和若干个 ...
- Kubernetes之Pod使用
一.什么是Podkubernetes中的一切都可以理解为是一种资源对象,pod,rc,service,都可以理解是 一种资源对象.pod的组成示意图如下,由一个叫”pause“的根容器,加上一个或多个 ...
- kubernetes 降本增效标准指南| 容器化计算资源利用率现象剖析
作者:詹雪娇,腾讯云容器产品经理,目前主要负责腾讯云集群运维中心的产品工作. 张鹏,腾讯云容器产品工程师,拥有多年云原生项目开发落地经验.目前主要负责腾讯云TKE集群和运维中心开发工作. 引言 降本增 ...
- kubernetes 降本增效标准指南|理解弹性,应用弹性
弹性伸缩在云计算领域的简述 弹性伸缩又称自动伸缩,是云计算场景下一种常见的方法,弹性伸缩可以根据服务器上的负载.按一定的规则.进行弹性的扩缩容服务器. 弹性伸缩在不同场景下的含义: 对于服务运行在自建 ...
- 蚂蚁金服 Service Mesh 渐进式迁移方案|Service Mesh Meetup 实录
小蚂蚁说: 本文是基于在 Service Mesher Meetup 上海站的主题分享<蚂蚁金服 Service Mesh 渐进式迁移方案>内容整理,完整的分享 PPT 获取方式见文章底部 ...
- k8s 应用优先级,驱逐,波动,动态资源调整
k8s 应用优先级,驱逐,波动,动态资源调整 应用优先级 Requests 和 Limits 的配置除了表明资源情况和限制资源使用之外,还有一个隐藏的作用:它决定了 Pod 的 QoS 等级. 上一节 ...
随机推荐
- 一文读懂 Kubernetes 容器网络
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 在Kubernetes中要保证容器之间网络互通,网络至关 ...
- 2021春季学期华清大学EE数算OJ3:岩石的重量
原题目如下: 看起来,这不过是我们在<程序设计基础>里面接触过的简单动态规划问题(什么,你不知道什么叫动态规划? 什么是动态规划? 百度百科对"动态规划"一词定义如下: ...
- intelij idea 好用的插件
简介 记录一下平时使用的插件 Foldable ProjectView 隐藏目录或文件 One Dark theme 主题比较好用 Gitmoji Plus: Commit Button 在 comm ...
- 好客租房32-事件绑定this指向(class实例方法)
class实例方法 利用箭头函数的class实例方法 //导入react import React from 'react' import ReactDOM from 'react-dom' // ...
- K8S 部署Dashboard UI
Kubernetes Dashboard是Kubernetes集群的通用.基于Web的UI.它允许用户管理集群中运行的应用程序并对其进行故障排除,以及管理集群本身. 访问到DashBoard有两种方式 ...
- 降维、特征提取与流形学习--非负矩阵分解(NMF)
非负矩阵分解(NMF)是一种无监督学习算法,目的在于提取有用的特征(可以识别出组合成数据的原始分量),也可以用于降维,通常不用于对数据进行重建或者编码. NMF将每个数据点写成一些分量的加权求和(与P ...
- 论文解读(AGE)《Adaptive Graph Encoder for Attributed Graph Embedding》
论文信息 论文标题:Adaptive Graph Encoder for Attributed Graph Embedding论文作者:Gayan K. Kulatilleke, Marius Por ...
- springcloud 断路器
https://www.jb51.net/article/138572.htm 参考资料: http://www.cnblogs.com/ulysses-you/p/7281662.html http ...
- CSS中html的标签元素分类
在CSS中,html中的标签元素大体被分为三种不同的类型: 块状元素.内联元素(又叫行内元素)和内联块状元素. 常用的块状元素有: <div>.<p>.<h1&g ...
- tmux(Terminal MultipleXer)命令使用
作用:命令行多窗口显示:命令行程序与本机脱离 1 安装tmux (1)redhat.centos系统 yum install tmux (2)ubuntu系统 apt-get install tmux ...