AlphaZero并行五子棋AI
AlphaZero-Gomoku-MPI
Link
Github : AlphaZero-Gomoku-MPI
Overview
This repo is based on junxiaosong/AlphaZero_Gomoku, sincerely grateful for it.
I do these things:
- Implement asynchronous self-play training pipeline in parallel like AlphaGo Zero's way
- Write a root parallel mcts (vote a move using ensemble way)
- Use ResNet structure to train the model and set a transfer learning API to train a larger board model based on small board's model (like pre-training way in order to save time)
Strength
- Current model is on 11x11 board, and playout 400 times when test
- Play with this model, can always win regardless of black or white
- Play with gomocup's AI, can rank around 20th-30th for some rough tests
- When I play white, I can't win AI. When I play black, end up with tie/lose for most of my time
References
- Mastering the game of Go without human knowledge
- A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
- Parallel Monte-Carlo Tree Search
Blog
Installation Dependencies
- Python3
- tensorflow>=1.8.0
- tensorlayer>=1.8.5
- mpi4py (parallel train and play)
- pygame (GUI)
How to Install
tensorflow/tensorlayer/pygame install :
conda install tensorflow
conda install tensorlayer
conda install pygame
mpi4py install click here
mpi4py on windows click here
How to Run
- Play with AI
python human_play.py
- Play with parallel AI (-np : set number of processings, take care of OOM !)
mpiexec -np 3 python -u human_play_mpi.py
- Train from scratch
python train.py
- Train in parallel
mpiexec -np 43 python -u train_mpi.py
Algorithm
It's almost no difference between AlphaGo Zero except APV-MCTS.
A PPT can be found in dir demo/slides
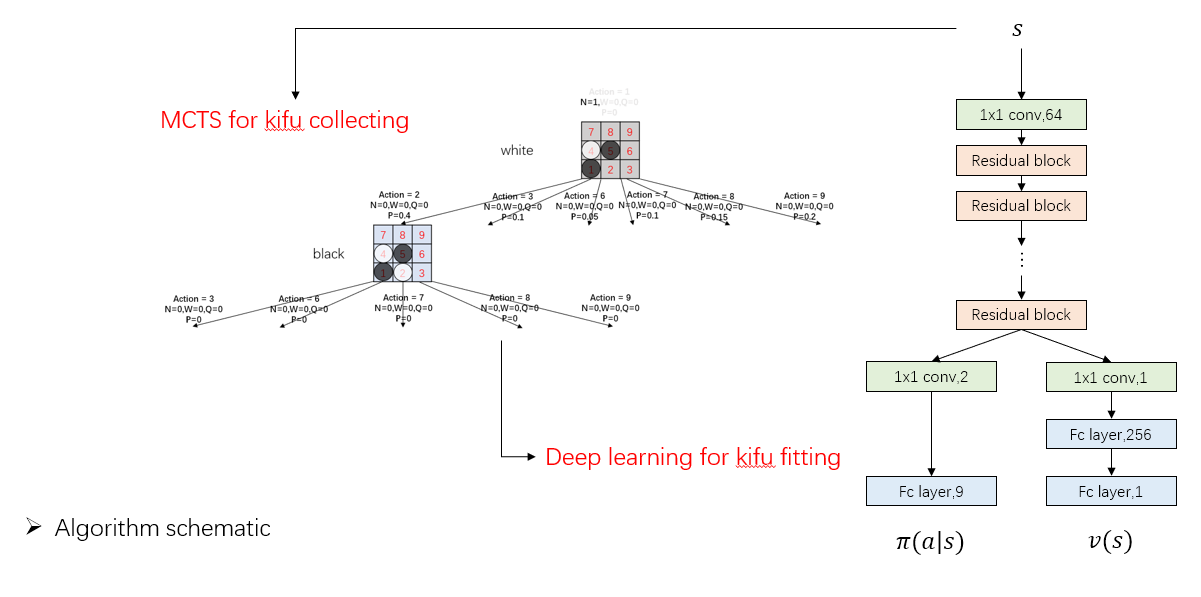
Details
Most settings are the same with AlphaGo Zero, details as follow :
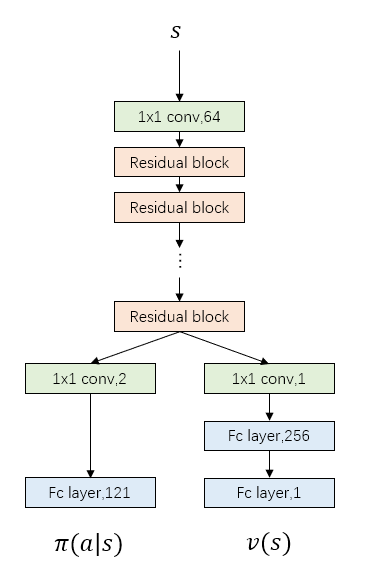
Network Structure
- Current model uses 19 residual blocks, more blocks means more accurate prediction but also slower speed
- The number of filters in convolutional layer shows in the follow picture
Feature Planes
- In AlphaGo Zero paper, there are 19 feature planes: 8 for current player's stones, 8 for opponent's stones, and the final feature plane represents the colour to play
- Here I only use 4 for each player, it can be easily changed in
game_board.py
Dirichlet Noise
- I add dirichlet noises in each node, it's different from paper that only add noises in root node. I guess AlphaGo Zero discard the whole tree after each move and rebuild a new tree, while here I keep the nodes under the chosen action, it's a little different
- Weights between prior probabilities and noises are not changed here (0.75/0.25), though I think maybe 0.8/0.2 or even 0.9/0.1 is better because noises are added in every node
parameters in detail
I try to maintain the original parameters in AlphaGo Zero paper, so as to testify it's generalization. Besides, I also take training time and computer configuration into consideration.
Parameters Setting Gomoku AlphaGo Zero MPI num 43 - c_puct 5 5 n_playout 400 1600 blocks 19 19/39 buffer size 500,000(data) 500,000(games) batch_size 512 2048 lr 0.001 annealed optimizer Adam SGD with momentum dirichlet noise 0.3 0.03 weight of noise 0.25 0.25 first n move 12 30
Training detials
- I train the model for about 100,000 games and takes 800 hours or so
- Computer configuration : 2 CPU and 2 1080ti GPU
- We can easily find the computation gap with DeepMind and rich people can do some future work
Some Tips
- Network
- ZeroPadding with Input : Sometimes when play with AI, it's unaware of the risk at the edge of board even though I'm three/four in a row. ZeroPadding data input can mitigate the problem
- Put the network on GPU : If the network is shallow, it's not matter CPU/GPU to use, otherwise it's faster to use GPU when self-play
- Dirichlet Noise
- Add Noise in Node : In junxiaosong/AlphaZero_Gomoku, noises are added outside the tree, seemingly like DQN's \(\epsilon-greedy\) way. It's ok when I test on 6x6 and 8x8 board, but when on 11x11 some problems occur. After a long time training on 11x11, black player will always play the first stone in the middle place with policy probability equal to 1. It's very rational for black to play here, however, the white player will never see other kifu that play in the other place at first stone. So, when I play black with AI and place somewhere not the middle place, AI will get very stupid because it has never seen this way at all. Add noise in node can mitigate the problem
- Smaller Weight with Noise : As I said before, I think maybe 0.8/0.2 or even 0.9/0.1 is a better choice between prior probabilities and noises' weights, because noises are added in every node
- Randomness
- Dihedral Reflection or Rotation : When use the network to output probabilities/value, it's better to do as paper said: The leaf node \(s_L\) is added to a queue for neural network evaluation, \((d_i(p),v)=f_{\theta}(d_i(s_L))\), where \(d_i\) is a dihedral reflection or rotation selected uniformly at random from \(i\) in \([1..8]\)
- Add Randomness when Test : I add the dihedral reflection or rotation also when play with it, so as to avoid to play the same game all the time
- Tradeoffs
- Network Depth : If the network is too shallow, loss will increase. If too deep, it's slow when train and test. (My network is still a little slow when play with it, I think maybe 9 blocks is all right)
- Buffer Size : If the size is small, it's easy to fit by network but can't guarantee it's performance for only learning from these few data. If it's too large, much longer time and deeper network structure should be taken
- Playout Number : If small, it's quick to finish a self-play game but can't guarantee kifu's quality. On the contrary with more playout times, better kifu will get but also take longer time
Future Work Can Try
- Continue to train (a larger board) and increase the playout number
- Try some other parameters for better performance
- Alter network structure
- Alter feature planes
- Implement APV-MCTS
- Train on standard/renju rule
AlphaZero并行五子棋AI的更多相关文章
- 五子棋AI清月连珠开源
经过差不多两年的业余时间学习和编写,最近把清月连珠的无禁手部分完善得差不多了.这中间进行了很多思考,也有很多错误认识,到现在有一些东西还没有全面掌握,所以想通过开源于大家共同交流. 最近一直发表一些五 ...
- 五子棋AI大战OC实现
Gobang 五子棋AI大战,该项目主要用到MVC框架,用算法搭建AI实现进攻或防守 一.项目介绍 1.地址: github地址:Gobang 2.效果图: 二.思路介绍 大概说下思路,具体看代码实现 ...
- 五子棋AI教程
https://github.com/Chuck-Ai/gobang 我写了非常详细的中文教程,教你如何一步步编写自己的五子棋AI: 五子棋AI设计教程第二版一:前言 五子棋AI设计教程第二版二:博弈 ...
- 使用QT creator实现一个五子棋AI包括GUI实现(8K字超详细)
五子棋AI实现 五子棋游戏介绍 五子棋的定义 五子棋是全国智力运动会竞技项目之一,是具有完整信息的.确定性的.轮流行动的.两个游戏者的零和游戏.因此,五子棋是一个博弈问题. 五子棋的玩法 五子棋有两种 ...
- 【五子棋AI循序渐进】——开局库
首先,对前面几篇当中未修复的BUG致歉,在使用代码时请万分小心…………尤其是前面关于VCF\VCT的一些代码和思考,有一些错误.虽然现在基本都修正了,但是我的程序还没有经过非常大量的对局,在这之前,不 ...
- 【五子棋AI循序渐进】关于VCT,VCF的思考和核心代码
前面几篇发布了一些有关五子棋的基本算法,其中有一些BUG也有很多值得再次思考的问题,在框架和效果上基本达到了一个简单的AI的水平,当然,我也是初学并没有掌握太多的高级技术.对于这个程序现在还在优化当中 ...
- 人机ai五子棋 ——五子棋AI算法之Java实现
人机ai五子棋 下载:chess.jar (可直接运行) 源码:https://github.com/xcr1234/chess 其实机器博弈最重要的就是打分,分数也就是权重,把棋子下到分数大的地方, ...
- 五子棋 AI(AIpha-beta算法)
博弈树 下过五子棋的人都应该知道,越厉害的人,对棋面的预测程度越深.换句话讲,就是当你下完一步棋,我就能在我的脑海里假设把我所有可能下的地方都下一遍,然后考虑我下完之后你又会下在哪里,最后我根据每次预 ...
- 五子棋AI的思路
隔了一年才把AI思路给写了... 需求分析与设计方案:http://www.cnblogs.com/songdechiu/p/4951634.html 如需整个工程,移步http://download ...
随机推荐
- 可简单避免的三个 JavaScript 发布错误
Web应用程序开发是倾向于在客户端运行所有用户逻辑和交互代码,让服务器暴露REST或者RPC接口.编译器是针对JS作为一个平台,第二版ECMAScript正是考虑到这一点在设计.客户端框架例如Back ...
- thinkphp报错Call to undefined method app\index\controller\Index::fetch()
因为要写一个系统,所以又重新下载了thinkphp,然后安装了一下.回忆起这个问题很容易让新手朋友费解.会出现如下报错:Call to undefined method app\index\contr ...
- docker 错误排查:无法进入容器.
docker 错误排查:无法进入容器. #docker exec -it 3c1d bash rpc error: code = 2 desc = oci runtime error: exec fa ...
- 两个Bounding Box的IOU计算代码
Bounding Box的数据结构为(xmin,ymin,xmax,ymax) 输入:box1,box2 输出:IOU值 import numpy as np def iou(box1,box2): ...
- Gradle详解
一.脚本文件(build.gradle) 项目与脚本文件 当我们执行gradle命令的时候,Gradle会在你执行命令的目录下寻找一个名为build.gradle的文件,这个文件就是Gradle的脚 ...
- python网络编程-多进程multiprocessing
一:mutilprocess简介 多线程类似于同时执行多个不同程序,多线程运行有如下优点: 使用线程可以把占据长时间的程序中的任务放到后台去处理. 用户界面可以更加吸引人,这样比如用户点击了一个按钮去 ...
- No.6 selenium学习之路之下拉框Select
HTML中,标签显示为select,有option下拉属性的为Select弹框 1.Xpath定位 Xpath语法,顺序是从1开始,编程语言中是0开始
- 网络协议之TCP
前言 近年来,随着信息技术的不断发展,各行各业也掀起了信息化浪潮,为了留住用户和吸引用户,各个企业力求为用户提供更好的信息服务,这也导致WEB性能优化成为了一个热点.据分析,网站速度越快,用户的黏性. ...
- HDU 2874 Connections between cities(LCA(离线、在线)求树上距离+森林)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2874 题目大意:给出n个点,m条边,q个询问,每次询问(u,v)的最短距离,若(u,v)不连通即不在同 ...
- Luogu P2310 【loidc,看看海】
各位大佬都用的排序和杨颙大定理,蒟蒻的我怎么也不会做(瑟瑟发抖),那么,就来一发主席树吧.我们知道线段树可以维护区间,平衡树可以维护值域那么,我们可以用线段树套平衡树来解决这个区间值域的问题线段树套平 ...