Spark(二)【sc.textfile的分区策略源码分析】
sparkcontext.textFile()返回的是HadoopRDD!
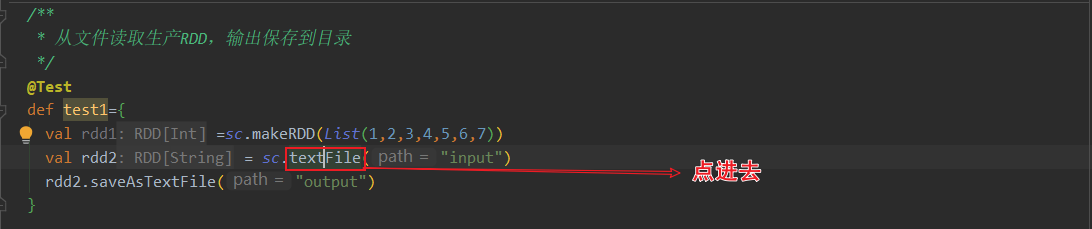
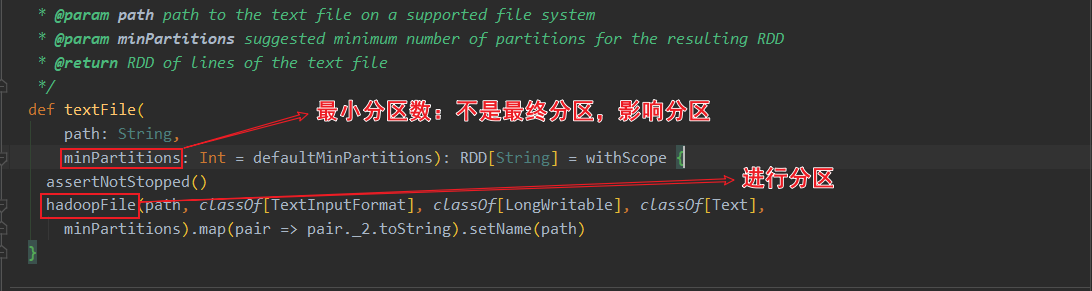
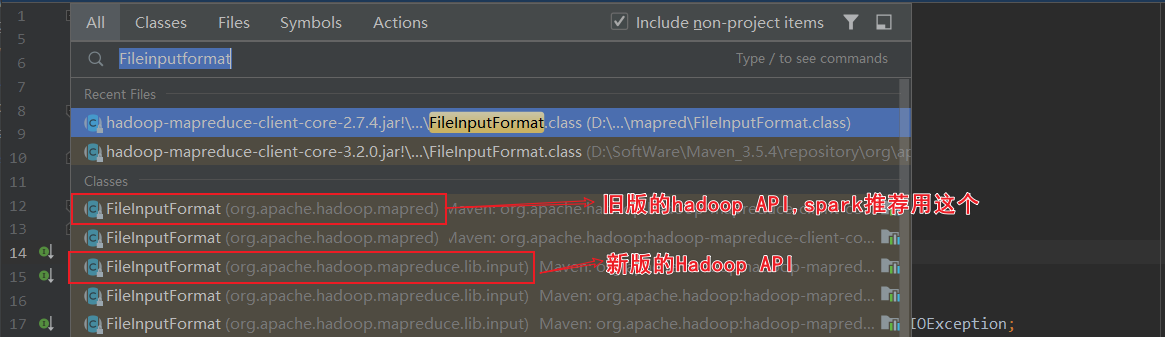
关于HadoopRDD的官方介绍,使用的是旧版的hadoop api

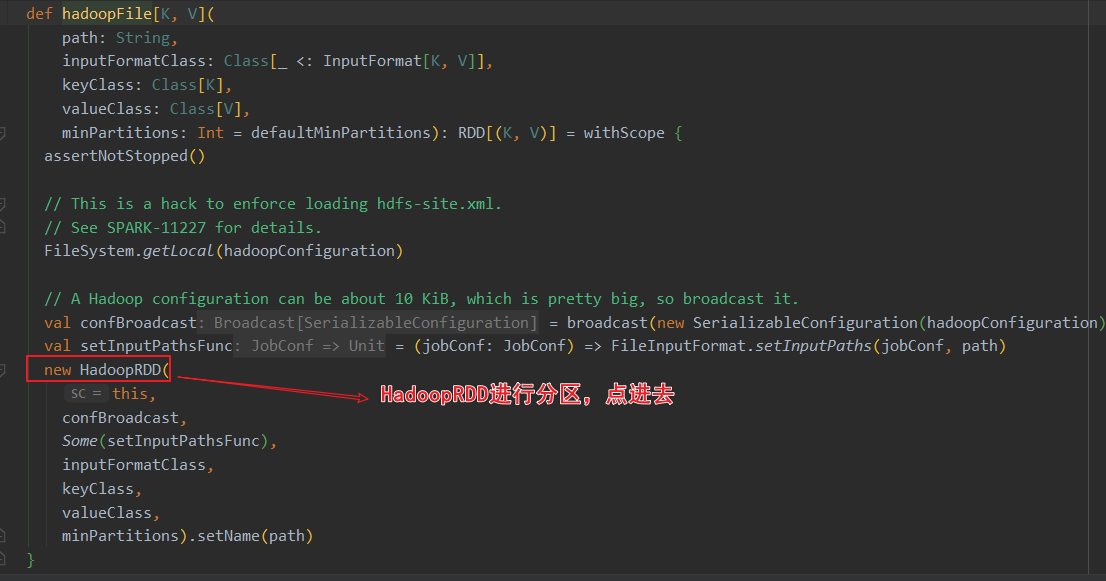
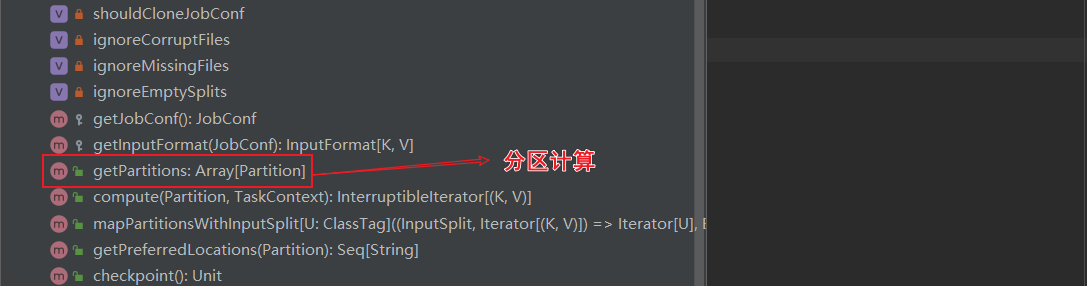
ctrl+F12搜索 HadoopRDD的getPartitions方法,这里进行了分区计算
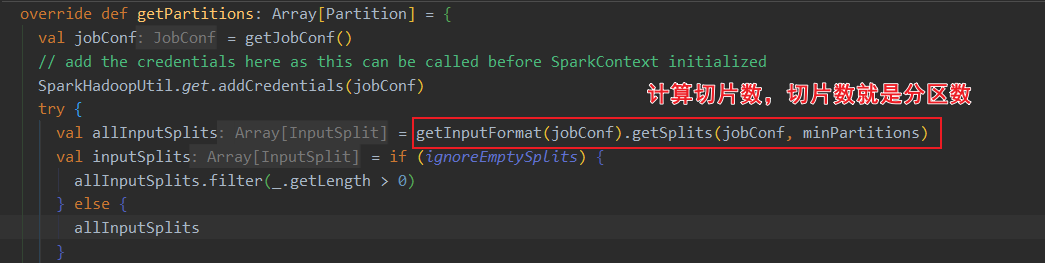
读取的是txt文件,用的是TextInputFormat的切片规则
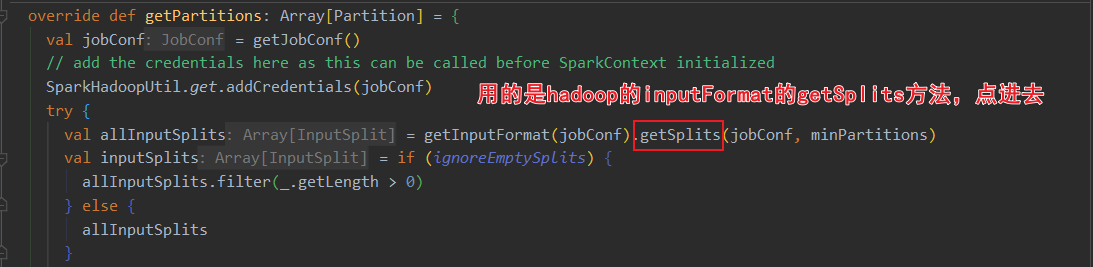
当前spark3.0的HadoopRDD依赖于hadoop的切片规则。其中HadoopRDD用的是旧版hadoop API,还有个NewHadoopRDD用的是新版hadoop API

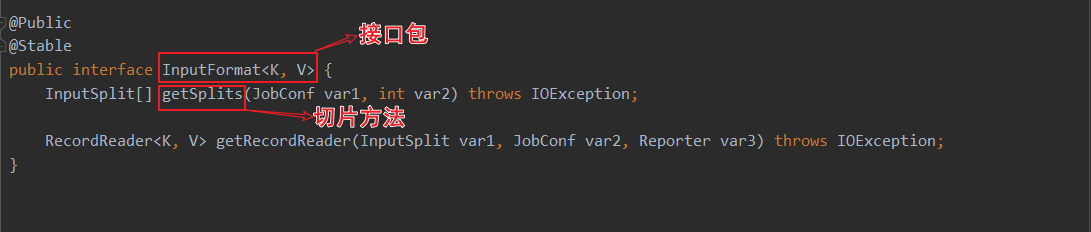
进去TextInputFromat的查看split方法
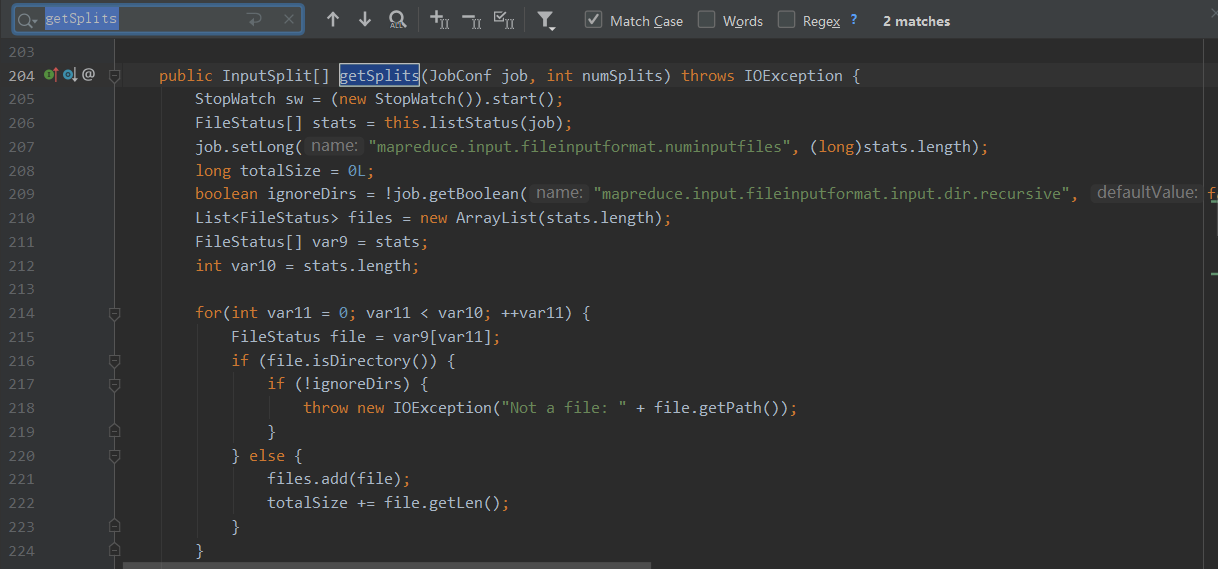
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
// 获取要操作的所有文件的属性信息
FileStatus[] files = listStatus(job);
// 所有文件的总大小
long totalSize = 0; // compute total size
// 目标切片大小 numSplits=defaultMinPartitions
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
//默认为1
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
// 切片是以文件为单位切
for (FileStatus file: files) {
//获取文件大小
long length = file.getLen();
//文件不为空
if (length != 0) {
// 文件是否可切,一般普通文件都可切,如果是压缩格式,只有lzo,Bzip2可切
if (isSplitable(fs, path)) {
// 获取文件的块大小 默认128M
long blockSize = file.getBlockSize();
// 计算片大小
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
// 循环切片,以splitSize为基础进行切片 , 切的片大小,最后一片有可能小于片大小的1.1倍
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
// makeSplit()切片
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
//剩余部分,不够一片,全部作为1片
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
// 文件为空,创建一个空的切片
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits.toArray(new FileSplit[splits.size()]);
}
计算片大小:片大小的计算以所有文件的总大小计算,切片时以文件为单位进行切片。
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
// minSize默认为1
return Math.max(minSize, Math.min(goalSize, blockSize));
}
总结:在大数据的计算领域,一般情况下,块大小就是片大小!
分区数过多,会导致切片大小 < 块大小。
分区数过少,task个数也会少,数据处理效率低,合理设置分区数。
Spark(二)【sc.textfile的分区策略源码分析】的更多相关文章
- RocketMQ中Broker的HA策略源码分析
Broker的HA策略分为两部分①同步元数据②同步消息数据 同步元数据 在Slave启动时,会启动一个定时任务用来从master同步元数据 if (role == BrokerRole.SLAVE) ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- Netty源码分析 (十二)----- 心跳服务之 IdleStateHandler 源码分析
什么是心跳机制? 心跳说的是在客户端和服务端在互相建立ESTABLISH状态的时候,如何通过发送一个最简单的包来保持连接的存活,还有监控另一边服务的可用性等. 心跳包的作用 保活Q:为什么说心跳机制能 ...
- 【一起学源码-微服务】Nexflix Eureka 源码十二:EurekaServer集群模式源码分析
前言 前情回顾 上一讲看了Eureka 注册中心的自我保护机制,以及里面提到的bug问题. 哈哈 转眼间都2020年了,这个系列的文章从12.17 一直写到现在,也是不容易哈,每天持续不断学习,输出博 ...
- Java - "JUC线程池" 线程状态与拒绝策略源码分析
Java多线程系列--“JUC线程池”04之 线程池原理(三) 本章介绍线程池的生命周期.在"Java多线程系列--“基础篇”01之 基本概念"中,我们介绍过,线程有5种状态:新建 ...
- java容器二:List接口实现类源码分析
一.ArrayList 1.存储结构 动态数组elementData transient Object[] elementData; 除此之外还有一些数据 //默认初始容量 private stati ...
- okhttp缓存策略源码分析:put&get方法
对于OkHttp的缓存策略其实就是在下一次请求的时候能节省更加的时间,从而可以更快的展示出数据,那在Okhttp如何使用缓存呢?其实很简单,如下: 配置一个Cache既可,其中接收两个参数:一个是缓存 ...
- 小记--------spark的Master的Application注册机制源码分析及Master的注册机制原理分析
原理图解: Master类位置所在:spark-core_2.11-2.1.0.jar的org.apache.spark.deploy.master下的Master类 //截取了部分代码 //处理 ...
- Spring Ioc源码分析系列--Bean实例化过程(二)
Spring Ioc源码分析系列--Bean实例化过程(二) 前言 上篇文章Spring Ioc源码分析系列--Bean实例化过程(一)简单分析了getBean()方法,还记得分析了什么吗?不记得了才 ...
随机推荐
- 数组中只出现过一次的数字 牛客网 剑指Offer
数组中只出现过一次的数字 牛客网 剑指Offer 题目描述 一个整型数组里除了两个数字之外,其他的数字都出现了偶数次.请写程序找出这两个只出现一次的数字. def FindNumsAppearOnce ...
- SpringCloud微服务实战——搭建企业级开发框架(十二):OpenFeign+Ribbon实现负载均衡
Ribbon是Netflix下的负载均衡项目,它主要实现中间层应用程序的负载均衡.为Ribbon配置服务提供者地址列表后,Ribbon就会基于某种负载均衡算法,自动帮助服务调用者去请求.Ribbo ...
- 20191310Lee_yellow缓冲区溢出实验
缓冲区溢出实验 1.什么是缓冲区溢出 缓冲区溢出是指程序试图向缓冲区写入超出预分配固定长度数据的情况.这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片段.这一漏洞的出现是由于数据 ...
- bootstrap 4 学习笔记
一.button 颜色类 白色:btn 浅蓝色:btn btn-primary 深蓝色:btn btn-info 绿色:btn btn-success 黄色:btn btn-warning 红色:bt ...
- 利用Wireshark 解密HTTPS流量
在我之前的一篇文章中已经介绍了一种解密HTTPS流量的一种方法,大致方法就是客户端手动信任中间人,然后中间人重新封包SSL流量. 文章地址: http://professor.blog.51cto.c ...
- 模块化开发 | es6模块暴露与引入
CommonJS模块开发 CommonJS定义 每个文件就一个模块,有自己的作用域.在一个文件里面定义的变量.函数.类,都是私有的,对其他文件不可见. 私有作用域不会污染全局作用域. 模块可加载多次, ...
- Apache Shiro 反序列化漏洞分析
Shiro550 环境搭建 参考:https://www.cnblogs.com/twosmi1e/p/14279403.html 使用Docker vulhub中的环境 docker cp 将容器内 ...
- S2-001漏洞分析
前言 开始好好学Java,跟着师傅们的文章走一遍 Strust简介 Struts2是流行和成熟的基于MVC设计模式的Web应用程序框架. Struts2不只是Struts1下一个版本,它是一个完全重写 ...
- 【IDEA】IDEA项目没有被SVN管理问题
解决方法 VCS-Enable Version Control Integration
- Python基础(条件判断)
# age = 103 # if age < 90: # print('%s小于90' %age) # elif age > 90 and age < 95: # print('%s ...